C++求图任意两点间的所有路径
基于连通图,邻接矩阵实现的图,非递归实现。
算法思想:
设置两个标志位,①该顶点是否入栈,②与该顶点相邻的顶点是否已经访问。
A 将始点标志位①置1,将其入栈
B 查看栈顶节点V在图中,有没有可以到达、且没有入栈、且没有从这个节点V出发访问过的节点
C 如果有,则将找到的这个节点入栈,这个顶点的标志位①置1,V的对应的此顶点的标志位②置1
D 如果没有,V出栈,并且将与v相邻的全部结点设为未访问,即全部的标志位②置0
E 当栈顶元素为终点时,设置终点没有被访问过,即①置0,打印栈中元素,弹出栈顶节点
F 重复执行B – E,直到栈中元素为空
先举一个例子吧
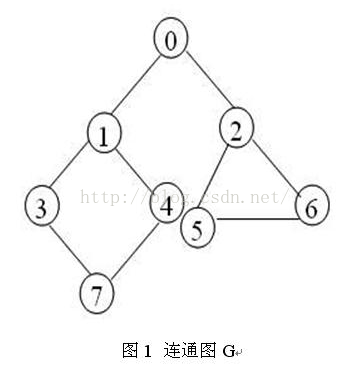
假设简单连通图如图1所示。假设我们要找出结点3到结点6的所有路径,那么,我们就设结点3为起点,结点6为终点。找到结点3到结点6的所有路径步骤如下:
1、 我们建立一个存储结点的栈结构,将起点3入栈,将结点3标记为入栈状态;
2、 从结点3出发,找到结点3的第一个非入栈没有访问过的邻结点1,将结点1标记为入栈状态,并且将3到1标记为已访问;
3、 从结点1出发,找到结点1的第一个非入栈没有访问过的邻结点0,将结点0标记为入栈状态,并且将1到0标记为已访问;
4、 从结点0出发,找到结点0的第一个非入栈没有访问过的邻结点2,将结点2标记为入栈状态,并且将0到2标记为已访问;
5、 从结点2出发,找到结点2的第一个非入栈没有访问过的邻结点5,将结点5标记为入栈状态,并且将2到5标记为已访问;
6、 从结点5出发,找到结点5的第一个非入栈没有访问过的邻结点6,将结点6标记为入栈状态,并且将5到6标记为已访问;
7、 栈顶结点6是终点,那么,我们就找到了一条起点到终点的路径,输出这条路径;
8、 从栈顶弹出结点6,将6标记为非入栈状态;
9、 现在栈顶结点为5,结点5没有非入栈并且非访问的结点,所以从栈顶将结点5弹出,并且将5到6标记为未访问;
10、 现在栈顶结点为2,结点2的相邻节点5已访问,6满足非入栈,非访问,那么我们将结点6入栈;
11、 现在栈顶为结点6,即找到了第二条路径,输出整个栈,即为第二条路径
12、 重复步骤8-11,就可以找到从起点3到终点6的所有路径;
13、 栈为空,算法结束。
下面讲一下C++代码实现
图类,基于邻接矩阵,不详细的写了 ==
class Graph
{
private:
CArray<DataType,DataType> Vertices;
int Edge[MaxVertices][MaxVertices];
int numOfEdges;
public:
Graph();
~Graph();
void InsertVertex(DataType Vertex);
void InsertEdge(int v1,int v2,int weight);
int GetWeight(int i,int j);
int GetVertices();
DataType GetValue(int i);
};
首先自己写一个简单的“栈类”,由于新增了些方法所以不完全叫栈
template<class T>
class Stack
{
private:
int m_size;
int m_maxsize;
T* data;
public:
Stack();
~Stack();
void push(T data); //压栈
T pop(); //出栈,并返回弹出的元素
T peek(); //查看栈顶元素
bool isEmpty(); //判断是否空
int getSize(); //得到栈的中元素个数
T* getPath(); //返回栈中所有元素
};
template<class T>
Stack<T>::Stack()
{
m_size=0;
m_maxsize=100;
data=new T[m_maxsize];
}
template<class T>
Stack<T>::~Stack()
{
delete []data;
}
template<class T>
T Stack<T>::pop()
{
m_size--;
return data[m_size];
} template<class T>
void Stack<T>::push(T d)
{
if (m_size==m_maxsize)
{
m_maxsize=2*m_maxsize;
T* new_data=new T[m_maxsize];
for (int i=0;i<m_size;i++)
{
new_data[i]=data[i];
}
delete []data;
data=new_data;
}
data[m_size]=d;
m_size++;
} template<class T>
T Stack<T>::peek()
{
return data[m_size-1];
} template<class T>
bool Stack<T>::isEmpty()
{
if (m_size==0)
{
return TRUE;
}
else
{
return FALSE;
}
} template<class T>
T* Stack<T>::getPath()
{
T* path=new T[m_size];
for (int i=0;i<m_size;i++)
