(数据科学学习手札83)基于geopandas的空间数据分析——geoplot篇(下)
本文示例代码、数据及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在上一篇文章中我们详细学习了geoplot中较为基础的三种绘图API:pointplot()、polyplot()以及webmap(),而本文将会承接上文的内容,对geoplot中较为实用的几种高级绘图API进行介绍。
 图1
图1
本文是基于geopandas的空间数据分析系列文章的第7篇,通过本文你将学习geoplot中的高级绘图API。
2 geoplot进阶
上一篇文章中的pointplot()、polyplot以及webmap()帮助我们解决了在绘制散点、基础面以及添加在线地图底图的问题,为了制作出信息量更丰富的可视化作品,我们需要更强的操纵矢量数据与映射值的能力,geoplot为我们封装好了几种常见的高级可视化API。
2.1 Choropleth
Choropleth图又称作地区分布图或面量图,我们在系列之前的深入浅出分层设色篇中介绍过其原理及geopandas实现,可以通过将指标值映射到面数据上,以实现对指标值地区分布的可视化。
在geoplot中我们可以通过choropleth()来快速绘制地区分布图,其主要参数如下:
df:传入对应的
GeoDataFrame对象projection:用于指定投影坐标系,传入
geoplot.crs中的对象hue:传入对应df中指定列名或外部序列数据,用于映射面的颜色,默认为None即不进行设色
cmap:和
matplotlib中的cmap使用方式一致,用于控制色彩映射方案alpha:控制全局色彩透明度
scheme:作用类似
geopandas中的scheme参数,用于控制分层设色,详见本系列文章的分层设色篇,但不同的是在geoplot0.4.0版本之后此参数不再搭配分层数量k共同使用,而是更新为传入mapclassify分段结果对象,下文中会做具体演示legend:bool型,用于控制是否显示图例
legend_values:list型,用于自定义图例显示的各个具体数值
legend_labels:list型,用于自定义图例显示的各个具体数值对应的文字标签,与legend_values搭配使用
legend_kwargs:字典,在legend参数设置为True时来传入更多微调图例属性的参数
extent:元组型,用于传入左下角和右上角经纬度信息来设置地图空间范围,格式为
(min_longitude, min_latitude, max_longitude, max_latitude)figsize:元组型,用于控制画幅大小,格式为
(x, y)ax:
matplotlib坐标轴对象,如果需要在同一个坐标轴内叠加多个图层就需要用这个参数传入先前待叠加的axhatch:控制填充阴影纹路,详情见本系列文章前作基础可视化篇图7
edgecolor:控制多边形轮廓颜色
linewidth:控制多边形轮廓线型
下面我们通过实际的例子来学习geoplot.choropleth的用法,这里使用到的数据为美国新型冠状肺炎各州病例数分布,对应日期为2020年5月14日,来自Github仓库:https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports_us;使用到的美国本土各州矢量面数据contiguous-usa.geojson已上传到文章开头对应的Github仓库中:
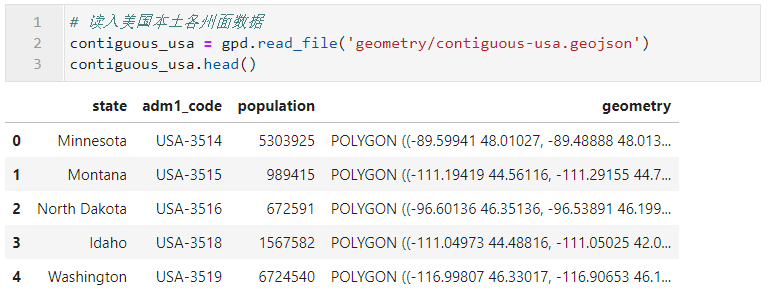 图2
图2
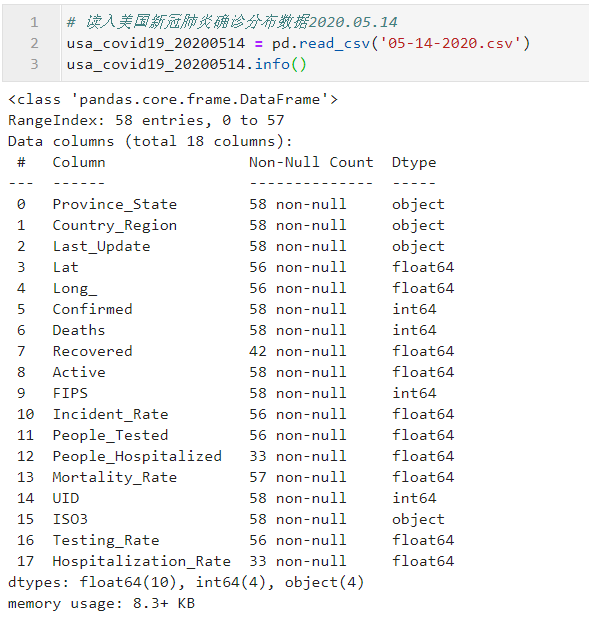 图3
图3
首先我们将两张表中各自对应的州名数据作为键进行连接(注意pd.merge返回的结果类型为DataFrame,需要转换回GeoDataFrame):
# 按照州名列进行连接
usa_plot_base = pd.merge(left=contiguous_usa,
right=usa_covid19_20200513,
left_on='state',
right_on='Province_State')
# 转换DataFrame到GeoDataFrame,注意要加上crs信息
usa_plot_base = gpd.GeoDataFrame(usa_plot_base, crs='EPSG:4326')
接下来我们将确诊数作为映射值,因为美国各州中纽约州和新泽西州确诊数量分别达到了34万和14万,远远超过其他州,所以这里作为单独的图层进行阴影填充以突出其严重程度:
# 图层1:除最严重两州之外的其他州
ax = gplt.choropleth(df=usa_plot_base.query("state not in ['New York', 'New Jersey']"),
projection=gcrs.AlbersEqualArea(),
hue='Confirmed',
scheme=mc.FisherJenks(usa_plot_base.query("state not in ['New York', 'New Jersey']")['Confirmed'], k=3),
cmap='Reds',
alpha=0.8,
edgecolor='lightgrey',
linewidth=0.2,
figsize=(8, 8)
)
# 图层2:纽约州
ax = gplt.polyplot(df=usa_plot_base.query("state == 'New York'"),
hatch='/////',
edgecolor='black',
ax=ax)
# 图层3:新泽西州
ax = gplt.polyplot(df=usa_plot_base.query("state == 'New Jersey'"),
hatch='/////',
edgecolor='red',
extent=usa_plot_base.total_bounds,
ax=ax)
# 实例化cmap方案
cmap = plt.get_cmap('Reds')
# 得到mapclassify中BoxPlot的数据分层点
bp = mc.FisherJenks(usa_plot_base.query("state not in ['New York', 'New Jersey']")['Confirmed'], k=3)
bins = [0] + bp.bins.tolist()
# 制作图例映射对象列表,这里分配Greys方案到三种色彩时对应的是[0, 0.5, 1]这三个采样点
LegendElement = [mpatches.Patch(facecolor=cmap(_ / 2), label=f'{int(bins[_])}-{int(bins[_+1])}')
