nodejs实现一个简单的爬虫
nodejs是js语言,实现一个爬出非常的方便。
步骤
1. 使用nodejs的request模块,获取目标页面的html代码;
https://github.com/request/request
2. 使用cheerio模块对html代码做处理(cheerio类似jQuery的语法,所以好用又方便)
https://github.com/cheeriojs/cheerio
下面我们借助exprerss来做一个简单的nodejs爬虫系统。
http://www.expressjs.com.cn/
具体实现
1. 安装依赖模块
$ npm init
初始化一个项目
npm install express request cheerio --save
安装所需的模块
express用于搭建node服务
request类似于ajax的方式获取一个url里的html代码
cheerio类似于jQuery那样对所获取的html代码进行处理
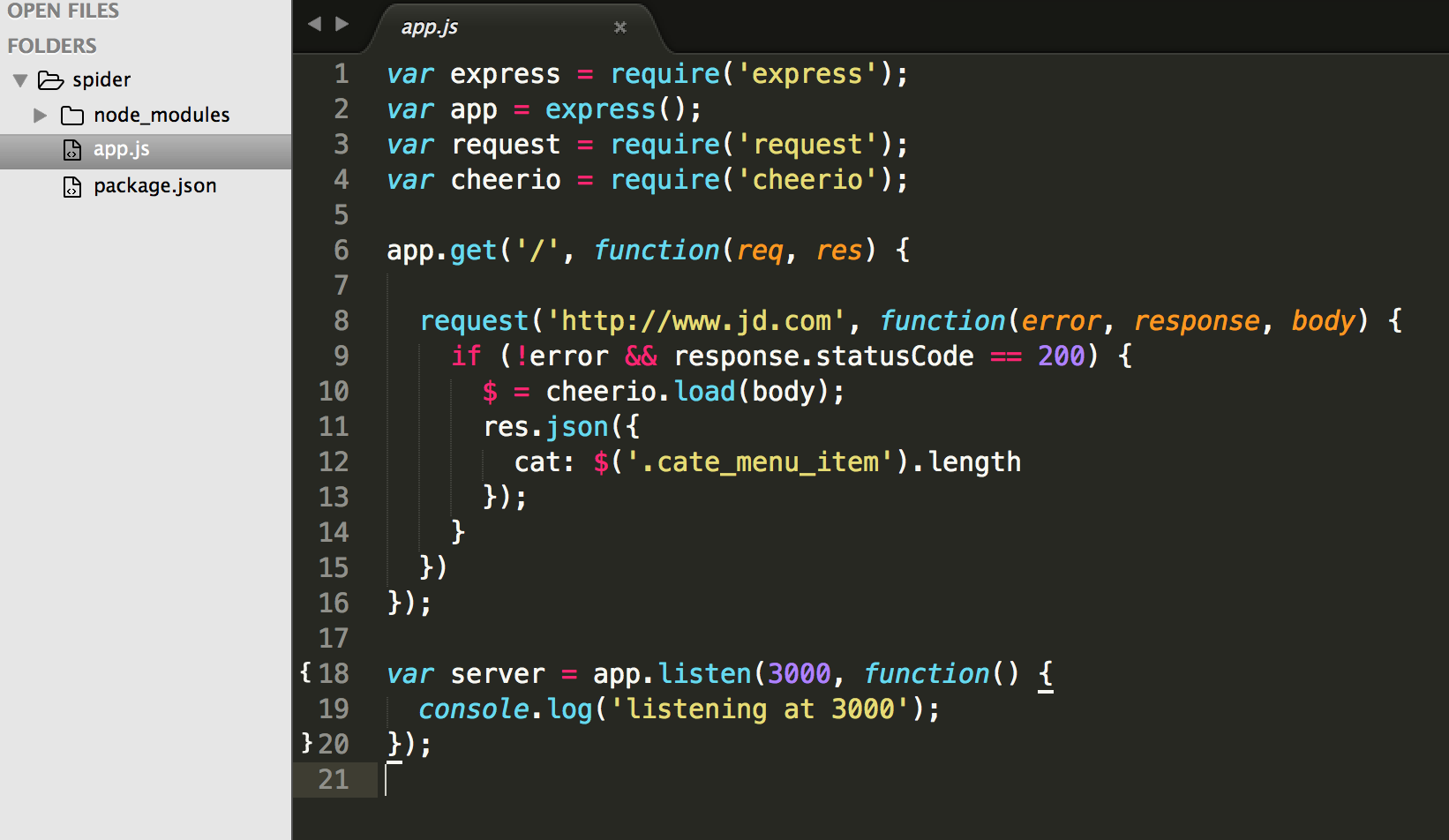
2. 根目录新建一个app.js
var express = require('express');
var app = express();
var request = require('request');
var cheerio = require('cheerio');
app.get('/', function(req, res) {
request('http://www.jd.com', function(error, response, body) {
if (!error && response.statusCode == 200) {
$ = cheerio.load(body);
res.json({
cat: $('.cate_menu_item').length
});
}
})
});
var server = app.listen(3000, function() {
console.log('listening at 3000');
});
项目结构:
这里,我们以京东网站为例子:

统计边栏的类目数量,可以看到$('.cate_menu_item') 的用法完全就像是jQuery的语法,更多例子可以在它的官网查看。
查看结果
运行(我们可以全局安装一个node-dev模块来对我们的nodejs程序监听热刷新)
node-dev app
然后访问http://localhost:3000
返回了 {cat:15}
基础部分就是这样,可以借助这几个模块很方便地开发爬虫系统。
另外比如每天几点去爬,获取失败时的处理,也都有相应的node模块可以去实现。
nodejs实现一个简单的爬虫的更多相关文章
- nodejs实现最简单的爬虫
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫: 开始之前呢,先来个公众号求粉: 将使用的node模块及属性介绍: request: ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- 用nodejs搭建一个简单的服务器
使用nodejs搭建一个简单的服务器 nodejs优点:性能高(读写文件) 数据操作能力强 官网:www.nodejs.org 验证是否安装成功:cmd命令行中输入node -v 如果显示版本号表示安 ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 用nodejs搭建一个简单的服务监听程序
