selenium+chrome抓取淘宝宝贝-崔庆才思路
站点分析
- 看了交互,好复杂
- 看了下Ajax,好复杂
- 看了下其他内容,看不懂...
所以,没啥好分析的,直接上selenium吧
源码及遇到的问题
在搜索时,会跳转到登录界面
这个没有办法,是淘宝的反爬虫机制. 因为通过selenium webdriver调用的浏览器会有很多异于正常浏览器的参数,具体生成了啥参数,咱也没看懂.
具体的可以参考下面这个大姐的文章
而且阿里不愧是阿里,哪怕webdriver调用的chrome中输入用户名和密码依旧不可以.
网上查了一下,基本是selenium是被封的死死的,基本上比较靠谱的方法就是使用pyppeteer库.
那么问题来了...
- 我这次就是玩selenium的,临阵换库,不好.
- 懒
- 懒
- 懒
好了,总结了这么多,最终,发现了淘宝的一个bug. 虽然用户名密码登录的方式会由于ua值校验等问题被拒绝. 但是扫码登录不会...
所以我的解决思路很土,先扫码登录,拿到cookie,然后调用chrome之前,先把cookie写进去. (注意!这里有个坑,很大的坑) 如果不出意外的话,应该是可以的.
step1:干起来! 先取cookie
- def get_taobao_cookies():
- url = 'https://www.taobao.com/'
- browser.get('https://login.taobao.com/')
- while True:
- print("please login to Taobao!")
- # 这里等一下下
- time.sleep(4)
- # 等到界面跳转到首页之后,下手
- while browser.current_url == url:
- tbCookies = browser.get_cookies()
- browser.quit()
- output_path = open('taobaoCookies.pickle', 'wb')
- pickle.dump(tbCookies, output_path)
- output_path.close()
- return tbCookies
知识补充:pickle模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象, 就能对 file 以读取的形式打开:
x = pickle.load(file)
取cookie倒是没什么问题. 问题是,这是我第一次见到原始的cookie,有点懵. 仔细看了之后才搞懂:
- 取出的cookie是一个数组
- 数组的每个元素是一个cookie
- 每个cookie又是一个字典,其中记录这这个cookie的 domian,key,value,path等等属性.
这里我用pickle.dump()方法把cookie存储下来了. 下次使用的时候,直接load一下就好了.
step2:载入cookie
载入的话分为两部分:
第一部分:从文件中读取cookie
这个很简单,不做过多描述
- def read_taobao_cookies():
- if os.path.exists('taobaoCookies.pickle'):
- read_path = open('taobaoCookies.pickle', 'rb')
- tbCookies = pickle.load(read_path)
- else:
- tbCookies = get_taobao_cookies()
- return tbCookies
第二部分:讲cookie载入chrome
这个可把我坑惨了.
先看代码,在search()方法中定义了如何载入cookie
- cookies = read_taobao_cookies()
- # add_cookie之前要先打开一下网页,不然他妈的会报invalid domain错误. 日了狗了
- browser.get('https://www.taobao.com')
- for cookie in cookies:
- # stackoverflow查到的,不知道为啥,要把expiry这个键值对删掉,不然的话,会报invalid argument,MD!
- if 'expiry' in cookie:
- del cookie['expiry']
- browser.add_cookie(cookie)
这里需要注意的有两点:
- 在调用add_cookie()方法之前,必须先打开一个网页.不然的话就会报
InvalidCookieDomainException的错误. - cookie中的'expiry'属性要删除,不然会报
invalid argument: invalid 'expiry'
但是看了下API,add_cookie()是支持这个expiry这个参数的

后来查了一下,当前chromedriver对于expiry只支持int64,不支持double. 据说是chromedriver的一个bug,在后续版本中会修复.