for _ in range(3)] + \
[mpatches.Patch(facecolor='none',
edgecolor='black',
linewidth=0.2,
hatch='/////',
label='New York: {}'.format(usa_plot_base.query("state == \"New York\"").Confirmed.to_list()[0])),
mpatches.Patch(facecolor='none',
edgecolor='red',
linewidth=0.2,
hatch='/////',
label='New Jersey: {}'.format(usa_plot_base.query("state == \"New Jersey\"").Confirmed.to_list()[0]))]
# 将制作好的图例映射对象列表导入legend()中,并配置相关参数
ax.legend(handles = LegendElement,
loc='lower left',
fontsize=8,
title='确诊数量',
title_fontsize=10,
borderpad=0.6)
# 添加标题
plt.title('美国新冠肺炎各州病例数(截至2020.05.14)', fontsize=18)
# 保存图像
plt.savefig('图4.png', dpi=300, pad_inches=0, bbox_inches='tight')
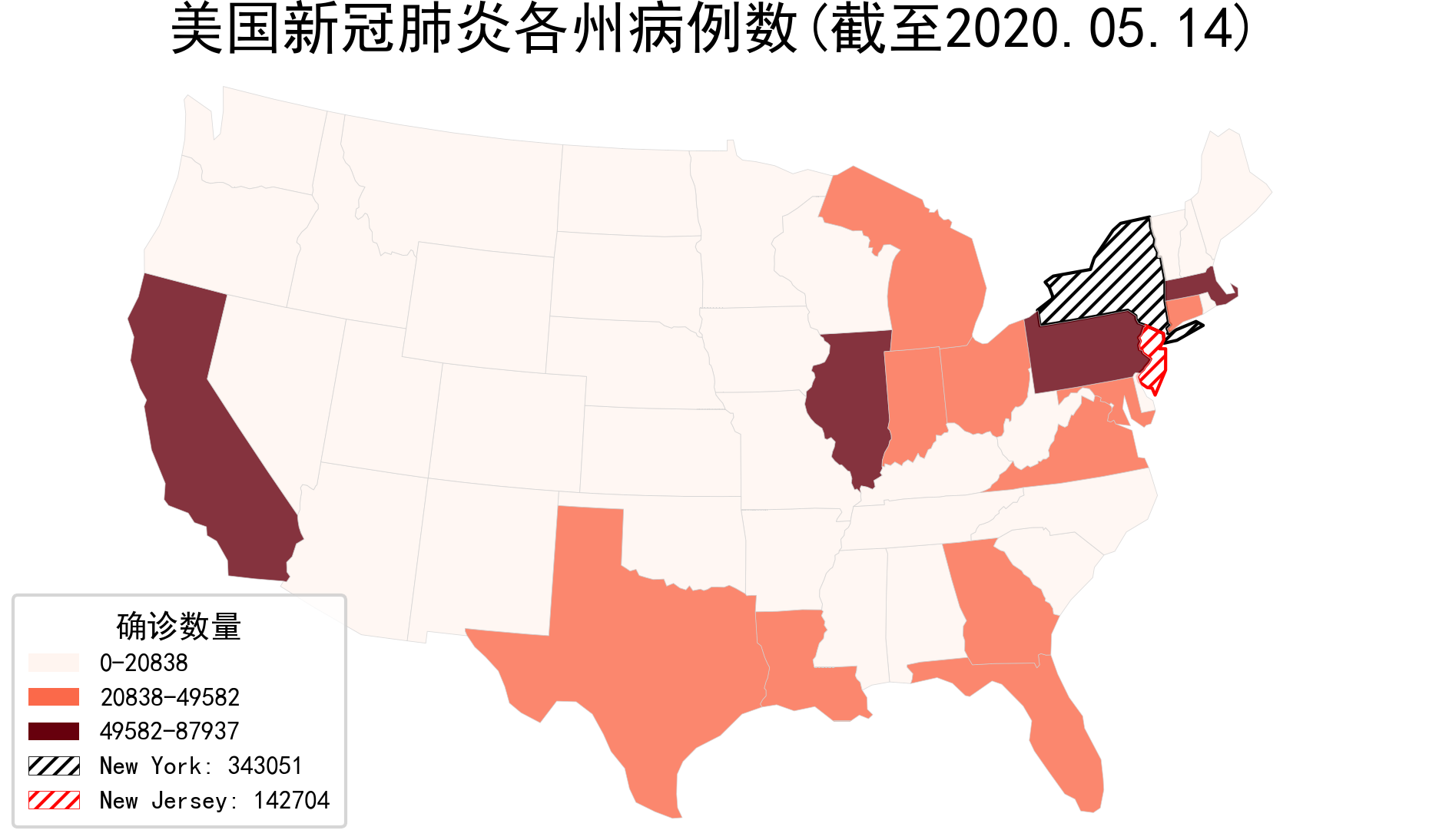 图4
图4
这样我们就得到了图4,需要注意的是,geoplot.choropleth()只能绘制地区分布图,传入面数据后hue参数必须指定对应映射列,否则会报错,因此这里我们叠加纽约州和新泽西州单独面图层时使用的是polyplot()。
2.2 Kdeplot
geoplot中的kdeplot()对应核密度图,其基于seaborn中的kdeplot(),通过对矢量点数据分布计算核密度估计,从而对点数据进行可视化,可用来展示点数据的空间分布情况,其主要参数如下:
df:传入对应的存放点数据的
GeoDataFrame对象projection:用于指定投影坐标系,传入
geoplot.crs中的对象cmap:和
matplotlib中的cmap使用方式一致,用于控制色彩映射方案clip:
GeoSeries型,用于为初始生成的核密度图像进行蒙版裁切,下文会举例说明extent:元组型,用于传入左下角和右上角经纬度信息来设置地图空间范围,格式为
(min_longitude, min_latitude, max_longitude, max_latitude)figsize:元组型,用于控制画幅大小,格式为
(x, y)ax:
matplotlib坐标轴对象,如果需要在同一个坐标轴内叠加多个图层就需要用这个参数传入先前待叠加的axshade:bool型,当设置为False时只有等值线被绘制出,当设置为True时会绘制核密度填充
shade_lowest:bool型,控制是否对概率密度最低的层次进行填充,下文会举例说明
