ConceptVector: Text Visual Analytics via Interactive Lexicon Building using Word Embedding
论文简介
本文是对词嵌入的一种应用,用户可以根据自己的需要创建concept,系统根据用户提供的seed word推荐其他词汇,以帮助用户更高的构建自己的concept。同时用户可以利用自己创建的concept对文本进行分析,通过作者提出的一种算法来实现对评论文本排序,以此来筛选出对用户更有价值的信息。
首先明确concept的基本概念,原文的解释是一组语义相关的关键字,用来描述特定的对象、现象或主题。事实上就相当于一个集合的名字;例如,有一个名为clothing的concept,那么它可能就包含{T-shirt,dress,underwear,put}等等,本文所做的工作就是帮助用户创建用户想要的concept。
同时也要知道词嵌入概念:词嵌入其实就是把每个单词映射成一个向量,这样可以方便机器计算,以此来找到单词之间的相似性。目前词嵌入算法大致分为三类1.Embedding layer、2.Word2Vec/Doc2Vec 3.Glove 本文采用的是Glove算法。
现有研究
LIWC(Linguistic Inquiry and Word Count):人类手工构建的一个concept集,它速度快、解释性强且具有很强的有效性。但另一方面,它耗时耗力,同时它也很小,只有40多个情感concept,每个concept只包含了不到100个词汇。
Empath(该文章发表在CHI 2016):Empath选择了18亿字的现代小说数据集,通过深度学习来寻找这些单词和短语之间的潜在联系。但同样的,它不支持交互,concept都是预先构建好的,用户并不能对他进行自定义更改。
下面用两个例子来说明empath的局限性
example-1:Tweets by U.S. 2016 Presidential Candidates
利用Empath预先构建好的197个concept来分析希拉里和特朗普的两组推文,每组推文包含大概3000条信息,统计结果如图
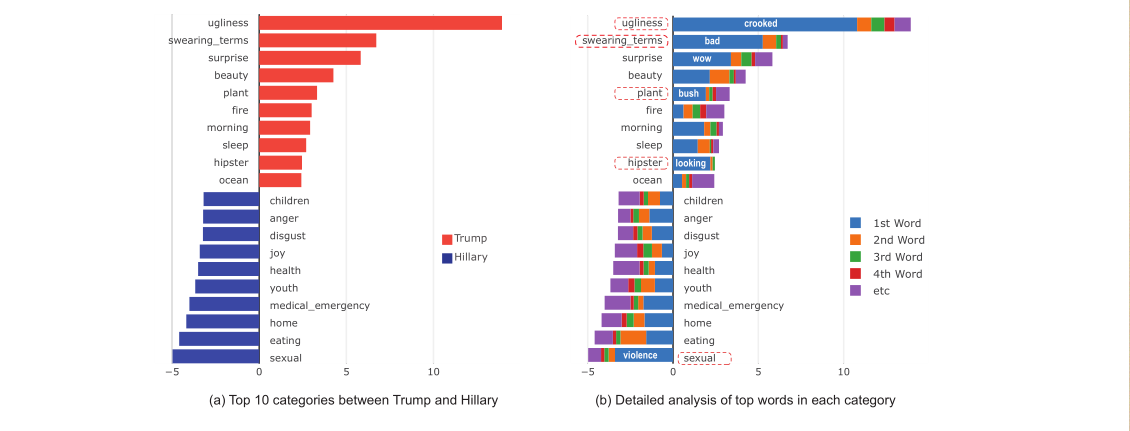
由图可以清晰地看到两组之间存在明显差异(p<0.01)
基于此作者提出了一种交互式构建concept的可视化系统conceptVector,特朗普的集中在丑陋,咒骂,惊喜。而希拉里则集中在性、饮食和家庭的concept。进一步研究发现存在许多假阳性信息,如suprise中的wow,意义较低,只是表示语气而已。而在plant这个concept中占比最大的bush,系统将他识别为灌木丛,
而实际上特朗普指的是Jeff Bush.等等。
example-2:Tweets from NASDAQ 100 Companies
利用斯柯达100家公司的tweets,对于属于每个公司的一组tweet,我们通过计算计算在预先构建的194个concept中包含的单词出现的次数来形成一个194维的特征向量,然后通过k-means聚类和主成分分析法进行2维展示。以此来发现有意义的集群。
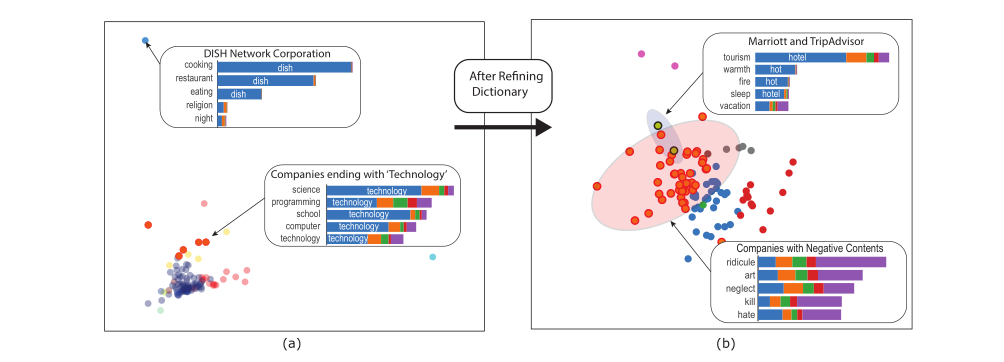
发现名字对于集群效果影响较大,名字中含有{cook、dish}的被集群到一起,同样的含有technology的也被划到了一起。当我们删除这些关键词后,发现集群效果更好。并发现了更有意义的集群。例如,万豪酒店和TripAdvisor因为涉及旅游、度假和睡眠概念的词汇(橄榄绿加黑色边框)而形成了一个集群。带有负面情绪的公司,如嘲弄、忽视、杀戮和仇恨,也被聚集在一起(红点和红边)。
由此本文作者研发了conceptVector系统。
系统设计
整体系统界面如图

