MSSQL · 最佳实践 · 利用文件组实现冷热数据隔离备份方案
文件组的基本知识点介绍完毕后,根据场景引入中的内容,我们将利用SQL Server文件组技术来实现冷热数据隔离备份的方案设计介绍如下。
设计分析
由于payment数据库过大,超过10TB,单次全量备份超过20小时,如果按照常规的完全备份,会导致备份文件过大、耗时过长、甚至会因为备份操作对I/O能力的消耗影响到正常业务。我们仔细想想会发现,虽然数据库本身很大,但是,由于只有当前年表数据会不断变化(热数据),历史年表数据不会修改(冷数据),因此正真有数据变化操作的数据量相对整个库来看并不大。那么,我们将数据库设计为历史年表数据放到Read only的文件组上,把当前年表数据放到Read write的文件组上,备份系统仅仅需要备份Primary和当前年表所在的文件组即可(当然首次还是需要对数据库做一次性完整备份的)。这样既可以大大节约备份对I/O能力的消耗,又实现了冷热数据的隔离备份操作,还达到了分散了文件的I/O压力,最终达到数据库设计和备份系统优化的目的,可谓一箭多雕。
以上文字分析,画一个漂亮的设计图出来,直观展示如下: 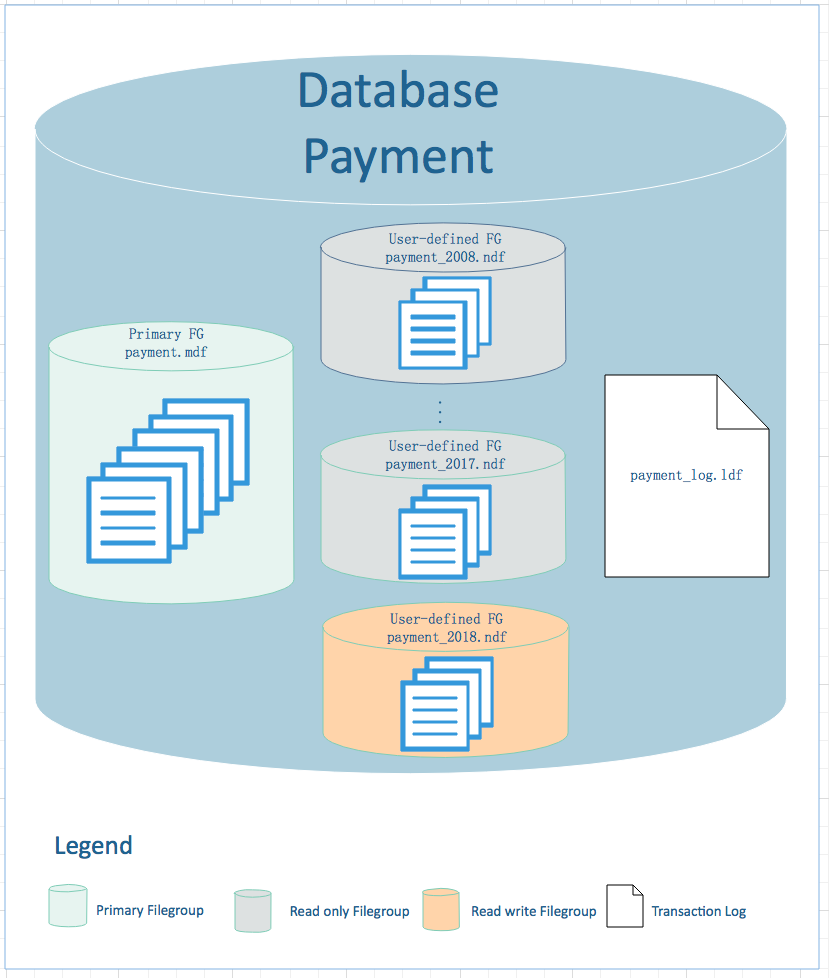
设计图说明
以下对设计图做详细说明,以便对设计方案有更加直观和深入理解。 整个数据库包含13个文件,包括:
1个主文件组(Primary File Group):用户存放数据库系统表、视图等对象信息,文件组可读可写。
10个用户自定义只读文件组(User-defined Read Only File Group):用于存放历史年表的数据及相应索引数据,每一年的数据存放到一个文件组中。
1个用户自定义可读写文件组(User-defined Read Write File Group):用于存放当前年表数据和相应索引数据,该表数据必须可读可写,所以文件组必须可读可写。
1个数据库事务日志文件:用于数据库事务日志,我们需要定期备份数据库事务日志。
方案实现
设计方案完成以后,接下来就是方案的集体实现了,具体实现包括:
创建数据库
创建年表
文件组设置
冷热备份实现
创建数据库
创建数据库的同时,我们创建了Primary文件组和2008 ~ 2017的文件组,这里需要特别提醒,请务必保证所有文件组中文件的初始大小和增长量相同,代码如下:
USE master
GO
EXEC sys.xp_create_subdir 'C:\DATA\Payment\Data\'
EXEC sys.xp_create_subdir 'C:\DATA\Payment\Log\'
CREATE DATABASE [Payment]
ON PRIMARY
( NAME = N'Payment', FILENAME = N'C:\DATA\Payment\Data\Payment.mdf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2008]
( NAME = N'FGPayment2008', FILENAME = N'C:\DATA\Payment\Data\Payment_2008.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2009]
( NAME = N'FGPayment2009', FILENAME = N'C:\DATA\Payment\Data\Payment_2009.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2010]
( NAME = N'FGPayment2010', FILENAME = N'C:\DATA\Payment\Data\Payment_2010.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2011]
( NAME = N'FGPayment2011', FILENAME = N'C:\DATA\Payment\Data\Payment_2011.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2012]