作为一个从业三年左右的,并且从事过半年左右PHP开发工作的前端,对于后台,尤其是对以js语言进行开发的nodejs,那是比较有兴趣的,虽然本身并没有接触过相关的工作,只是自己私下做的一下小实验,但是还 ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 利用 nodeJS 搭建一个简单的Web服务器(转)
下面的代码演示如何利用 nodeJS 搭建一个简单的Web服务器: 1. 文件 WebServer.js: //-------------------------------------------- ...
随机推荐
- Python学习--Python基础语法
第一个Python程序 交互式编程 交互式编程不需要创建脚本文件,是通过 Python 解释器的交互模式进来编写代码. linux上你只需要在命令行中输入 Python 命令即可启动交互式编程,提示窗 ...
- 在linux上如何通过composer安装yii
Composer可以理解成一个依赖管理工具 它能解决以下问题 a) 你有一个项目依赖于若干个库. b) 其中一些库依赖于其他库. c) 你声明你所依赖的东西. d) Composer 会找出哪个版 ...
- Python进制转换
一 内置函数 bin().oct().hex()的返回值均为字符串,且分别带有0b.0o.0x前缀. 实例 统计二进制数里1的个数 def countBits(n): return bin(n).co ...
- table里面,怎么根据checkbox选择的一行中的某个单元格的值是否为空,来判断是否该选中
<table class="stripe" id="tab2"> <tr> <th>选择</th> <th ...
- SSH(Struts2+Spring4+HIbernate5)的简化
今天给大家带来的是一个简单的新闻发布系统 首先在学习过程中我是深有体会,做事情不要浮躁,不要想着一口吃下一个胖子, 最最重要的是理解,理解透了学什么东西都是随心所欲的. 开发环境:win10系统 jd ...
- C语言栈调用机制初探
学习linux离不开c语言,也离不开汇编,二者之间的相互调用在源代码中几乎随处可见.所以必须清楚地理解c语言背后的汇编结果才能更好地读懂linux中相关的代码.否则会有很多疑惑,比如在head.s中会 ...
- 小尝试一下 cocos2d
好奇 cocos2d 到底是怎样一个框架,正好有个项目需要一个游戏框架,所以稍微了解了一下.小结一下了解到的情况. 基本概念 首先呢,因为 cocos2d 是基于 pyglet 做的,你完全可以直接用 ...
- dataTables获取当前行json格式数据
装载表格数据 $(document).ready( function () { //页面加载后装载表格数据 var table = $('#mytable').DataTable( { "s ...
- 使用hexo,如果换了电脑怎么更新博客?
自己今天想到这个问题,于是去知乎搜索了一番,发现不甚理想.没找到合适的,题目就是知乎原题.只好自己解决了.以下直接把自己的答案粘贴过来 今天我突然想到这个问题,想来参考参考,却发现都不太适合我.首先, ...
- Mui.ajax请求服务器正确返回json数据格式
ajax: mui.ajax('http://server-name/login.php',{ data:{ username:'username', password:'password' }, d ...