自动发现项目中的所有URL
我的rbac组件,是想用到任何一个,项目中的。 so 问题来了。
- 问题: 拿到一个项目。 怎样获取到,当前项目中, 所有的URL 以及 每个URL的别名name, 还有是有 namespace 命名空间。
- 实现思路:
1. 先要确定我们 根级 路由在哪里。 就是和项目文件同名的包中, 的 urls.py 中的 urlpatterns=[....] 这个路由的位置在我们的settings中是有进行配置的
ROOT_URLCONF = 'learn_formset.urls' 当然这个是可以进行修改的。
那个怎么才能获得,这个 urlpatterns 列表中的所有的对象呢?
直接导入的话,也是可以的。 但是更好的是 通过settings 中 ROOT_URLCONF 的字符串来进行导入。
Django中有一个模块就是来做这件事的, from django.utils.module_loading import import_string 这个模块就是用来根据一个字符串来导入相应的模块。
他的返回值,就是一个模块对象 <class 'module'> 。 可以通过 点 语法。获取到其中的 urlpatterns 列表。
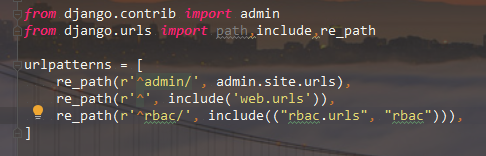
看一看,打印 urlpatterns 里面的没一个数据, 能得到啥:
from django.conf import settings
from django.utils.module_loading import import_string def get_all_url_dict():
'''
递归获取项目中,所有的url 保存到字典
:return:
'''
md = import_string(settings.ROOT_URLCONF) # <class 'module'>
for item in md.urlpatterns:
print(item) # <URLResolver <URLPattern list> (admin:admin) '^admin/'> # <URLResolver <module 'web.urls' from 'D:\\crm_learn\\web\\urls.py'> (None:None) '^'> # <URLResolver <module 'rbac.urls' from 'D:\\crm_learn\\rbac\\urls.py'> (rbac:rbac) '^rbac/'> def multi_permissions(request):
'''
批量操作权限
:param request:
:return:
'''
# 获取项目中,所有的URL
get_all_url_dict()
return HttpResponse("OK")
可以看到的是,每一个item 都是一个 URLResolver 对象。这表示这是一个 路由分发的url。
但是 还有一种是 对应的视图函数的。URLPattern 对象。表示他对应的是一个 视图函数。
看代码吧! 这是 Django 2.0 版本的。 和 1 版本有不小的改动。
from collections import OrderedDict
from django.conf import settings
from django.utils.module_loading import import_string
from django.urls.resolvers import URLResolver, URLPattern def check_url_exclude(url):
'''自定制,过滤一下。 以 xxx 为前缀的 url'''
exclude_url = [
"/admin/.*",
"/login/",
]
for regex in exclude_url:
if re.match(regex, url):
return True def recursion_urls(pre_namespace, pre_url, urlpatterns, url_ordered_dict):
'''
递归获取,所有的url
:param pre_namespace: namespace前缀,用于拼接name (namespace:name)
:param pre_url: url的前缀, 用于拼接url
:param urlpatterns: 路由关系列表
:param url_ordered_dict: 用于保存递归中获取的所有的路由
:return:
'''
for item in urlpatterns:
if isinstance(item, URLPattern): # 表示一个 非路由分发。将路由添加到字典中
if not item.name: # 判断这个url 有没有,name别名
continue
name = item.name
if pre_namespace: # 判断当前这个url是不是有namespace前缀。也就是:是否是某一个命名空间中的 name别名
name = "%s:%s" % (pre_namespace, item.name)
url = (pre_url + str(item.pattern)).replace("^", "").replace("$", "")
if check_url_exclude(url): # 在这里进行自定制的过滤。 过露出我不想要的 哪些url
continue
url_ordered_dict[name] = {"name": name, "url": url} elif isinstance(item, URLResolver): # 表示这是一个路由分发。 这里就需要递归了
namespace = pre_namespace
if pre_namespace: # 如果有前缀
if item.namespace: # 自己有没有namespace
namespace = "%s:%s" % (pre_namespace, item.namespace)# 把之前的pre_namespace 和当前的 item.namespace 拼接。 传给下一次的递归函数。继续进行拼接
else:
if item.namespace:
namespace = item.namespace
recursion_urls(namespace, pre_url + str(item.pattern), item.url_patterns, url_ordered_dict)
# 进入下一次循环之前,pre_url + str(item.pattern) 要拼接上这一次循环的 url。
# item.url_patterns这一次是 URLResolver 对象的 url_patterns。 中间要加一个 _ 烦得很。 第一次是通过导入拿到的 模块对象。
# 但是 递归中的不是 模块对象。是一个URLResolver对象。 所以要加一个 _ 。下划线 def get_all_url_dict():
'''
获取项目中,所有的url 保存到字典(前提是,每个url必须有name别名)
:return:
'''
url_ordered_dict = OrderedDict()
md = import_string(settings.ROOT_URLCONF) recursion_urls(None, "/", md.urlpatterns, url_ordered_dict)