n_levels:int型,控制等值线数量,即按照概率密度对空间进行均匀划分的数量
下面我们回到上一篇文章开头的例子——纽约车祸记录数据,在其他参数均为默认的情况下,调用kdeplot对车祸记录点数据的空间分布进行可视化:
# 图层1:行政边界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 图层2:默认参数下的kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
ax=ax)
# 保存图像
plt.savefig('图5.png', dpi=300, pad_inches=0, bbox_inches='tight')
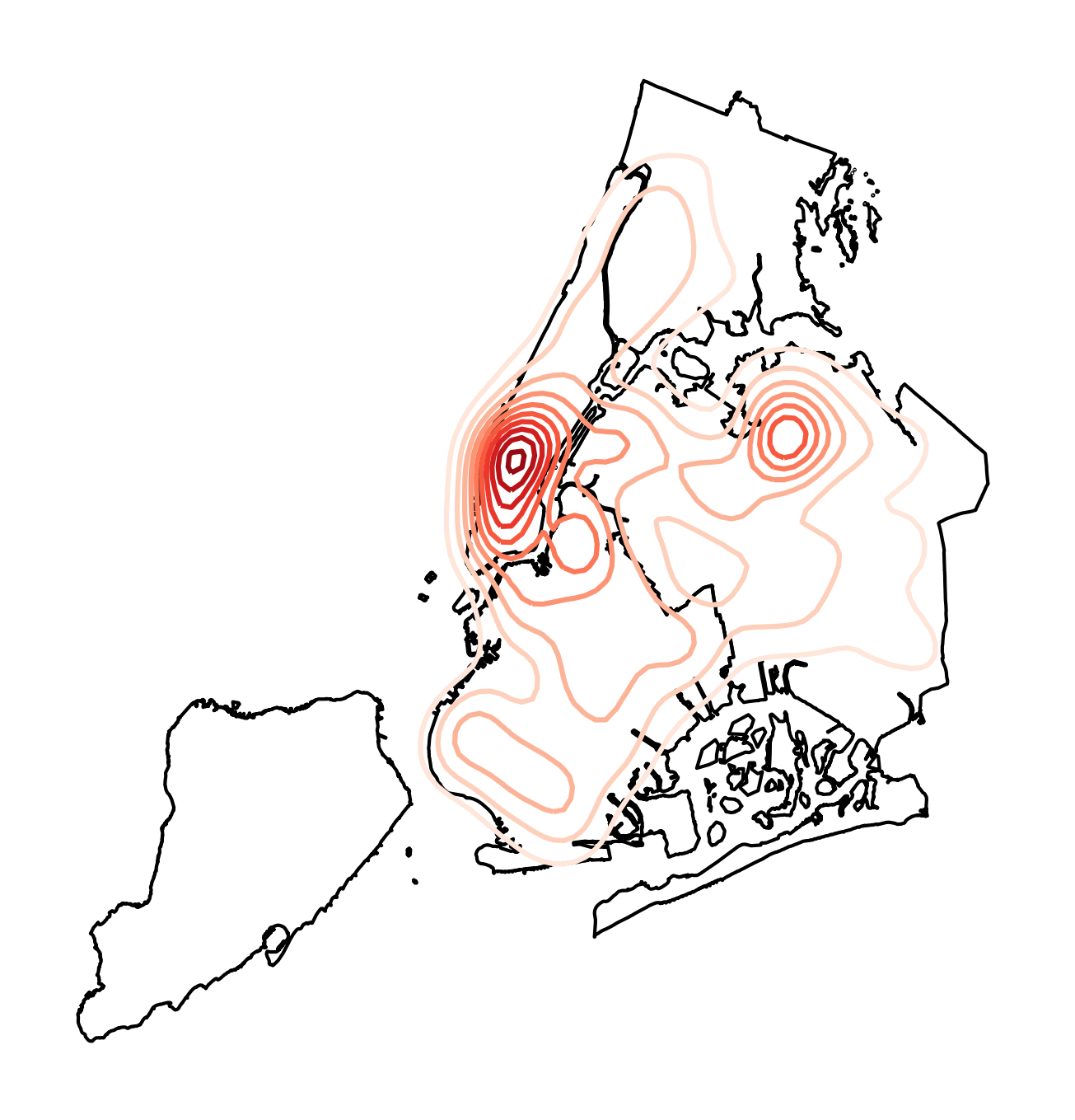 图5
图5
可以看到,在kdeplot()主要参数均为默认值的情况下,我们得到了点数据空间分布的概率估计结果及其等高线,譬如图中比较明显能看到的两个点分布较为密集的中心,下面我们调整n_levles参数到比较大的数字:
# 图层1:行政边界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 图层2:kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
n_levels=30,
ax=ax,
figsize=(8, 8))
# 保存图像
plt.savefig('图6.png', dpi=300, pad_inches=0, bbox_inches='tight')
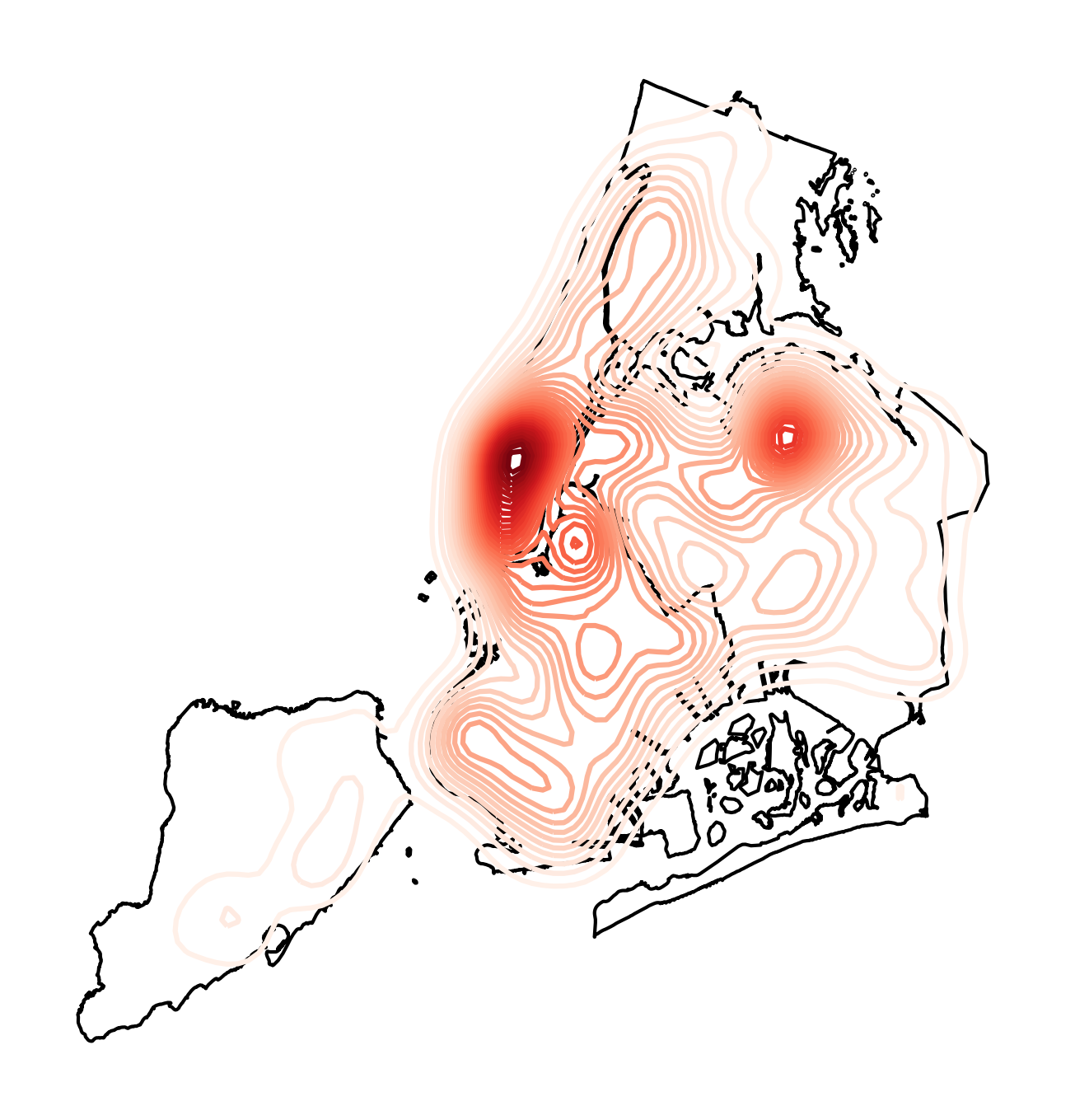 图6
图6
可以看到在增大n_levels参数后,图中等值线的数量随之增加,下面我们设置shade=True:
# 图层1:行政边界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 图层2:kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
shade=True,
ax=ax,
figsize=(8, 8))
# 保存图像
plt.savefig('图7.png', dpi=300, pad_inches=0, bbox_inches='tight')
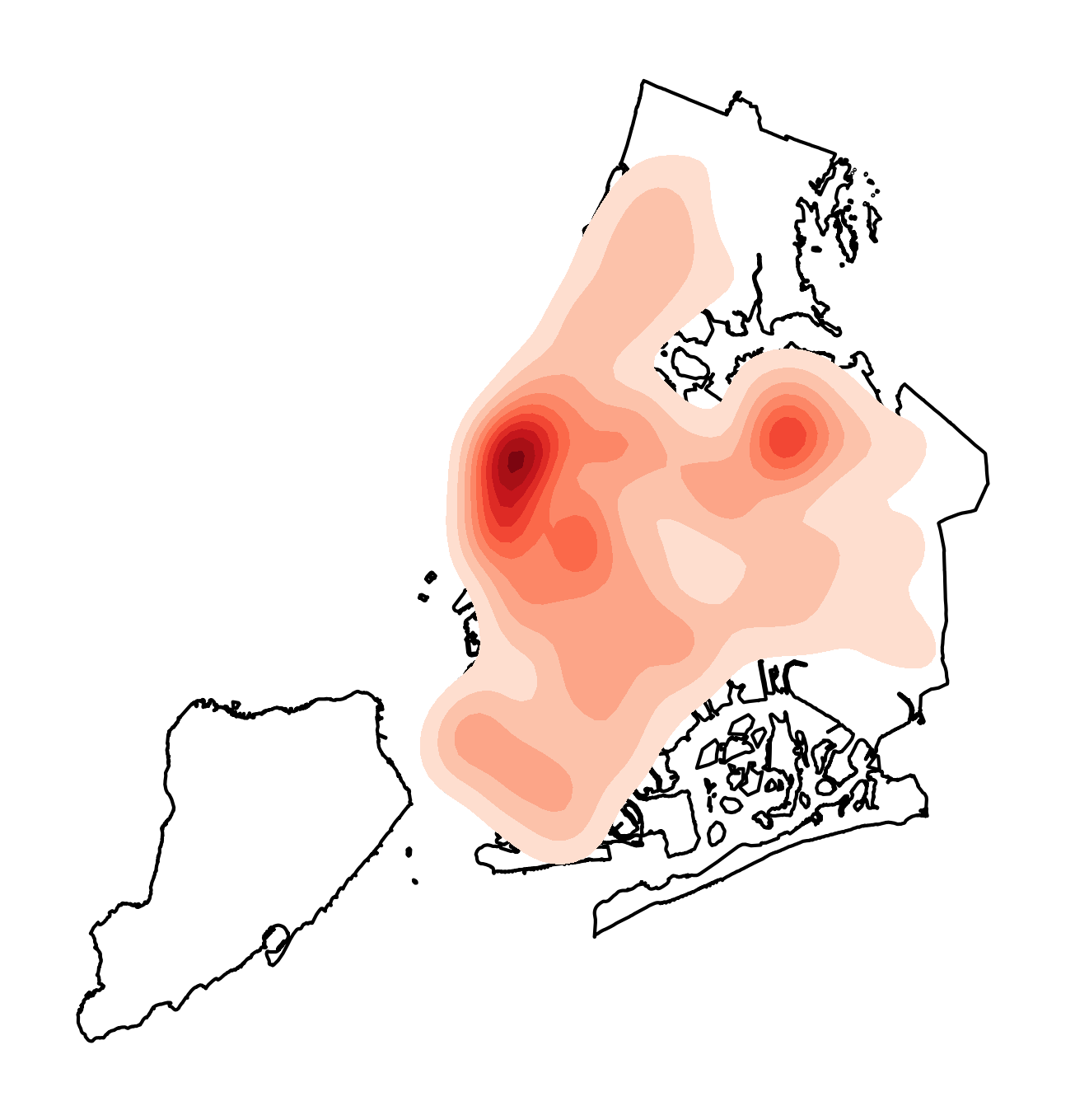 图7
图7
这时图像等值线间得到相应颜色的填充,使得点分布中心看起来更加明显,再添加参数shade_lowest=True,即可对空白区域进行填充:
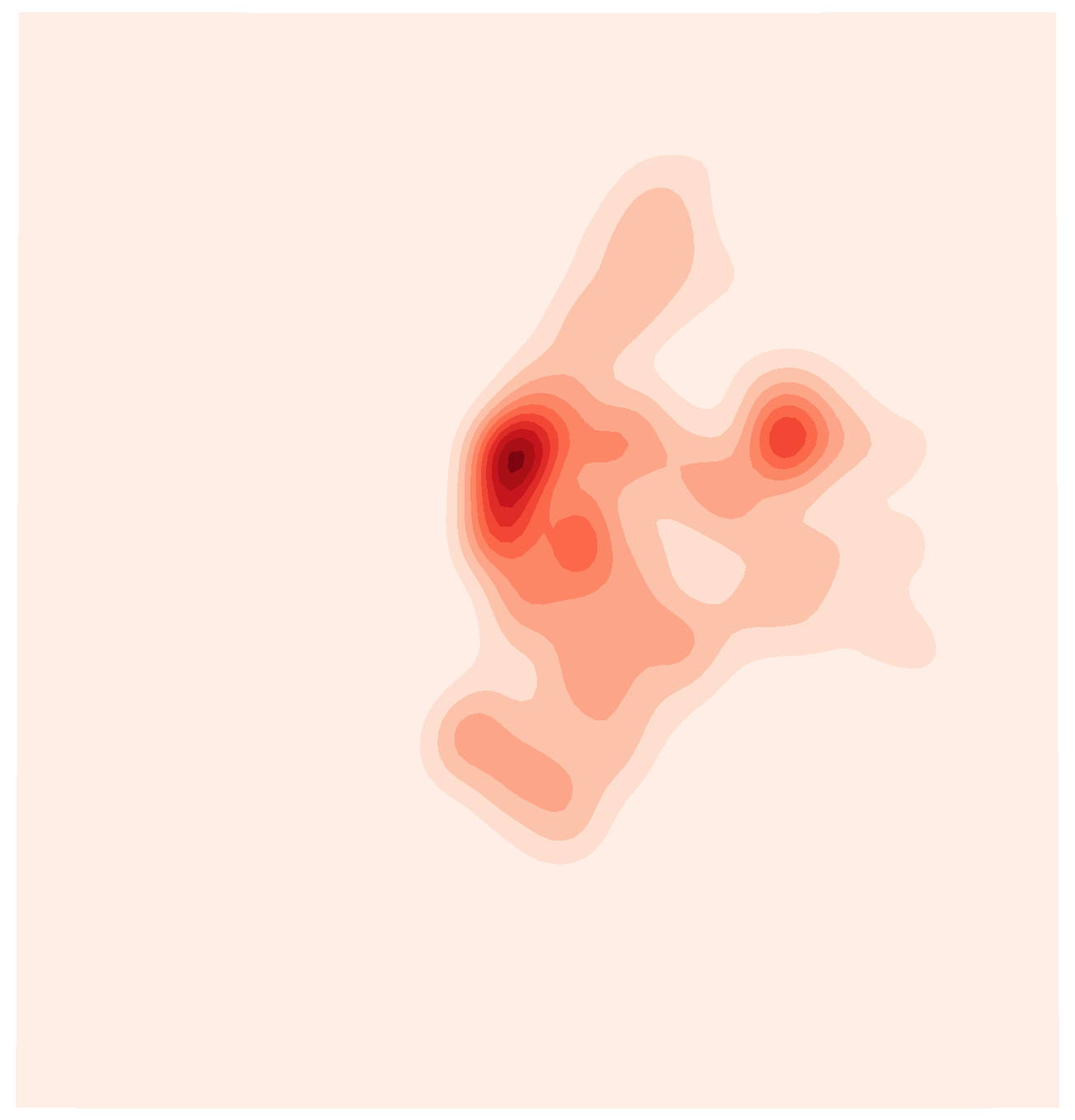 图8
图8
随之而来的问题是整幅图像都被填充,为了裁切出核密度图像的地区轮廓,将底层行政区面数据作为clip的参数传入,便得到理想的效果:
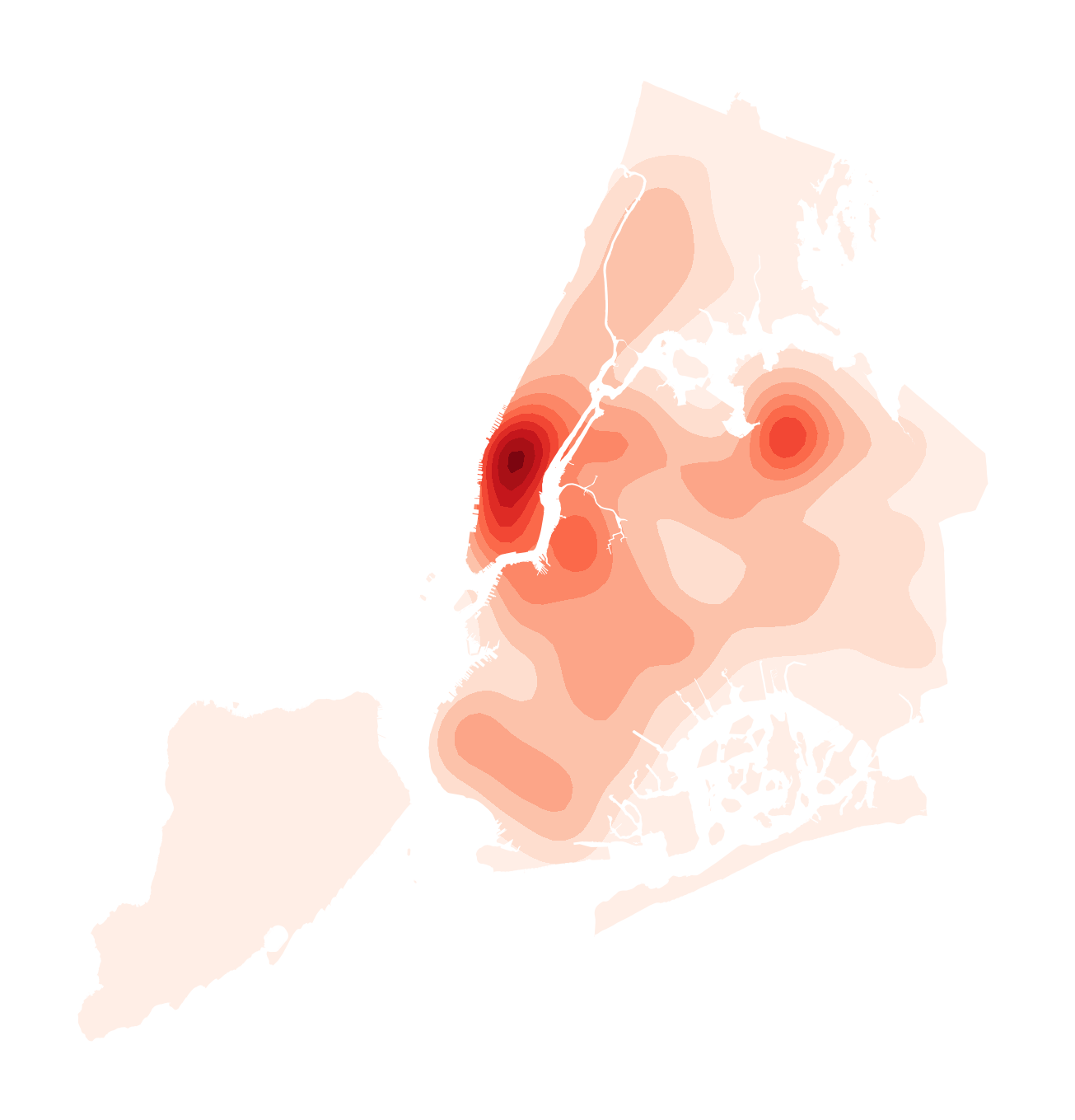 图9
图9
2.3 Sankey
桑基图专门用于表现不同对象之间某个指标量的流动情况,譬如最常见的航线流向情况,其本质是对线数据进行可视化,并将指标值映射到线的色彩或粗细水平上,而geoplot中的sankey()可以用来绘制这种图,尴尬的是sankey()绘制出的OD流向图实在太丑,但sankey()中将数值映射到线数据色彩和粗细的特性可以用来进行与流量相关的可视化,其主要参数如下:
df:传入对应的
GeoDataFrame对象projection:用于指定投影坐标系,传入
geoplot.crs中的对象hue:传入对应df中指定列名或外部序列数据,用于映射线的颜色,默认为None即不进行设色
cmap:和
matplotlib中的cmap使用方式一致,用于控制色彩映射方案alpha:控制全局色彩透明度
scheme:作用类似
geopandas中的scheme参数,用于控制分层设色,详见本系列文章的分层设色篇,但不同的是在geoplot0.4.0版本之后此参数不再搭配分层数量k共同使用,而是更新为传入mapclassify分段结果对象,下文中会做具体演示scale:用于设定映射线要素粗细程度的序列数据,格式同hue,默认为None即每条线等粗
linewidth:当不对线宽进行映射时,该参数用于控制线宽
legend:bool型,用于控制是否显示图例
legend_values:list型,用于自定义图例显示的各个具体数值
legend_labels:list型,用于自定义图例显示的各个具体数值对应的文字标签,与legend_values搭配使用
legend_kwargs:字典,在legend参数设置为True时来传入更多微调图例属性的参数
extent:元组型,用于传入左下角和右上角经纬度信息来设置地图空间范围,格式为
(min_longitude, min_latitude, max_longitude, max_latitude)figsize:元组型,用于控制画幅大小,格式为
(x, y)ax:
matplotlib坐标轴对象,如果需要在同一个坐标轴内叠加多个图层就需要用这个参数传入先前待叠加的ax
下面我们以2015年华盛顿街道路网日平均交通流量数据为例,其中每个要素均为线要素,aadt代表日均流量:
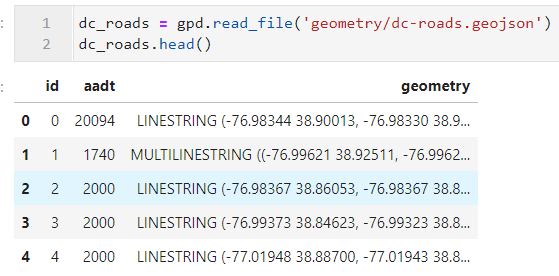 图10
图10
我们将其流量列映射到线的粗细程度和颜色上来,为了美观起见我们选择系列文章分层设色篇中palettable的SunsetDark作为配色方案:
# 选择配色方案为SunsetDark_5
from palettable.cartocolors.sequential import SunsetDark_5
gplt.sankey(
dc_roads,
projection=gcrs.AlbersEqualArea(),
scale='aadt',
hue='aadt',
limits=(0.1, 2), # 控制线宽范围
scheme=mc.NaturalBreaks(dc_roads['aadt']),
cmap=SunsetDark_5.mpl_colormap,
figsize=(8, 8),
extent=dc_roads.total_bounds
)
plt.savefig("图11.png", dpi=500, pad_inches=0, bbox_inches='tight')
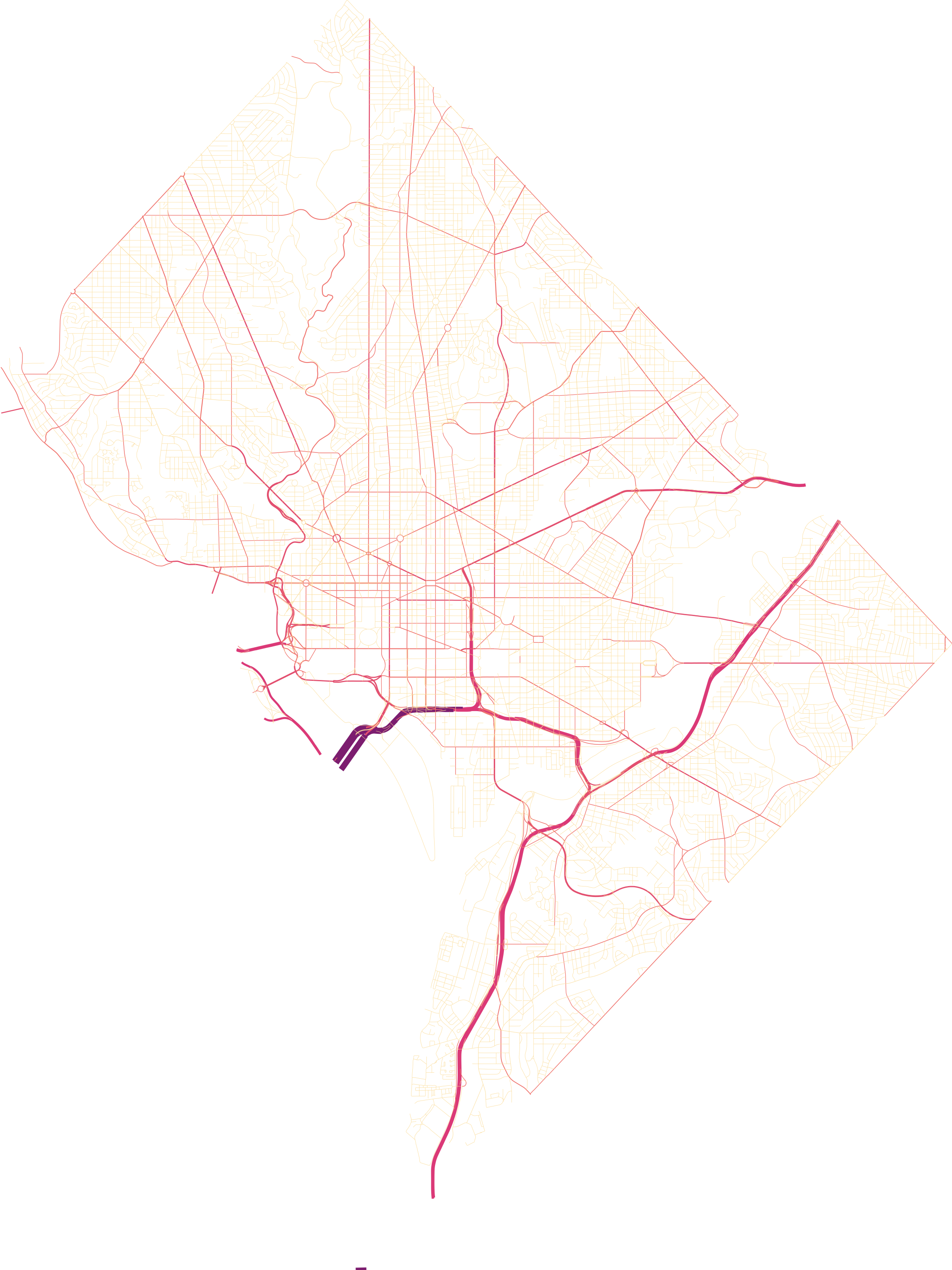 图11
图11
2.4 geoplot中的坐标参考系
