nodejs实现一个简单的爬虫
nodejs是js语言,实现一个爬出非常的方便。
步骤
1. 使用nodejs的request模块,获取目标页面的html代码;
https://github.com/request/request
2. 使用cheerio模块对html代码做处理(cheerio类似jQuery的语法,所以好用又方便)
https://github.com/cheeriojs/cheerio
下面我们借助exprerss来做一个简单的nodejs爬虫系统。
http://www.expressjs.com.cn/
具体实现
1. 安装依赖模块
$ npm init
初始化一个项目
npm install express request cheerio --save
安装所需的模块
express用于搭建node服务
request类似于ajax的方式获取一个url里的html代码
cheerio类似于jQuery那样对所获取的html代码进行处理
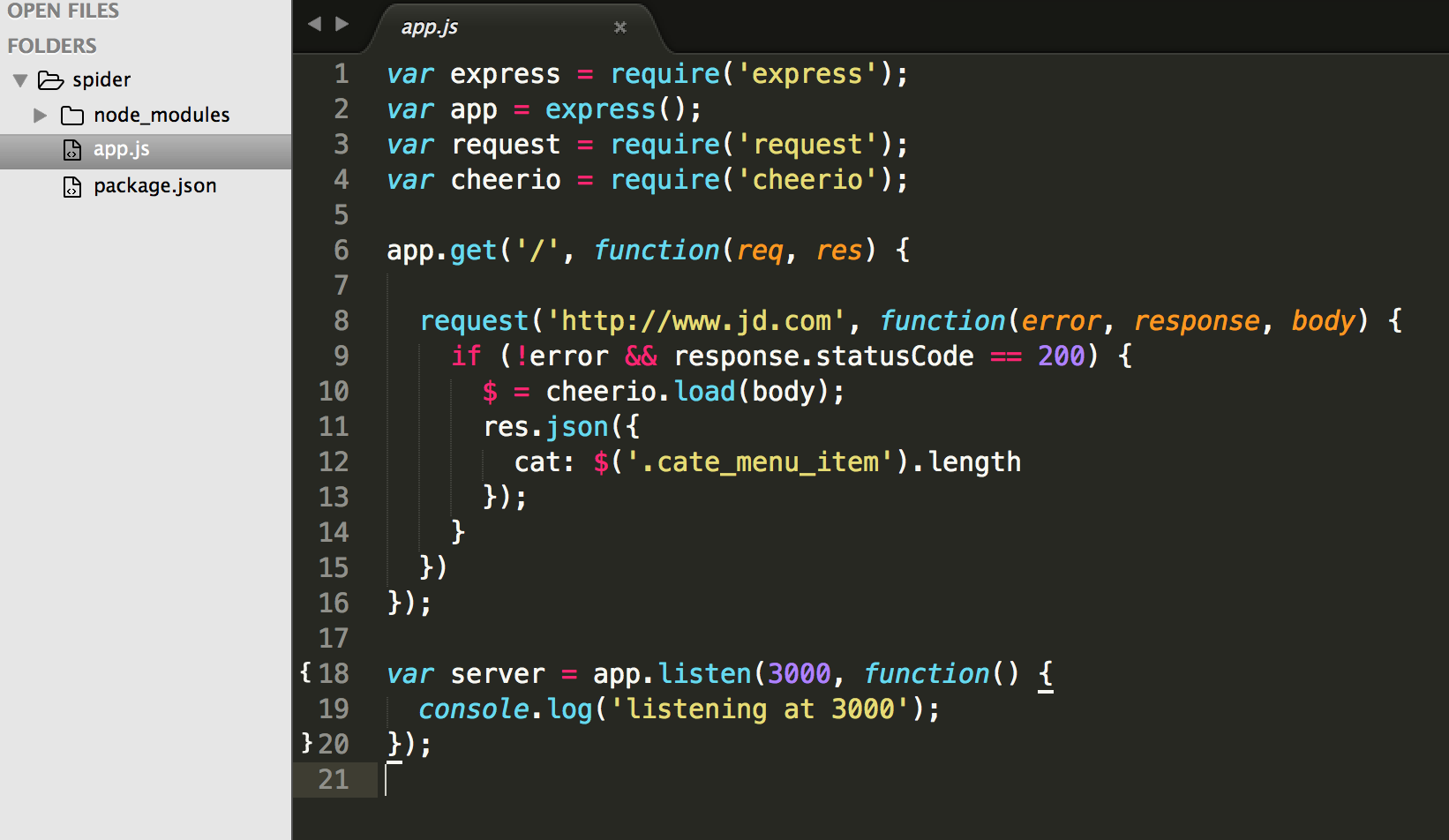
2. 根目录新建一个app.js
var express = require('express');
var app = express();
var request = require('request');
var cheerio = require('cheerio');
app.get('/', function(req, res) {
request('http://www.jd.com', function(error, response, body) {
if (!error && response.statusCode == 200) {
$ = cheerio.load(body);
res.json({
cat: $('.cate_menu_item').length
});
}
})
});
var server = app.listen(3000, function() {
console.log('listening at 3000');
});
项目结构:
这里,我们以京东网站为例子:

统计边栏的类目数量,可以看到$('.cate_menu_item') 的用法完全就像是jQuery的语法,更多例子可以在它的官网查看。
查看结果
运行(我们可以全局安装一个node-dev模块来对我们的nodejs程序监听热刷新)
node-dev app
然后访问http://localhost:3000
返回了 {cat:15}
基础部分就是这样,可以借助这几个模块很方便地开发爬虫系统。
另外比如每天几点去爬,获取失败时的处理,也都有相应的node模块可以去实现。
nodejs实现一个简单的爬虫的更多相关文章
- nodejs实现最简单的爬虫
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫: 开始之前呢,先来个公众号求粉: 将使用的node模块及属性介绍: request: ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- 用nodejs搭建一个简单的服务器
使用nodejs搭建一个简单的服务器 nodejs优点:性能高(读写文件) 数据操作能力强 官网:www.nodejs.org 验证是否安装成功:cmd命令行中输入node -v 如果显示版本号表示安 ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 用nodejs搭建一个简单的服务监听程序
