centos7安装zookeeper3.4.12集群
zookeeper的三要素:
1、一致,能够保证数据的一致性
2、有头,始终有一个leader,node/2+1个节点有效,就能正常工作
3、数据树,树状结构且每个树必须有数据
1. 环境准备
操作系统:CentOS Linux release 7.2.1511 (Core)
JDK版本:1.8.0_121
具体安装jdk的配置请参见本人的博客https://www.cnblogs.com/lenmom/p/9152947.html中关于jdk安装部分的内容,本文假设jdk已经安装好了
服务器
192.168.1.101;
192.168.1.102;
192.168.1.103;
2. 下载zookeeper
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/

利用wget下载并解压zookeeper3.4.12,当前在192.168.1.101机器上操作
cd /opt/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz #下载zookeeper3.4.12到当前目录
tar -xzvf zookeeper-3.4..tar.gz -C /opt/software #解压zookeeper到当前目录
cd zookeeper-3.4. #进入zookeeper3..12目录
3. 配置zookeeper3.4.12
mv /opt/software/zookeeper-3.4./conf/zoo_sample.cfg /opt/software/zookeeper-3.4./conf/zoo.cfg
vim /opt/software/zookeeper-3.4./conf/zoo.cfg
先把dataDir=/tmp/zookeeper注释,然后将下面四行代码添加到文件末尾,添加以下内容:
dataDir=/opt/software/zookeeper-3.4./data
dataLogDir=/opt/software/zookeeper-3.4./log
server.=192.168.1.101::
server.=192.168.1.102::
server.=192.168.1.103::3888
#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#192.168.1.101为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
zoo.cfg完整的文件内容如下:
# The number of milliseconds of each tick
tickTime= # The number of ticks that the initial
# synchronization phase can take
initLimit= # The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit= # the port at which the clients will connect
clientPort= # the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns= #
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount= # Purge task interval in hours
# Set to "" to disable auto purge feature
#autopurge.purgeInterval= # the directory where the snapshot is stored.
dataDir=/opt/software/zookeeper-3.4./data
dataLogDir=/opt/software/zookeeper-3.4./log
server.=192.168.1.101::
server.=192.168.1.102::
server.=192.168.1.103::
配置文件说明:
#tickTime:
这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit:
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 *= 秒
#syncLimit:
这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*=10秒
#dataDir:
快照日志的存储路径
#dataLogDir:
事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort:
这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。修改他的端口改大点
#autopurge.purgeInterval 这个参数指定了日志清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
#autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。

4.创建myid文件
mkdir -p /opt/software/zookeeper-3.4./data #创建数据目录,该目录在zoo.cfg中配置
cd /opt/software/zookeeper-3.4./data #上面配置的zookeeper数据保存目录
touch myid #创建myid文件
echo "">>myid #往myid中写入1,对应server.X={IP}:: 中的x数字
5. 将上面在192.168.1.101机器上配置好的zookeeper复制到102,103两台机器上去
scp -r /opt/software/zookeeper-3.4./ 192.168.1.102:/opt/software/ #将配置好的zookeeper复制到192.168.1.
scp -r /opt/software/zookeeper-3.4./ 192.168.1.103:/opt/software/ #将配置好的zookeeper复制到192.168.1.
修改102,103机器上/opt/software/zookeeper-3.4.12/data/myid为对应的值
192.168.1.102:
cd /opt/software/zookeeper-3.4./data
rm -f ./myid
echo "2">>myid #往myid中写入2,对应server.X={IP}:: 中的x数字,此处为2
192.168.1.103:
cd /opt/software/zookeeper-3.4./data
rm -f ./myid
echo "">>myid #往myid中写入3,对应server.X={IP}:: 中的x数字,此处为3
6. 开放zookeeper端口
firewall-cmd --zone=public --add-port=/tcp --permanent #添加2888防火墙例外
firewall-cmd --zone=public --add-port=/tcp --permanent #添加3888防火墙例外
firewall-cmd --zone=public --add-port=/tcp --permanent #添加2181防火墙例外
firewall-cmd --reload #重启防火墙
注意:如果所在机器上防火墙没有关闭,上面的操作每天机器都需要做;有些hadoop或CDH集群安装的时候要求把防火墙关闭的,如果已经关闭了防火墙的,可以跳过该步骤,不用执行。
7. 添加环境变量
vim /etc/profile
在文件最后添加:
# zookeeper
export ZK_HOME=/opt/software/zookeeper-3.4.
