hadoop hdfs 元数据 journalnode editslog fsimage
先上图,文章以后再上
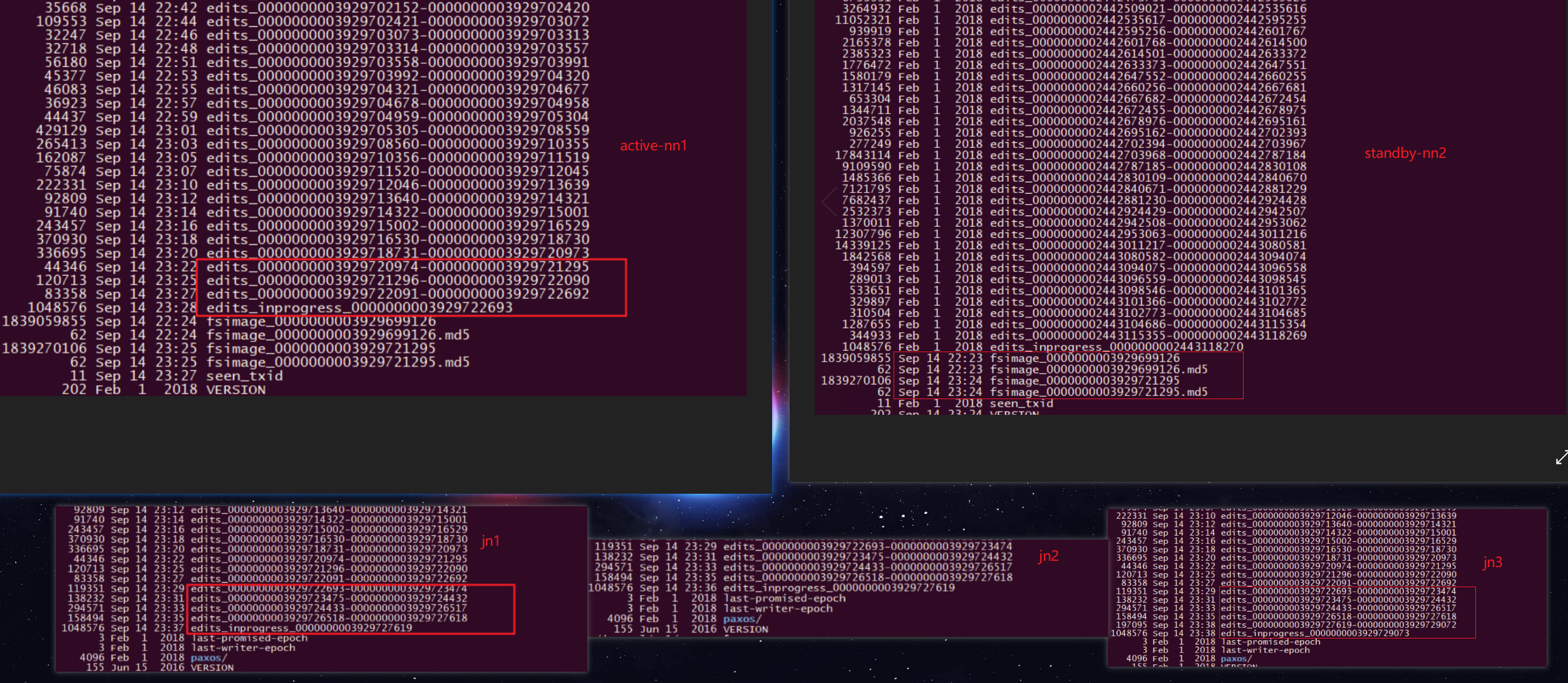
截图有先后 所以有些延迟,但是不耽误总体的理解(active-nn=a-nn=active-namenode; s-nn=standby-nn=standby-namenode; journalnode=jn;edits_log=elog ; fsimage=fsg )
一般认为journalnode有2n+1台,如果大于等于n+1台成功写入,就算写入jn成功。
standby-nn 会定时拉取3台jn节点(假设有3台jn)的edits_log(只拉取处于finalized状态的edits_log,in-progress并不会拉取因为他可能会改变),再与本地的fsimage元数据镜像文件做merge操作( s-nn 并不会同时把edits_log 写入到本地磁盘上。下图中磁盘有edits_log是因为他之前是active-nn(从最后修改时间也可以看出来)。合并操作是在standby-nn内存中完成,完成后会落地新fsimage文件如下图)。
当standby-nn merge完毕后,旧的fsimage不会立即删除而会保留一段时间等待被roll掉,当然版本号会比新merge的fsimage要小。与此同时standby-nn会把新merge的镜像文件推给active-nn ,active-nn旧的镜像也不会立即删除,也是等待被roll掉,新推过来的fsimage镜像也是要比旧的镜像编号要大。
注意:s-nn会比a-nn少一些元数据信息(少的是s-nn在拉取elog时处于in-progress的日志),所以当a-nn宕机或处于非健康状态时,s-nn在切换成a-nn之前要重新拉取大于本地fsg号的elog文件做merge操作,这样s-nn才是最新的元数据,可以切换成a-nn了。
(TODO:这里有个疑问,就是a-nn处于异常状态的那一刻会有elog处于in-progress,a-nn来不及处理这部分elog(比如a-nn突然宕机),s-nn是如何处理这部分elog的)
问题:主备切换时,s-nn从jn获取最新elog,在内存中回放(这时合并的最新fsimage会不会落地),目前看现象是不会落地(需看源码确认)
更多细节会贴源码介绍
hadoop hdfs 元数据 journalnode editslog fsimage的更多相关文章
- Hadoop HDFS元数据目录分析
元数据目录分析 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘: $HADOOP_HOME/bin/hdfs namenode -format 格式化完成之后 ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- hadoop hdfs 高可用
单点故障: 如果某一个节点或服务出了问题,导致服务不可用 单点故障解决方式: 1.给容易出故障的地方安排备份 2.一主一备,要求同一时刻只能有一个对外提供服务 3.当active挂掉之后,standb ...
- hadoop hdfs ha 模式
这是我自己在公司一个搭建公司大数据框架是自己的选项,在配置yarn ha 出现了nodemanager起不来的问题于是我把yarn搭建为普通yarn 如果有人解决 高yarn的nodemanager问 ...
- Hadoop基础-镜像文件(fsimage)和编辑日志(edits)