# 递归的去获取所有的路由。
# 第一次循环时,肯定是从 根路由开始, 所以没有前缀 传一个None.
# "/" 也是因为,第一次循环时。 所有的url 都没有前导 的 "/" 手动的加上。
# md.urlpatterns 要循环的这个列表。
# url_ordered_dict 保存所有url 的字典。
return url_ordered_dict def multi_permissions(request):
'''
批量操作权限
:param request:
:return:
'''
# 获取项目中,所有的URL
all_url_dict = get_all_url_dict()
print(all_url_dict)
return HttpResponse("OK")
这里是1.0版本的。 主要是,几个关键的参数获取的位置上。 有些不同!
from collections import OrderedDict
from django.conf import settings
from django.utils.module_loading import import_string
from django.urls.resolvers import RegexURLResolver, RegexURLPattern def recursion_urls(pre_namespace, pre_url, urlpatterns, url_ordered_dict):
for item in urlpatterns:
if isinstance(item, RegexURLPattern): # 表示一个 非路由分发。将路由添加到字典中
if not item.name: # 判断这个url 有没有,name别名
continue if pre_namespace: # 判断当前这个url是不是有namespace前缀。如果有就说明是通过路由分发过来的,
# 就要加上, 他上级的名称空间
name = "%s:%s" % (pre_namespace, item.name)
else:
name = item.name
url = pre_url + str(item._regex)
url_ordered_dict[name] = {"name": name, "url": url.replace("^", "").replace("$", "")} elif isinstance(item, RegexURLResolver): # 表示这是一个路由分发。 这里就需要递归了
if pre_namespace: # 如果有前缀
if item.namespace: # 自己有没有namespace
namespace = "%s:%s" % (pre_namespace, item.namespace)
else:
namespace = pre_namespace
# 把之前的pre_namespace 和当前的 item.namespace 拼接。 传给下一次的递归函数。继续进行拼接
else:
if item.namespace:
namespace = item.namespace
else:
namespace = None
recursion_urls(namespace, pre_url + str(item._regex.pattern), item.url_patterns, url_ordered_dict) def get_all_url_dict():
url_ordered_dict = OrderedDict()
md = import_string(settings.ROOT_URLCONF) recursion_urls(None, "/", md.urlpatterns, url_ordered_dict)
return url_ordered_dict def multi_permissions(request):
# 获取项目中,所有的URL
all_url_dict = get_all_url_dict()
print(all_url_dict)
return HttpResponse("OK")
未经过实际测试。不想用1版本的
我的这个, 中间做了一个限制, 就是 必须要确保每一个。 url 必须要有一个别名。 没有别名的就直接跳过了。
因为,如果使用我的rbac 组件 我需要这个别名, 进行按钮粒度的控制。 必须要有。
但是我没有让他报错, 因为还是有一些,是不需要起别名的。
然后就是把它放到,一个固定的地方了。 放到rbac这个app 哪里都行。 用的时候就导入 get_all_url_dict() 就行了
自动发现项目中的所有URL的更多相关文章
- django2自动发现项目中的url
根据路飞学城luffycity.com 的crm项目修改的 1 url入口:rbac/urls.py urlpatterns = [ ... # 批量操作权限 re_path(r'^multi/per ...
- 权限组件(12):自动发现项目中有别名的URL
自动发现项目中所有有别名的URL,效果如下: customer_list {'name': 'customer_list', 'url': '/customer/list/'} customer_ad ...