( NAME = N'FGPayment2012', FILENAME = N'C:\DATA\Payment\Data\Payment_2012.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2013]
( NAME = N'FGPayment2013', FILENAME = N'C:\DATA\Payment\Data\Payment_2013.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2014]
( NAME = N'FGPayment2014', FILENAME = N'C:\DATA\Payment\Data\Payment_2014.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2015]
( NAME = N'FGPayment2015', FILENAME = N'C:\DATA\Payment\Data\Payment_2015.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2016]
( NAME = N'FGPayment2016', FILENAME = N'C:\DATA\Payment\Data\Payment_2016.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),
FILEGROUP [FGPayment2017]
( NAME = N'FGPayment2017', FILENAME = N'C:\DATA\Payment\Data\Payment_2017.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB )
LOG ON
( NAME = N'Payment_log', FILENAME = N'C:\DATA\Payment\Log\Payment_log.ldf' , SIZE = 5MB , FILEGROWTH = 50MB)
GO
考虑到每年我们都要添加新的文件组到数据库中,因此2018年的文件组单独创建如下:
--Add filegroup FGPayment2018
USE master
GO
ALTER DATABASE [Payment] ADD FILEGROUP [FGPayment2018];
-- Add data file to FGPayment2018
ALTER DATABASE [Payment]
ADD FILE (NAME = FGPayment2018, SIZE = 5MB , FILEGROWTH = 50MB ,FILENAME = N'C:\DATA\Payment\Data\Payment_2018.ndf')
TO FILEGROUP [FGPayment2018]
GO
最终再次确认数据库文件组信息,代码如下:
USE [Payment]
GO
SELECT file_name = mf.name, filegroup_name = fg.name, mf.physical_name,mf.size,mf.growth
FROM sys.master_files AS mf
INNER JOIN sys.filegroups as fg
ON mf.data_space_id = fg.data_space_id
WHERE mf.database_id = db_id('Payment')
ORDER BY mf.type;
结果展示如下图所示: 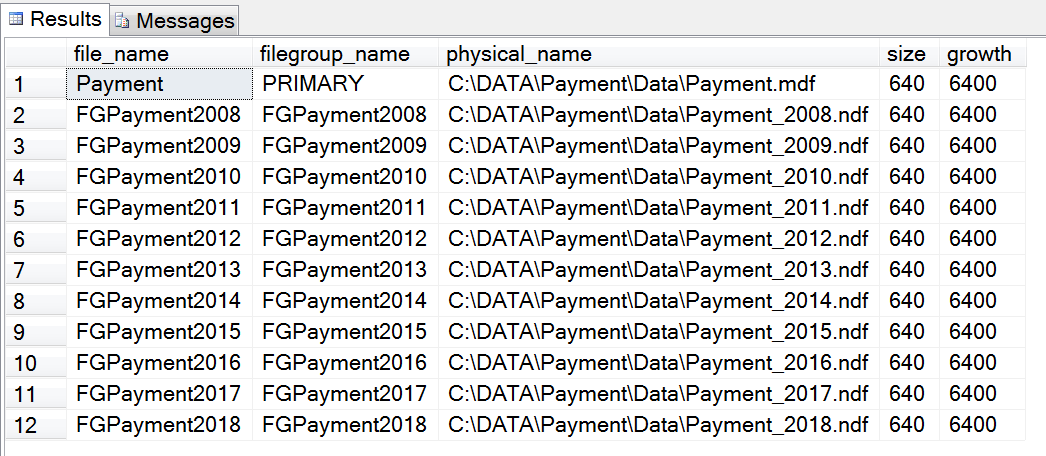
创建年表
数据库以及相应文件组创建完毕后,接下来我们创建对应的年表并插入一些测试数据,如下:
USE [Payment]
GO
CREATE TABLE [dbo].[Payment_2008](
[Payment_ID] [bigint] IDENTITY(12008,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2008] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2008]
) ON [FGPayment2008]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2008] ([OrderID])