Hadoop基础-镜像文件(fsimage)和编辑日志(edits) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看日志镜像文件(如:fsimage_00000000000 ...
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- Hadoop — HDFS的概念、原理及基本操作
1. HDFS的基本概念和特性 设计思想——分而治之:将大文件.大批量文件分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析.在大数据系统中作用:为各类分布式运算框架(如:map ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
随机推荐
- SQL Server CONVERT() 日期转换为新数据类型的 通用函数
http://www.w3school.com.cn/sql/func_convert.asp
- ThreadPoolExecutor简单学习
Executors和ThreadPoolExecutor两者的区别和联系 jdk中文文档 https://blog.fondme.cn/apidoc/jdk-1.8-google/ 还可以的两个博客 ...
- PyQt—QTableWidget中的checkBox状态判断
一.QTableWidget实现checkBox效果 利用QTableWidgetItem对象的CheckState属性,既能显示QCheckBox,又能读取状态 table = QtGui.QTab ...
- [Android 开发教程(1)]-- Saving Data in SQL Databases
Saving data to a database is ideal for repeating or structured data, such as contact information. Th ...
- PHP7.1扩展开发入门
第1步: 首先从官网下载了PHP源码http://am1.php.net/distributions/php-7.1.3.tar.bz2 第2步: 解压后可以看到根目录下面的ext文件夹里有ext_s ...
- HDOJ 2007 平方和与立方和
#include<iostream> #include<algorithm> using namespace std; int main() { int m, n; while ...
- git基本的使用原理
一:Git是什么? Git是目前世界上最先进的分布式版本控制系统. 二:SVN与Git的最主要的区别? SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以 ...
- Redis登陆服务器和批量删除指定的key
ps -ef |grep redis cd /opt/app/redis/bin ./redis-cli -h 192.168.0.67 -p 7001 -a 'hub2c!Redis'./redis ...
- Android拨打接听电话自动免提
权限: <uses-permission android:name="android.permission.READ_PHONE_STATE"/> <uses-p ...
- restful 涵义
REST,即Representational State Transfer的缩写: "表现层状态转化" REST的名称"表现层状态转化"中,省略了主语.&quo ...