- 自动发现项目中的url
def check_url_exclude(url): """ 判断url是否需要自动被发现,如果不是则移除 :param url: 自动发现的url :return: ...
- 自动发现项目中的URL,django1版本和django2版本
一.django 1 版本 routers.py import re from collections import OrderedDict from django.conf import setti ...
- Django自动获取项目中的全部URL
import re from collections import OrderedDict from django.conf import settings from django.utils.mod ...
- SpringMVC项目中获取所有URL到Controller Method的映射
Spring是一个很好很强大的开源框架,它就像是一个容器,为我们提供了各种Bean组件和服务.对于MVC这部分而言,它里面实现了从Url请求映射控制器方法的逻辑处理,在我们平时的开发工作中并不需要太多 ...
- zabbix自动发现功能实现批量web url监控
需求: 现在有大量url需要监控,形式如http://www.baidu.com ,要求url状态不为200即报警. 需求详细分析: 大量的url,且url经常变化,现在监控用的是zabbix,如果手 ...
- [Vscode插件] 自动编译项目中的Sass文件为CSS
插件名 : Live Sass Compiler 今天在VSCode中发现了一个自动watch项目目录下sass文件的插件,摆脱了在控制台中进行手动watch的繁琐. 安装好以后点击右下角即可自动编译 ...
- 安装使用Entity Framework Power Tool Bate4 (Code First)从已建好的数据自动生成项目中的对应Model(新手贴,望各位大侠给予指点)
从开始学习使用MVC以后,同时也开始接触EF,很多原理都不是太懂,只知道安装了EF以后,点击哪里可以生成数据库对应的Model,不用再自己手写Model.这里记录的就是如何从已建立好的数据库生成项目代 ...
随机推荐
- linux 一个跟踪文件删除的小技巧
最近有同事问我说他有个现场环境,经常会丢失业务文件,每天都出现,几百个里面丢失1到两个. 为了解决这个问题,我让他布置audit,具体可以man一下auditctl. 过了一天,他说audit.log ...
- Extjs4 上传图片并进行图片格式以及大小验证
在做项目是遇到上传图片,并在前端限制图片上传的大小,下面就直接贴出主要的上传图片的代码,以及图片大小的验证,但前端没有验证图片的宽高验证 一.先创建出上传图片的组件,使用filefield组件 var ...
- centos6.9出现openvpn:error=certificate signature failure的处理
原因: 将原来openwrt上用的证书复制到centos 6.9后,客户端都连不上了,查了服务器log,出现是error=certificate signature failure错误. 处理方法见帖 ...
- 那些年,我们追过的PHP自加自减运算(1)
------------------------------------------------------------------------------------------- PHP的运算符号 ...
- 21 week4 submit buidAndRun() node-rest-client
. 我们想实现一个提交代码的功能 这个功能有nodeserver 传到后边的server 验证 在返回给nodeserver 我们稍微修改一下ui ATOM修改文件权限不够 用下面命令 我们 Cont ...
- springboot配置异常 web页面跳转
第一步 controller中 package cn.itcast.springboot.controller; import org.springframework.stereotype.Contr ...
- 基于Java SE集合的图书管理系统
图书管理系统一.需求说明1.功能:登录,注册,忘记密码,管理员管理,图书管理.2.管理员管理:管理员的增删改查.3.图书管理:图书的增删改查.4.管理员属性包括:id,姓名,性别,年龄,家庭住址,手机 ...
- C#中属性和字段的区别
属性和字段的区别 在C#中,我们可以非常自由的.毫无限制的访问公有字段,但在一些场合中,我们可能希望限制只能给字段赋于某个范围的值.或是要求字段只能读或只能写,或是在改变字段时能改变对象的其他一些状态 ...
- Python自动化运维开发实战 一、初识Python
导语 都忘记是什么时候知道python的了,我是搞linux运维的,早先只是知道搞运维必须会shell,要做一些运维自动化的工作,比如实现一些定时备份数据啊.批量执行某个操作啊.写写监控脚本什么的. ...
- Python 类的魔术方法
Python中类的魔术方法 在Python中以两个下划线开头的方法,__init__.__str__.__doc__.__new__等,被称为"魔术方法"(Magic method ...