ON [FGPayment2008];
CREATE TABLE [dbo].[Payment_2009](
[Payment_ID] [bigint] IDENTITY(12009,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2009] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2009]
) ON [FGPayment2009]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2009] ([OrderID])
ON [FGPayment2009];
--这里省略了2010-2017的表创建,请参照以上建表和索引代码,自行补充
CREATE TABLE [dbo].[Payment_2018](
[Payment_ID] [bigint] IDENTITY(12018,100) NOT NULL,
[OrderID] [bigint] NOT NULL,
CONSTRAINT [PK_Payment_2018] PRIMARY KEY CLUSTERED
(
[Payment_ID] ASC
) ON [FGPayment2018]
) ON [FGPayment2018]
GO
CREATE NONCLUSTERED INDEX IX_OrderID
ON [dbo].[Payment_2018] ([OrderID])
ON [FGPayment2018];
这里需要特别提醒两点:
限于篇幅,建表代码中省略了2010 - 2017表创建,请自行补充
每个年表的Payment_ID字段初始值是不一样的,以免查询所有payment信息该字段值存在重复的情况
其次,我们检查所有年表的文件组分布情况如下:
USE [Payment]
GO
SELECT table_name = tb.[name], index_name = ix.[name], located_filegroup_name = fg.[name]
FROM sys.indexes ix
INNER JOIN sys.filegroups fg
ON ix.data_space_id = fg.data_space_id
INNER JOIN sys.tables tb
ON ix.[object_id] = tb.[object_id]
WHERE ix.data_space_id = fg.data_space_id
GO
查询结果截取其中部分如下,我们看到所有年表及索引都按照我们的预期分布到对应的文件组上去了。 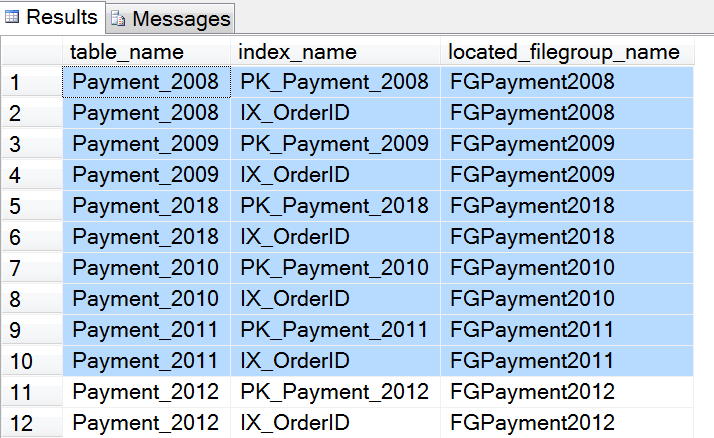
最后,为了测试,我们在对应年表中放入一些数据:
USE [Payment]
GO
SET NOCOUNT ON
INSERT INTO [Payment_2008] SELECT 2008;
INSERT INTO [Payment_2009] SELECT 2009;
--省略掉2010 - 2017,自行补充
INSERT INTO [Payment_2018] SELECT 2018;
文件组设置
年表创建完完毕、测试数据初始化完成后,接下来,我们做文件组读写属性的设置,代码如下:
USE master
GO
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2008] READ_ONLY;
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2009] READ_ONLY;
--这里省略了2010 - 2017文件组read only属性的设置,请自行补充
ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2018] READ_WRITE;
最终我们的文件组读写属性如下:
USE [Payment]
GO
SELECT name, is_default, is_read_only FROM sys.filegroups
GO
截图如下:
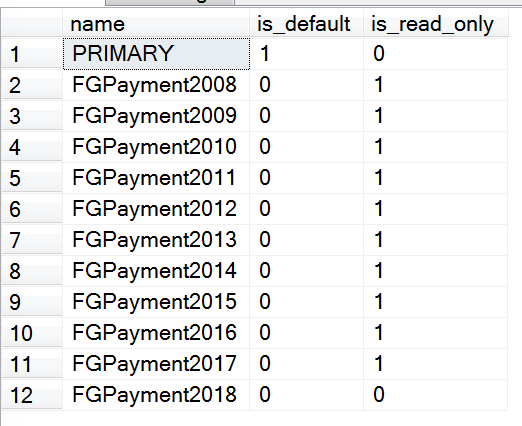
冷热备份实现