简单介绍一下系统:作者将concept化分为两种:单极性和双极性,双极性包括的比如{happy ,unhappy},单极性比如work-related。用户给自己的concept起好名字后,通过添加种子关键字,系统就会给出推荐词,旁边还可以看到推荐词的集群效果以更好的帮助用户进行构建。构建完成后,用户可以用自己的concept来对评论集进行排名,如果发现结果不如人意,用户可以立即对concept进行更改,即:概念细化阶段。通过不断地迭代来筛选出最符合用户需求的信息。同时旁边也有辅助视图帮助用户进行判断。

整个系统设计理念如上图(概念构架+文本分析)
主要算法
Glove: 参考 https://blog.csdn.net/coderTC/article/details/73864097
文章中提出的评分算法
这里只拿双极性词作为举例,单极性大同小异,对于每个concept对应三个集合{positive、negative、and the irrelevant set}分别用Lp,Ln,Li表示
q:待查询的词向量 l:集合L中包含的关键词向量
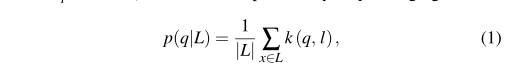
p(q|L)表示q属于L的概率 k(q,l)用来计算q和l之间的相似度

本文用高斯密度核函数来计算向量之间的相似性。
假定先验概率表达式和后验概率表达式为

由此可根据下面这个式子计算出单词q属于concept C 的得分

评估
1.选取15名大学生让他们构建“family”“body”“money”三个concept 用LIWC中的词汇作为标准,在这个字典中,family包含了65个单词,body包含了180个单词,money包含了173个单词,通过准确率,查全率,查到单词的数量三个方面进行比较,结果如图