{
path[i]=data[i];
}
return path;
} template<class T>
int Stack<T>::getSize()
{
return m_size;
}
Vertex类,便于遍历全部的结点
class CVertex
{
private:
int m_num;//保存与该顶点相邻的顶点个数
int *m_nei; //与该顶点相邻的顶点序号
int *m_flag; //与该顶点相邻的顶点是否访问过
bool isin; //该顶点是否入栈
public:
CVertex();
void Initialize(int num,int a[]);
int getOne(); //得到一个与该顶点相邻的顶点
void resetFlag(); //与该顶点相邻的顶点全被标记为未访问
void setIsin(bool);//标记该顶点是否入栈
bool isIn(); //判断该顶点是否入栈
void Reset();//将isin和所有flag置0
~CVertex(); };
CVertex::CVertex()
{
m_num=SIZE;
m_nei=new int[m_num];
m_flag=new int[m_num];
isin=false;
for (int i=0;i<m_num;i++)
{
m_flag[i]=0;
} }
void CVertex::Initialize(int num,int a[])
{
m_num=num;
for (int i=0;i<m_num;i++)
{
m_nei[i]=a[i];
}
}
CVertex::~CVertex()
{
delete []m_nei;
delete []m_flag;
}
int CVertex::getOne()
{
int i=0;
for (i=0;i<m_num;i++)
{
if (m_flag[i]==0) //判断是否访问过
{
m_flag[i]=1; //表示这个顶点已经被访问,并将其返回
return m_nei[i];
}
}
return -1; //所有顶点都已访问过则返回-1
}
void CVertex::resetFlag()
{
for (int i=0;i<m_num;i++)
{
m_flag[i]=0;
}
}
void CVertex::setIsin(bool a)
{
isin=a;
}
bool CVertex::isIn()
{
return isin;
}
void CVertex::Reset()
{
for (int i=0;i<m_num;i++)
{
m_flag[i]=0;
}
isin=false;
}
初始化顶点类
int a[SIZE],num;
for ( i=0;i<SIZE;i++)
{
num=0;
for (int j=0;j<SIZE;j++)
{ if (m_graph.Edge[i][j]!=MaxWeight&&i!=j)
{
a[num]=j;
num++;
} }
vertex[i].Initialize(num,a);
算法实现(由于是基于MFC实现,所有下边的代码不可以直接使用)
stack.push(selection1); //将起点压栈
vertex[selection1].setIsin(true); //标记为已入栈
int path_num=0;
while (!stack.isEmpty()) //判断栈是否空
{ int flag=vertex[stack.peek()].getOne(); //得到相邻的顶点
if (flag==-1) //如果相邻顶点全部访问过
{
int pop=stack.pop(); //栈弹出一个元素
vertex[pop].resetFlag(); //该顶点相邻的顶点标记为未访问
vertex[pop].setIsin(false); //该顶点标记为未入栈
continue; //取栈顶的相邻节点
}
if (vertex[flag].isIn()) //若已经在栈中,取下一个顶点
{
continue;
}
if (stack.getSize()>maxver-1) //判断栈中个数是否超过了用户要求的 ,这里是限制了一条路径节点的最大个数
{
int pop=stack.pop();
vertex[pop].resetFlag();
vertex[pop].setIsin(false);
continue;
}
stack.push(flag); //将该顶点入栈 vertex[flag].setIsin(true); //记为已入栈 if (stack.peek()==selection2) //如果栈顶已经为所求,将此路径记录
{
int *path=stack.getPath();
//保存路径的代码省略
int pop=stack.pop(); //将其弹出,继续探索
vertex[pop].setIsin(false); //清空入栈的标志位
} }
C++求图任意两点间的所有路径的更多相关文章
- Dijkstra算法:任意两点间的最短路问题 路径还原
#define _CRT_SECURE_NO_WARNINGS /* 7 10 0 1 5 0 2 2 1 2 4 1 3 2 2 3 6 2 4 10 3 5 1 4 5 3 4 6 5 5 6 9 ...