所有文件组创建成功,并且读写属性配置完毕后,我们需要对数据库可读写文件组进行全量备份、差异备份和数据库级别的日志备份,为了方便测试,我们会在两次备份之间插入一条数据。备份操作的大体思路是:
首先,对整个数据库进行一次性全量备份
其次,对可读写文件组进行周期性全量备份
接下来,对可读写文件组进行周期性差异备份
最后,对整个数据库进行周期性事务日志备份
--Take a one time full backup of payment database
USE [master];
GO
BACKUP DATABASE [Payment]
TO DISK = N'C:\DATA\Payment\BACKUP\Payment_20180316_full.bak'
WITH COMPRESSION, Stats=5
;
GO
-- for testing, init one record
USE [Payment];
GO
INSERT INTO [dbo].[Payment_2018] SELECT 201801;
GO
--Take a full backup for each writable filegoup (just backup FGPayment2018 as an example)
BACKUP DATABASE [Payment]
FILEGROUP = 'FGPayment2018'
TO DISK = 'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_full.bak'
WITH COMPRESSION, Stats=5
;
GO
-- for testing, insert one record
INSERT INTO [dbo].[Payment_2018] SELECT 201802;
GO
--Take a differential backup for each writable filegoup (just backup FGPayment2018 as an example)
BACKUP DATABASE [Payment]
FILEGROUP = N'FGPayment2018'
TO DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_diff.bak'
WITH DIFFERENTIAL, COMPRESSION, Stats=5
;
GO
-- for testing, insert one record
INSERT INTO [dbo].[Payment_2018] SELECT 201803;
GO
-- Take a transaction log backup of database payment
BACKUP LOG [Payment]
TO DISK = 'C:\DATA\Payment\BACKUP\Payment_20180316_log.trn';
GO
这样备份的好处是,我们只需要对可读写的文件组(FGPayment2018)进行完整和差异备份(Primary中包含系统对象,变化很小,实际场景中,Primary文件组也需要备份),而其他的9个只读文件组无需备份,因为数据不会再变化。如此,我们就实现了冷热数据隔离备份的方案。 接下来的一个问题是,万一Payment数据发生灾难,导致数据损失,我们如何从备份集中将数据库恢复出来呢?我们可以按照如下思路来恢复备份集:
首先,还原整个数据库的一次性全量备份
其次,还原所有可读写文件组最后一个全量备份
接下来,还原可读写文件组最后一个差异备份
最后,还原整个数据库的所有事务日志备份
-- We restore full backup
USE master
GO
RESTORE DATABASE [Payment_Dev]
FROM DISK=N'C:\DATA\Payment\BACKUP\Payment_20180316_full.bak' WITH
MOVE 'Payment' TO 'C:\DATA\Payment_Dev\Data\Payment_dev.mdf',
MOVE 'FGPayment2008' TO 'C:\DATA\Payment_Dev\Data\FGPayment2008_dev.ndf',
MOVE 'FGPayment2009' TO 'C:\DATA\Payment_Dev\Data\FGPayment2009_dev.ndf',