geoplot中的坐标参考系与geopandas中管理起来的方式截然不同,因为geopandas基于pyproj管理坐标参考系,而geoplot中的crs子模块来源于cartopy,这一点我跟geoplot的主要开发者聊过,他表示geoplot暂时不支持geopandas中那样自定义任意投影或使用EPSG投影,而是内置了一系列常用的投影,譬如我们上文中绘制美国区域时频繁使用到的AlbersEqualArea()即之前我们在geopandas中通过proj4自定义的阿尔伯斯等面积投影,其他常见投影譬如Web Mercator、Robinson,或者直接绘制球体地图,如本文开头的图1就来自官方示例(https://residentmario.github.io/geoplot/gallery/plot_los_angeles_flights.html#sphx-glr-gallery-plot-los-angeles-flights-py),关于geoplot坐标参考系的细节比较简单本文不多赘述,感兴趣的读者可以前往官网(https://residentmario.github.io/geoplot/api_reference.html#projections)查看。
2.5 在模仿中学习
又到了最喜欢的“复刻”环节啦,本文要模仿的地图可视化作品来自https://github.com/Z3tt/30DayMapChallenge/tree/master/contributions/Day26_Hydrology,同样是用R语言实现,对全球主要河流的形态进行优雅地可视化:
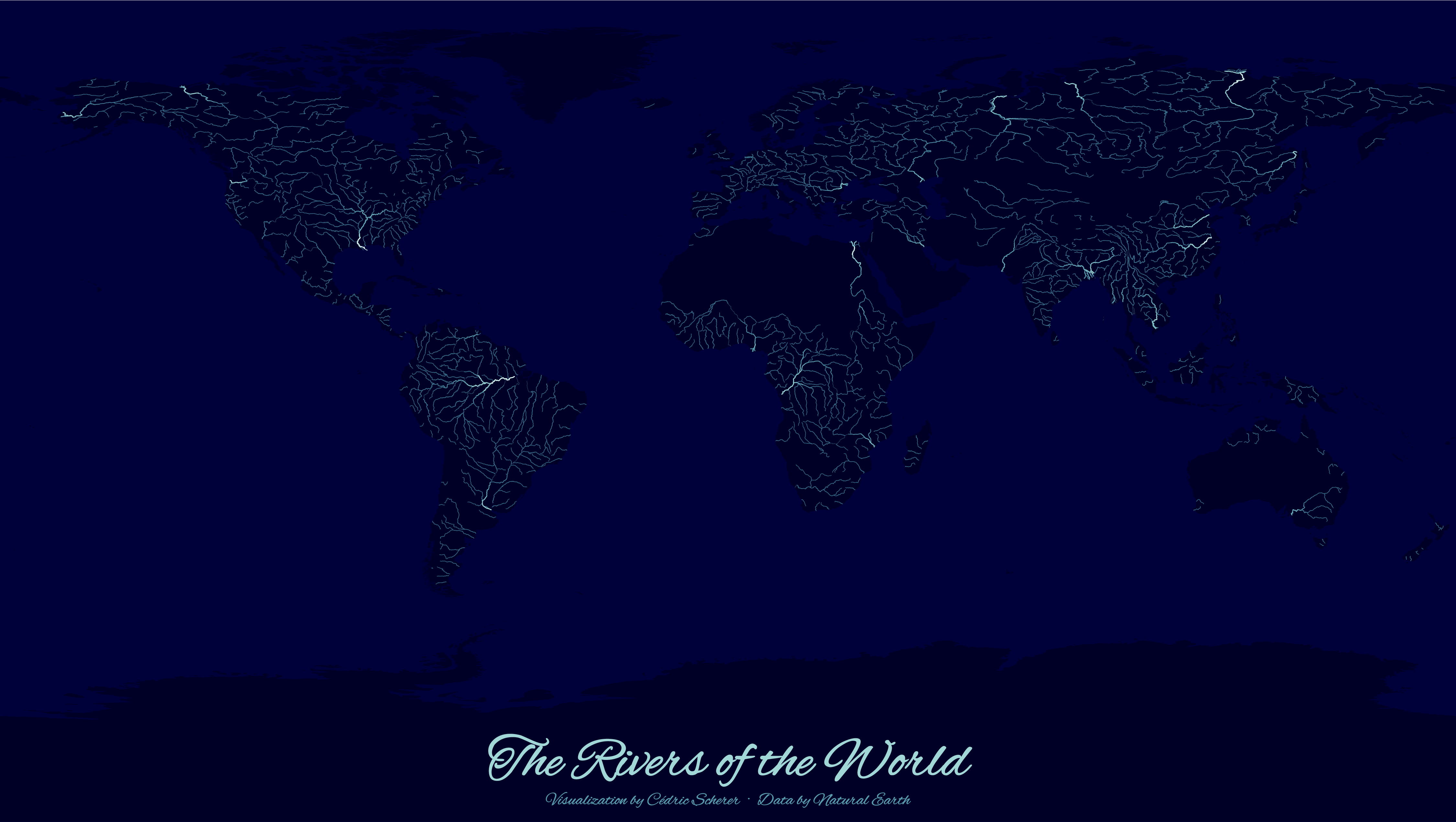 图12
图12
针对其河流宽度方面的可视化,我们基于上文中的sankey()来实现,由于原图中南极洲区域实际上是夸大了的,其R源码中设置的纬度范围达到了-110度,这是原作者为了放得下标题内容,所以在图像下部区域虚构了一篇区域,而geoplot中的extent参数严格要求经度必须在-180到180度之间,纬度在-90到90度之间。因此在原图的基础上我们进行微调,将标题移动到居中位置,具体代码如下:
from palettable.cartocolors.sequential import Teal_7_r
import matplotlib.font_manager as fm
from shapely.geometry import box
# 读入世界主要河流线数据
world_river = gpd.read_file('geometry/world_rivers_dSe.geojson')
# 读入世界海洋面数据
world_ocean = gpd.read_file('geometry/world_ocean.shp')
# 图层1:世界范围背景色,基于shapely.geometry中的bbox来生成矩形矢量
ax = gplt.polyplot(df=gpd.GeoDataFrame({'geometry': [box(-180, -90, 180, 90)]}),
facecolor='#000026',
edgecolor='#000026')
# 图层2:世界海洋面图层
ax = gplt.polyplot(world_ocean,
facecolor='#00003a',
edgecolor='#00003a',
ax=ax)
# 图层3:世界主要河流线图层
ax = gplt.sankey(world_river,