作为一个从业三年左右的,并且从事过半年左右PHP开发工作的前端,对于后台,尤其是对以js语言进行开发的nodejs,那是比较有兴趣的,虽然本身并没有接触过相关的工作,只是自己私下做的一下小实验,但是还 ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 利用 nodeJS 搭建一个简单的Web服务器(转)
下面的代码演示如何利用 nodeJS 搭建一个简单的Web服务器: 1. 文件 WebServer.js: //-------------------------------------------- ...
随机推荐
- AC自动机 HDU 3065
大概就是裸的AC自动机了 #include<stdio.h> #include<algorithm> #include<string.h> #include< ...
- 一次kibana服务失败的排查过程
公司在kubernetes集群上稳定运行数月的kibana服务于昨天下午突然无法正常提供服务,访问kibana地址后提示如下信息: 排查过程: 看到提示后,第一反应肯定是检查elasticsearch ...
- redis-内存异常 Redis is configured to save RDB snapshots解决
连接reids获取数据时提示 Redis is configured to save RDB snapshots, but is currently not able to persist on di ...
- [转]如何循序渐进向dotnet架构师发展
微软的DotNet开发绝对是属于那种入门容易提高难的技术.而要能够成为DotNet架构师没有三年或更长时间的编码积累基本上是不可能的.特别是在大 型软件项目中,架构师是项目核心成员,承上启下,因此RU ...
- 【IT】公司FTP服务器使用说明
FTP服务器的作用:----------------------------------------------1.员工个人或者部门资料临时备份(而不是永久归档): 2.部门或员工间交换巨大资料: 3 ...
- 启动 Eclipse 弹出“Failed to load the JNI shared library jvm.dll”错误的解决方法
原因1:给定目录下jvm.dll不存在. 对策:(1)重新安装jre或者jdk并配置好环境变量.(2)copy一个jvm.dll放在该目录下. 原因2:eclipse的版本与jre或者jdk版本不一致 ...
- 初次认识 C# win32 api
第一次接触win32api,刚开始的时候有点迷迷糊糊的. Windows API 就是windows应用程序接口. win api向上就是windows应用程序,向下就是windows操作系统核心. ...
- 检测对象是否为数组 instanceof
[1,2] instanceof Array //true Object.prototype.toString.apply([]); === "[object Array]"; O ...
- coreseek操作
开启服务$ /usr/local/coreseek/bin/searchd -c /usr/local/coreseek/etc/csft.conf 重新索引: /usr/local/coresee ...
- 机器学习——k-近邻算法
k-近邻算法(kNN)采用测量不同特征值之间的距离方法进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 工作原理:存在一个样本数 ...