- AOJ GRL_1_C: All Pairs Shortest Path (Floyd-Warshall算法求任意两点间的最短路径)(Bellman-Ford算法判断负圈)
题目链接:http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=GRL_1_C All Pairs Shortest Path Input ...
- LCA - 求任意两点间的距离
There are n houses in the village and some bidirectional roads connecting them. Every day peole alwa ...
- 图算法之Floyd-Warshall 算法-- 任意两点间最小距离
1.Floyd-Warshall 算法 给定一张图,在o(n3)时间内求出任意两点间的最小距离,并可以在求解过程中保存路径 2.Floyd-Warshall 算法概念 这是一个动态规划的算法. 将顶点 ...
- 任意两点间的最短路问题(Floyd-Warshall算法)
/* 任意两点间的最短路问题(Floyd-Warshall算法) */ import java.util.Scanner; public class Main { //图的顶点数,总边数 static ...
- 【算法】Floyd-Warshall算法(任意两点间的最短路问题)(判断负圈)
求解所有两点间的最短路问题叫做任意两点间的最短路问题. 可以用动态规划来解决, d[k][i][j] 表示只用前k个顶点和顶点i到顶点j的最短路径长度. 分两种情况讨论: 1.经过顶点k, d[k] ...
- 图中两点间路径为l的数目
用矩阵G表示图的邻接阵. G2中的元素就是两点间路径为2的路径数,同理G3就是两点间路径为3的路径数目. 并且此结论同样适用于有向图. 甚至,此结论适用于有权图,只是算出来的不再是路径数,而是各条路径 ...
- 任意两点间最短距离floyd-warshall ---- POJ 2139 Six Degrees of Cowvin Bacon
floyd-warshall算法 通过dp思想 求任意两点之间最短距离 重复利用数组实现方式dist[i][j] i - j的最短距离 for(int k = 1; k <= N; k++) f ...
- Floyed-Warshall算法(求任意两点间最短距离)
思路:感觉有点像暴力啊,反正我是觉得很暴力,比如求d[i][j],用这个方法求的话,就直接考虑会不会经过点k(k是任意一点) ,最终求得最小值 看代码 #include<iostream> ...
随机推荐
- 1.类的加载机制_继承类的加载(一个小的Demo)说明
今天我们先来一个小的Demo来了解类的加载顺序. public class ClassLoaderTest { public static void main(String[] args) { Sys ...
- 用代码检查Windows程序的位数
方法就是通过读取程序文件的头部来判断,具体代码如下: #include <stdio.h> #include <windows.h> int CrnGetImageFileMa ...
- delphi 动态绑定代码都某个控件
delphi 动态绑定代码都某个控件 http://docwiki.embarcadero.com/CodeExamples/Berlin/en/Rtti.TRttiType_(Delphi)Butt ...
- C# 方法参数传递方式 关键字(in、out、ref)
in: 值传递,默认传递方式: ref:地址/引用传递,调用时该参数必需已经初始化: out:地址/引用传递,调用时该参数不需要先初始化(被调用方负责该参数的初始化). 注1: in 关键字用于向 ...
- ubuntu 安装oracle客户端
from: http://webikon.com/cases/installing-oracle-sql-plus-client-on-ubuntu Installing Oracle SQL*Plu ...
- intellij idea远程debug调试resin4教程
昨天有个项目部署在阿里云 想远程调试不知道怎么弄.看日志需要账户密码很不方便呀.今天加班特意baidu了下. 1.先在远程的resin修改conf中resin.xml配置文件 在server-defa ...
- 模糊查询内存查询java实现
下面说说看到的工作项目中的代码,是这个样子的,事先查询一次数据库,将查询到的整张表的数据存到内存,以后使用时不再查询数据库,而直接操作内存中的数据,这主要用于数据库中的数据比较稳定,不会轻易改变的情况 ...
- Mac下的SecureCRT使用技巧
1.secureCRT session manager 怎么添加到标题栏里? Options - Global Options - General 把 Use dockable session man ...
- 【371】Twitter 分类相关
Bag-of-words model:就是将句子打散成单词的集合. N-gram model:同上,只是按照 n 进行顺序组合. 参考:机器学习实战教程(四):朴素贝叶斯基础篇之言论过滤器 留言板侮辱 ...
- springboot 整合redis redis工具类
一步 : pom中引入相关依赖 <!-- 引入 redis 依赖 --> <dependency> <groupId>org.springframework.boo ...