export PATH=$ZK_HOME/bin:$PATH
使环境变量生效:
source /etc/profile
注意:三台机器都要做这个操作。
8. 启动zookeeper
8.1启动
zkServer.sh start #三台机器都要做此操作,否则通过zkServer.sh status查看启动状态时,
#可能会有Error contacting service. It is probably not running.错误信息。
#具体查看可以在$ZK_HOME/zookeeper.out查看详细的日志信息
8.2 查看状态
zkServer.sh status #查看当前机器的zookeeper状态
192.168.1.101
[root@zoo101 zookeeper-3.4.]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
192.168.1.102
[root@zoo102 zookeeper-3.4.]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: leader
192.168.1.103
[root@zoo103 zookeeper-3.4.]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
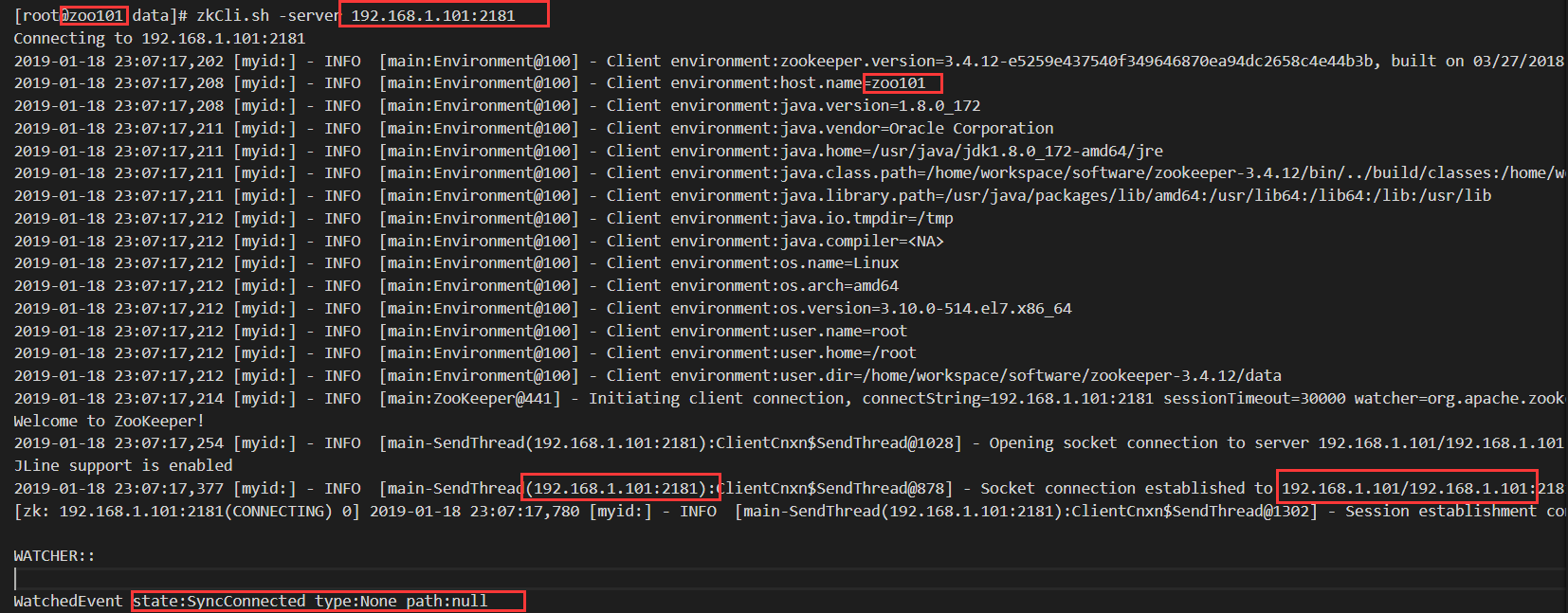
9. 客户端连接zookeeper
zkCli.sh -server 192.168.1.101:
如果出现如下内容,则表明zookeeper已经安装成功
参考:
http://www.cnblogs.com/luotianshuai/p/5206662.html
centos7安装zookeeper3.4.12集群的更多相关文章
- centos7安装zookeeper3.4.9集群
本篇文章目的:以最小成本学习zookeeper的集群安装. zookeeper的三要素: 1.一致,能够保证数据的一致性 2.有头,始终有一个leader,node/2+1个节点有效,就能正常工作 3 ...