MOVE 'FGPayment2010' TO 'C:\DATA\Payment_Dev\Data\FGPayment2010_dev.ndf',
MOVE 'FGPayment2011' TO 'C:\DATA\Payment_Dev\Data\FGPayment2011_dev.ndf',
MOVE 'FGPayment2012' TO 'C:\DATA\Payment_Dev\Data\FGPayment2012_dev.ndf',
MOVE 'FGPayment2013' TO 'C:\DATA\Payment_Dev\Data\FGPayment2013_dev.ndf',
MOVE 'FGPayment2014' TO 'C:\DATA\Payment_Dev\Data\FGPayment2014_dev.ndf',
MOVE 'FGPayment2015' TO 'C:\DATA\Payment_Dev\Data\FGPayment2015_dev.ndf',
MOVE 'FGPayment2016' TO 'C:\DATA\Payment_Dev\Data\FGPayment2016_dev.ndf',
MOVE 'FGPayment2017' TO 'C:\DATA\Payment_Dev\Data\FGPayment2017_dev.ndf',
MOVE 'FGPayment2018' TO 'C:\DATA\Payment_Dev\Data\FGPayment2018_dev.ndf',
MOVE 'Payment_log' TO 'C:\DATA\Payment_Dev\Log\Payment_dev_log.ldf',
NORECOVERY,STATS=5;
GO
-- restore writable filegroup full backup
RESTORE DATABASE [Payment_Dev]
FILEGROUP = N'FGPayment2018'
FROM DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_full.bak'
WITH NORECOVERY,STATS=5;
GO
-- restore writable filegroup differential backup
RESTORE DATABASE [Payment_Dev]
FILEGROUP = N'FGPayment2018'
FROM DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_diff.bak'
WITH NORECOVERY,STATS=5;
GO
-- restore payment database transaction log backup
RESTORE LOG [Payment_Dev]
FROM DISK = N'C:\DATA\Payment\BACKUP\\Payment_20180316_log.trn'
WITH NORECOVERY;
GO
-- Take database oneline to check
RESTORE DATABASE [Payment_Dev] WITH RECOVERY;
GO
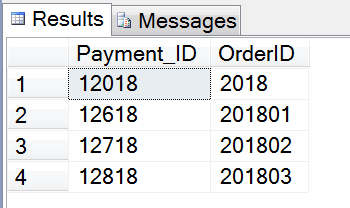
最后检查数据还原的结果,按照我们插入的测试数据,应该会有四条记录。
USE [Payment_Dev]
GO
SELECT * FROM [dbo].[Payment_2018] WITH(NOLOCK)
展示执行结果,有四条结果集,符合我们的预期,截图如下:
最后总结
本篇月报分享了如何利用SQL Server文件组技术来实现和优化冷热数据隔离备份的方案,在大大提升数据库备份还原效率的同时,还提供了I/O资源的负载均衡,提升和优化了整个数据库的性能。
MSSQL · 最佳实践 · 利用文件组实现冷热数据隔离备份方案的更多相关文章
- MSSQL - 最佳实践 - 使用SSL加密连接
MSSQL - 最佳实践 - 使用SSL加密连接 author: 风移 摘要 在SQL Server安全系列专题月报分享中,往期我们已经陆续分享了:如何使用对称密钥实现SQL Server列加密技术. ...