scale='StrokeWeig',
hue='StrokeWeig',
scheme=mc.Quantiles(world_river['StrokeWeig'], 7),
cmap=Teal_7_r.mpl_colormap,
limits=(0.05, 0.4),
figsize=(8, 8),
extent=(-180, -90, 180, 90),
ax=ax)
# 添加标题
ax.text(0, 0, 'The Rivers of the World',
fontproperties=fm.FontProperties(fname="AlexBrush-Regular.ttf"), # 传入Alex Brush手写字体文件
fontsize=28,
color=Teal_7_r.mpl_colors[-1],
horizontalalignment='center',
verticalalignment='center')
# 添加作者信息及数据来源
ax.text(0, -15, 'Visualization by CNFeffery - Data by Natural Earth',
fontproperties=fm.FontProperties(fname="AlexBrush-Regular.ttf"),
fontsize=8,
color='#599bae',
horizontalalignment='center',
verticalalignment='center')
plt.savefig('图13.png', dpi=600, pad_inches=0, bbox_inches='tight')
 图13
图13
以上就是本文的全部内容,我将在下一篇文章中继续与大家一起探讨学习geoplot中更高级的绘图API。如有疑问和意见,欢迎留言或在我的Github仓库中发起issues与我交流。
(数据科学学习手札83)基于geopandas的空间数据分析——geoplot篇(下)的更多相关文章
- (数据科学学习手札82)基于geopandas的空间数据分析——geoplot篇(上)
本文示例代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在前面的基于geopandas的空间数据分 ...
- (数据科学学习手札89)geopandas&geoplot近期重要更新
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 最近一段时间(本文写作于2020-07-1 ...
- (数据科学学习手札111)geopandas 0.9.0重要新特性一览
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,geopandas释放了其最新正式版 ...
- (数据科学学习手札146)geopandas中拓扑非法问题的发现、诊断与修复
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,geopandas作为在Pyt ...
- (数据科学学习手札129)geopandas 0.10版本重要新特性一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在前不久,我们非常熟悉的Python地理 ...