详细回答参见这个问题下的高票答案
step3:放飞自我
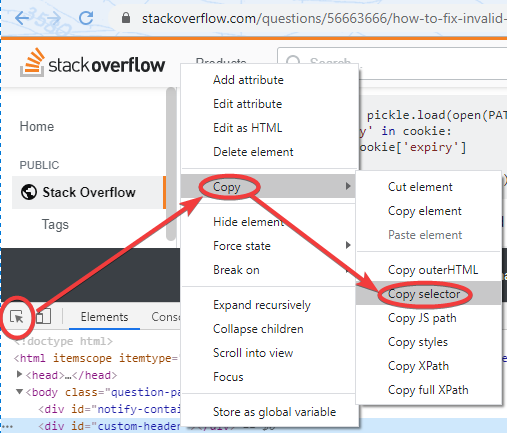
这两个问题解决了之后,基本上剩下的都不是什么大问题了. 这里说一个之前不知道的小技巧,chrome浏览器在源码审查的时候,可以选中页面元素,直接右键复制CSS选择器
这个功能还挺好使的. 表示之前并不知道...
关于phantomJS浏览器的问题
在使用selenium的时候,如果不想看到浏览器界面,可是使用 phantomJS这个无界面的浏览器来代替. 但是看到pycharm报了个warning. 说是phantomJS已经被depressed. 建议使用headless chrome替代.
于是看了一眼headless chrome怎么用. 很简单,在调用chrome的时候传入一个参数即可.
- chrome_options = Options()
- chrome_options.add_argument('--headless')
- browser = webdriver.Chrome(options=chrome_options)
源码
- import os
- import pickle
- import re
- import time
- from pyquery import PyQuery as pq
- from selenium import webdriver
- from selenium.common.exceptions import TimeoutException
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support import expected_conditions as EC
- from selenium.webdriver.support.ui import WebDriverWait
- import pymongo
- from config import *
- #连接数据库
- client = pymongo.MongoClient(MONGO_URL)
- db = client[MONGO_DB]
- # 创建Chrome对象
- browser = webdriver.Chrome()
- wait = WebDriverWait(browser, 10)
- def get_taobao_cookies():
- url = 'https://www.taobao.com/'
- browser.get('https://login.taobao.com/')
- while True:
- print("please login to Taobao!")
- time.sleep(4)
- while browser.current_url == url:
- tbCookies = browser.get_cookies()
- browser.quit()
- output_path = open('taobaoCookies.pickle', 'wb')
- pickle.dump(tbCookies, output_path)
- output_path.close()
- return tbCookies
- def read_taobao_cookies():
- if os.path.exists('taobaoCookies.pickle'):
- read_path = open('taobaoCookies.pickle', 'rb')
- tbCookies = pickle.load(read_path)
- else:
- tbCookies = get_taobao_cookies()
- return tbCookies
- def search():
- try:
- # 直接调用get()方法不行了,淘宝有反爬虫机制,所以要先传一个cookies进去
- # browser.get('https://www.taobao.com')
- cookies = read_taobao_cookies()
- # add_cookie之前要先打开一下网页,不然他妈的会报invalid domain错误. 日了狗了
- browser.get('https://www.taobao.com')
- for cookie in cookies:
- # stackoverflow查到的,不知道为啥,要把expiry这个键值对删掉,不然的话,会报invalid argument,MD!