- Web前端开发最佳实践(7):使用合理的技术方案来构建小图标
大家都对网站上使用的小图标肯定都不陌生,这些小图标作为网站内容的点缀,增加了网站的美观度,提高了用户体验,可是你有没有看过在这些网站中使用的图标都是用什么技术实现的?虽然大部分网站还是使用普通的图片实 ...
- SQL Server 2008文件与文件组的关系
此文章主要向大家讲述的是SQL Server 2008文件与文件组,其中包括文件和文件组的含义与关系,文件.文件组在实践应用中经常出现的问题,查询文件组和文件语句与MSDN官方解释等相关内容的介绍. ...
- SQLServer · 最佳实践 · 透明数据加密TDE在SQLServer的应用
转:https://yq.aliyun.com/articles/42270 title: SQLServer · 最佳实践 · 透明数据加密TDE在SQLServer的应用 author: 石沫 背 ...
- Web前端开发最佳实践(1):前端开发概述
引言 我从07年开始进入博客园,从最开始阅读别人的文章到自己开始尝试表达一些自己对技术的看法.可以说,博客园是我参与技术讨论的一个主要的平台.在这其间,随着接触技术的广度和深度的增加,也写了一些得到了 ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server架构 -- 数据库文件和文件组
在SQL SERVER中,数据库在硬盘上的存储方式和普通文件在Windows中的存储方式没有什么不同,也是在特定文件夹下创建不同的文件,然后经过文件存储系统去抓取数据信息.理解文件和文件组的概念可以帮 ...
- 关于SQL Server中分区表的文件与文件组的删除(转)
在SQL Server中对表进行分区管理时,必定涉及到文件与文件组,关于文件与文件组如何创建在网上资料很多,我博客里也有两篇相关转载文件,可以看看,我这就不再细述,这里主要讲几个一般网上很少讲到的东西 ...
随机推荐
- 【详解】ThreadPoolExecutor源码阅读(三)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) 线程数量的 ...
- linux下的重命名
mv oldname newname 显然,移动命令可以实现重命名. 而rename命令通常用于批量文件的重命名.
- Maven的默认中央仓库
当构建一个Maven项目时,首先检查pom.xml文件以确定依赖包的下载位置,执行顺序如下: 1.从本地资源库中查找并获得依赖包,如果没有,执行第2步. 2.从Maven默认中央仓库中查找并获得依赖包 ...
- spring StopWatch用法
背景 有时我们在做开发的时候需要记录每个任务执行时间,或者记录一段代码执行时间,最简单的方法就是打印当前时间与执行完时间的差值,然后这样如果执行大量测试的话就很麻烦,并且不直观,如果想对执行的时间做进 ...
- 根据ip获取地点
#region 根据ip获取地点 /// 获取Ip归属地 /// </summary> /// <param name="ip">ip</param& ...
- C#调用百度地图API经验分享(三)
这一篇我将跟大家分享一下我自己在开发过程中总结出的一些操作地图的方法,属性,及思路,希望可以让大家少走弯路. 1.定位 一般百度的示例DEMO里开始初始化地图时用的都是map.centerAndZoo ...
- Linux-mkdosfs格式化磁盘命令(15)
名称:mkdosfs 使用:mkdosfs [块设备名称] 说明: 将一个块设备格式化为DOS磁盘类型 例: mkdosfs /dev/memblock //将memblock块设备格式化为dos磁盘 ...
- Open Credit System(UVA11078)
11078 - Open Credit System Time limit: 3.000 seconds Problem E Open Credit System Input: Standard In ...
- Android-加载图片避免OOM
http://blog.csdn.net/guolin_blog/article/details/9316683 高效加载大图片 我们在编写Android程序的时候经常要用到许多图片,不同图片总是会有 ...
- python学习之老男孩python全栈第九期_day008作业
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数,求出本次购物花费的总钱数apple 10 3tesla 100000 1mac 3000 2lenovo 30000 3chicken ...