2.为了验证双极性概念模型好不好,采用Hedonometer project中的10200个关键字组成的对幸福概念相关的排名列表,然后利用自己的基于KDE的算法来对单词进行排序,然后算得与标准集之间的斯皮尔曼相关系数,实验结果如图
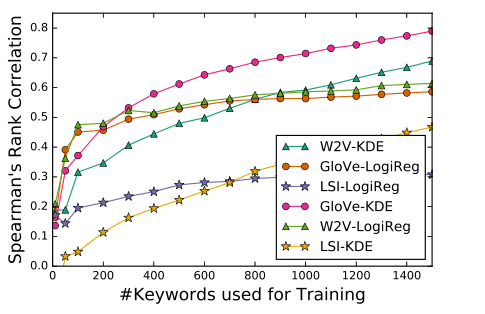
显然GloVe+KDE的组合是最好的。
3.为了说明比Emapth好,还找了两个专家来对两个系统进行审评,来说明ConceptVector确实是好的。
文章贡献
- 一个名为ConceptVector的可视化分析系统,用户可以在其中交互式地为定制概念构建和细化词汇表,并无缝地使用它们分析文档语料库
- 为用户提供字和词的相似性建模,帮助用户构建concept
- 定量结果比较了我们的词与概念的能力类似于人类标记的能力
ConceptVector: Text Visual Analytics via Interactive Lexicon Building using Word Embedding的更多相关文章
- Visual Studio 2017 and Swagger: Building and Documenting Web APIs
Swagger是一种与技术无关的标准,允许发现REST API,为任何软件提供了一种识别REST API功能的方法. 这比看起来更重要:这是一个改变游戏技术的方式,就像Web服务描述语言一样WSDL( ...
- Reducing Snapshots to Points: A Visual Analytics Approach to Dynamic Network Exploration
---恢复内容开始--- 分析静态网络的方法:(1)节点链接图 (2)可视化邻接矩阵 and(3)hierarchical edge bundles. 分析网络演变的方法:(1)时间到时间的映射和(2 ...
- 论文阅读-Clustering temporal disease networks to assist clinical decision support systems in visual analytics of comorbidity progression
一.问题描述: 二.相关工作: 三.方法描述: 四.实验及结果
- 论文列表——text classification
https://blog.csdn.net/BitCs_zt/article/details/82938086 列出自己阅读的text classification论文的列表,以后有时间再整理相应的笔 ...
- fasttext使用笔记
http://blog.csdn.net/m0_37306360/article/details/72832606 这里记录使用fastText训练word vector笔记 github地址:htt ...
- (英文版)使用Visual Studio 2015 编写 MASM 汇编程序!
原文地址:http://kipirvine.com/asm/gettingStartedVS2015/index.htm#CreatingProject Getting Started with MA ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- Big Data Analytics for Security(Big Data Analytics for Security Intelligence)
http://www.infoq.com/articles/bigdata-analytics-for-security This article first appeared in the IEEE ...
- Building Tablet PC Applications ROB JARRETT
Building Tablet PC Applications ROB JARRETT Tablet PC 开发,有需要PDF的留下邮箱 目录This text was added by using ...
随机推荐
- Git钩子详解
钩子 Git钩子是在Git仓库中特定事件发生时自动运行的脚本.可以定制一些钩子,这些钩子可以在特定的情况下被执行,分为Client端的钩子和Server端的钩子.Client端钩子被operation ...
- 用JS制作《飞机大作战》游戏_第3讲(玩家发射子弹)-陈远波
一.公布上一讲中玩家飞机上.下.右移动实现的代码: /*=========================键盘按下事件 keycode为得到键盘相应键对应的数字==================== ...
- Dijkstra(最短路求解)
Dijkstra(最短路求解) 模板: #include<iostream> #include<cstdio> #include<cstring> #include ...
- 【Alpha 冲刺】 5/12
今日任务总结 人员 今日原定任务 完成情况 遇到问题 贡献值 胡武成 建立数据库 未完成 设计表结构的时候,有些逻辑没有设计好,重新review一番设想的功能才初步确定表结构 孙浩楷 根据UI设计, ...
- 【Android自动化】unittest测试框架关于用例执行的几种方法
# -*- coding:utf-8 -*- import unittest class test(unittest.TestCase): def setUp(self): print 'This i ...
- Monad、Actor与并发编程--基于线程与基于事件的并发编程之争
将线程.事件.状态等包装成流的源. 核心:解决线程的消耗和锁的效率问题. Java和Node.js可以说分别是基于线程和基于事件的两个并发编程代表,它们互相指责瞧不起对方,让我们看看各种阵营的声音: ...
- POJ 1066 昂贵的聘礼
Description 年轻的探险家来到了一个印第安部落里. 在那里他和酋长的女儿相爱了,于是便向酋长去求亲.酋长要他用10000个金币作为聘礼才答应把女儿嫁给他.探险家拿不出这么多金币,便请求酋长减 ...
- ES6标准入门之变量的解构赋值简单解说
首先我们来看一看解构的概念,在ES6标准下,允许按照一定模式从数组和对象中提取值,然后对变量进行赋值,这被称作解构,简而言之粗糙的理解就是变相赋值. 解构赋值的规则是,只要等号右边的值不是对象或者数组 ...
- Java之Https请求
import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; import ...
- apache-httpd工作模式
[root@app1 conf]# ../bin/apachectl -lCompiled in modules: core.c mod_access.c mod_auth.c mod_include ...