- if 'expiry' in cookie:
- del cookie['expiry']
- browser.add_cookie(cookie)
- browser.get('https://www.taobao.com')
- input_text = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#q')))
- submit = wait.until(
- EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')))
- input_text.send_keys(KEYWORD)
- submit.click()
- total = wait.until(
- EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')))
- get_products()
- return total.text
- except TimeoutException:
- # 注意这是个递归,如果超时的话,就再请求一次
- return search()
- def next_page(page_number):
- try:
- input_text = wait.until(
- EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input')))
- submit = wait.until(EC.element_to_be_clickable(
- (By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
- input_text.clear()
- input_text.send_keys(page_number)
- submit.click()
- wait.until(EC.text_to_be_present_in_element(
- (By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number)))
- get_products()
- except TimeoutException:
- return next_page(page_number)
- def get_products():
- wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
- html = browser.page_source
- doc = pq(html)
- items = doc('#mainsrp-itemlist .items .item').items()
- for item in items:
- product = {
- # 不知道为什么,取src的话,会出现一些s.gif的链接,所以改取原始图片
- 'image': item.find('.pic .img').attr('data-src'),
- 'price': item.find('.price').text(),
- 'deal': item.find('.deal-cnt').text()[:-3],
- 'title': item.find('.title').text(),
- 'shop': item.find('.shop').text(),
- 'location': item.find('.location').text()
- }
- save_to_mongo(product)
- def save_to_mongo(result):
- try:
- if db[MONGO_TABLE].insert(result):
- print('存储到MONGODB成功:',result)
- except Exception:
- print('存储到MONGODB失败',result)
- def main():
- try:
- total = search()
- total = int(re.compile('(\d+)').search(total).group(1))
- for i in range(2, total + 1):
- next_page(i)
- except Exception as exp:
- print('出错啦',exp)
- finally:
- browser.close()
- if __name__ == '__main__':
- main()

selenium+chrome抓取淘宝宝贝-崔庆才思路的更多相关文章
- selenium+chrome抓取淘宝搜索抓娃娃关键页面
最近迷上了抓娃娃,去富国海底世界抓了不少,完全停不下来,还下各种抓娃娃的软件,梦想着有一天买个抓娃娃的机器存家里~.~ 今天顺便抓了下马爸爸家抓娃娃机器的信息,晚辈只是觉得翻得手酸,本来100页的数据 ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
随机推荐
- 进程的用户ID
进程创建时,系统会在进程上设置几个用户相关的ID 实际用户ID,实际用户组ID,系统根据当前会话登陆的用户信息设置 有效用户ID,有效用户组ID,系统根据所打开的执行文件的模式位,进行设置.set_u ...
- Robot Framework 使用【1】-- 基于Python3.7 + RIDE 最新版本搭建
前言 Robot Framework作为公司能快速落地实现UI自动化测试的一款框架,同时也非常适合刚入门自动化测试的朋友们去快速学习自动化,笔者计划通过从搭建逐步到完成自动化测试的过程来整体描述它的使 ...
- Hpple -- 一个 HTML 解析工具
在开发中,大部分会使用 JSON 进行数据解析,偶尔会用到 HTML. 使用 Objective-C 解析 HTML 或者 XML,系统自带有两种方式一个是通过 libxml,一个是通过 NSXMLP ...
- LVS负载均衡软件使用及(LVS简介、三种工作模式、十种调度算法)
一.LVS简介 LVS(Linux Virtual Server)即Linux虚拟服务器,目前LVS已经被集成到Linux内核模块中.该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案, ...
- css简单整理
style1.css /*统一设置h1.h2.a标签的样式*/ h1,h2,a{ color: aqua; font-size: 50px; } /*如果h1.h2没有上面的单独设置样式那么就会继承b ...
- tornado框架的简单实用
一.安装模块 pip3 install tornado 二.简单的起服务的方法 import json, datetime from tornado.web import RequestHandler ...
- php 随机生成汉字
function getChar($num) // $num为生成汉字的数量 { $b = ''; for ($i=0; $i<$num; $i++) { // 使用chr()函数拼接双字节汉字 ...
- 通过view获取所在的viewController对象
建议写成UIView的分类,如下: .h - (UIViewController *)viewController; .m - (UIViewController *)viewController { ...
- cmd常用小命令
#设置n秒后自动关机 -a取消 shutdown -s -t n #输出内容到fileName里,如果文件不存在将会创建文件,>是替换,>>是追加echo something > ...
- 六、linux基础-计算机网络_线程_进程
6 计算机网络-线程和进程6.1 TCP/IP协议 TCP/IP是Unix/Linux世界的网络基础,在某种意义上,Unix网络就是Tcp/ip,而且Tcp/ip就是网络互连的标准他不是一个独立的协议 ...