- (数据科学学习手札139)geopandas 0.11版本重要新特性一览
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,就在几天前,geopandas ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札84)基于geopandas的空间数据分析——空间计算篇(上)
本文示例代码.数据及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在本系列之前的文章中我们主要讨论了g ...
随机推荐
- mongodb的远程连接和配置(阿里ECS)
1.) 首先安装mongodb 2.)配置mongodb.conf bind_ip = 0.0.0.0 port= dbpath=/root/mongodb/mongodb-linux-x86_64- ...
- [护网杯2018] easy_laravel
前言 题目环境 buuoj 上的复现,和原版的题目不是完全一样.原题使用的是 nginx + mysql 而 buuoj 上的是 apache + sqlite composer 这是在 PHP5.3 ...
- 01、Hibernate安装配置
1.查看你的Eclipse的版本:Help | About Eclipse Version: 2018-12 (4.10.0) 2.HibernateTools的下载地址为:http:// ...
- fasttext 和pysparnn的安装
- NER命名实体识别,实体级level的评估,精确率、召回率和F1值
pre = "0 0 B_SONG I_SONG I_SONG 0 B_SONG I_SONG I_SONG 0 0 B_SINGER I_SINGER I_SINGER 0 O O O B ...
- 关于go的通信通道channel——chan的一些问题
go版本 1.8 chan类型的声明,有以下几种: var c chan int c := make(chan int) //slice.map.chan都可以通过用make来初始化,其中map.ch ...
- Spark SQL源码解析(三)Analysis阶段分析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Analysis阶段概述 首先 ...
- thinkphp if便签的使用
<foreach name="list" item='v'> <tr> <td><img class="user" s ...
- How to check if directory exist using C++ and winAPI
如果看文件夹是否存在,必须看返回值是不是 INVALID_FILE_ATTRIBUTES #include <windows.h> #include <string> bool ...
- MySQL事务与并发
很多程序员都学过MySQL,而且也会写SQL语句.但仅仅会写还远远不够,在面试中以及在工作中,还必须要会事务和并发. 一.事务 事务是满足 ACID 特性的操作,可以通过 Commit 提交事务, ...