- centos7 安装zookeeper3.4.8集群
1.下载上传文件到centos中 2.解压文件夹 3.cd conf 文件下,cp zoo_sample.cfg zoo.cfg 4.vim zoo.cfg # The number of mil ...
- centos7安装redis-4.0.1集群
试验机操作系统:CentOS Linux release 7.2.1511 (Core) 本文的目的是教会大家快速搭建redis集群,完了再深入学习. 试问如果不上手试验,看的资料再多有个毛用? 下载 ...
- Zookeeper(一)CentOS7.5搭建Zookeeper3.4.12集群与命令行操作
一. 分布式安装部署 1.0 下载地址 官网首页: https://zookeeper.apache.org/ 下载地址: http://mirror.bit.edu.cn/apache/zookee ...
- centos7安装elasticsearch6.3.x集群并破解安装x-pack
一.环境信息及安装前准备 主机角色(内存不要小于1G): 软件及版本(百度网盘链接地址和密码:链接: https://pan.baidu.com/s/17bYc8MRw54GWCQCXR6pKjg 提 ...
- CentOS7 安装kylin2.6.0集群
1. 环境准备 zookeeper3.4.12 mysql5.7 hive2.3.4 hadoop2.7.3 JDK1.8 hbase1.3.3 2. 集群规划 ip地址 机器名 角色 192.168 ...
- Centos7 安装部署Kubernetes(k8s)集群
目录 一.系统环境 二.前言 三.Kubernetes 3.1 概述 3.2 Kubernetes 组件 3.2.1 控制平面组件 3.2.2 Node组件 四.安装部署Kubernetes集群 4. ...
- centos7安装redis3.2.5集群
安装参照 https://blog.csdn.net/mingliangniwo/article/details/54600640 https://blog.csdn.net/u013820 ...
- Centos7安装升级Ruby和集群搭建参考
安装升级Ruby参考:https://blog.csdn.net/qq_26440803/article/details/82717244 集群搭建参考:https://www.cnblogs.com ...
随机推荐
- vm centos7中用NAT模式配置上网
第一步:设置虚拟机的NAT相关网络设置: 点击5标致处的“NAT设置”会出现设置6标致处的网关. 第二部:设置操作系统网络设置,右击上图中9标致处的系统,点击设置 第三部:配置操作系统ip ...
- 机器学习 - 开发环境安装pycharm + pyspark + spark集成篇
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈) 数据量大了,就需要用到其他技术了,如:spa ...
- 修改.net core 运行端口
ASPNETCORE_URLS environment variable is ignored by "dotnet run" dotnet new web set ASPNETC ...
- js调用.net后台事件,和后台调用前台等方法总结(转帖)
js调用.net后台事件,和后台调用前台等方法总结 原文来自:http://hi.baidu.com/xiaowei0705/blog/item/4d56163f5e4bf616bba16725.ht ...
- java 多线程详解
一.重点 重点: 1.创建和启动线程 2.实现线程调度 3.实现线程同步 4.实现线程通信 1.为什么要学习多线程? 当多个人访问电脑上同一资源的时候,要用到多线程,让每个人感觉很多电脑同时为多个人服 ...
- Vivado HLS初识---阅读《vivado design suite tutorial-high-level synthesis》(2)
Vivado HLS初识---阅读<vivado design suite tutorial-high-level synthesis>(2) 1.实验目的 2.启动命令行 将命令行切换 ...
- sql server 拼接字段
方式一: --select @p_AllPARTOFCHECK = (select CAST(t.PARTOFCHECK as varchar)+'|' from QUEUEDETAIL t wher ...
- ie8 报错:意外地调用了方法或属性访问
在某场景中一句简单的js: $("#changeOption").text("增加"); 在 IE8 下面报错:'意外地调用了方法或属性访问' 改成:$(&qu ...
- postgresql 查看数据库,表,索引,表空间以及大小
转载 http://blog.51yip.com/pgsql/1525.html 1,查看数据库 playboy=> \l //\加上字母l,相当于mysql的,mysql> show d ...
- elasticsearch 口水篇(3)java客户端 - Jest
elasticsearch有丰富的客户端,java客户端有Jest.其原文介绍如下: Jest is a Java HTTP Rest client for ElasticSearch.It is a ...