ActiveMQ 笔记(七)ActiveMQ的多节点集群
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
一、Activemq 的集群思想
1、使用Activemq集群的原因
面试题: 引入消息中间件后如何保证其高可用
2、集群实现思路
基于zookeeper和LevelDB搭建ActiveMQ集群。集群仅提供主备方式的高可用集群功能,避免单点故障。
3、集群方案(共有三种)
主要是基于zookeeper+replicated-leveldb-store的主从集群
- 基于shareFileSystem共享文件系统(KahaDB)
- 基于JDBC
- 基于可复制的LevelDB
对比:
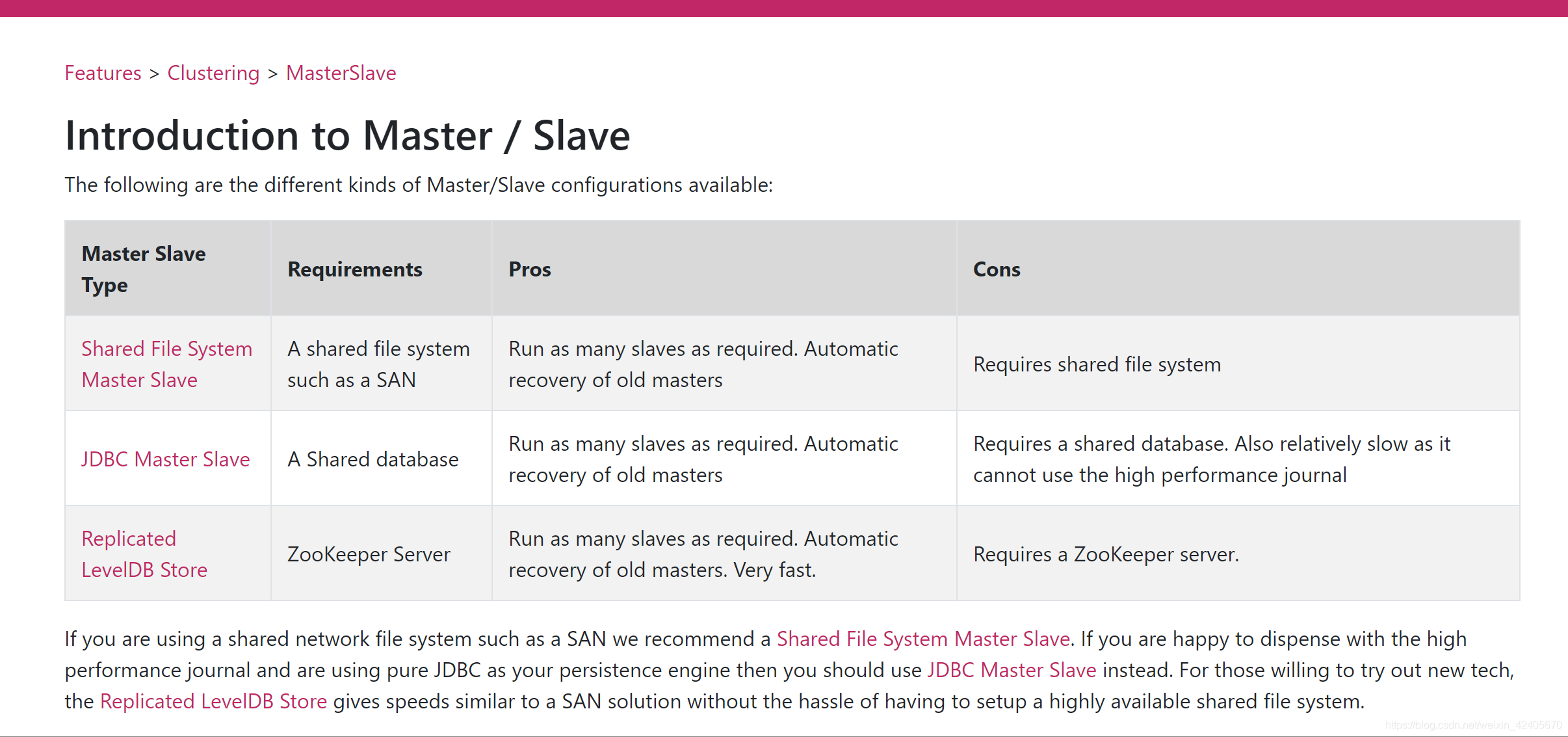
LevelDB,5.6版本之后推出了LecelDB的持久化引擎,它使用了自定义的索引代替常用的BTree索引,其持久化性能高于KahaDB,虽然默认的持久化方式还是KahaDB,但是LevelDB可能会是趋势。
在5.9版本还提供了基于LevelDB和Zookeeper的数据复制方式,作为Master-Slave方式的首选数据复制方案。
二、zookeeper+replicated-leveldb-store的主从集群
1、定义:
从ActiveMQ5.9开始,ActiveMQ的集群实现方式取消了传统的Masster-Slave方式.,增加了基于Zookeeper+LevelDB的Master-Slave实现方式,从5.9版本后也是官网的推荐。
基于Zookeeper和LevelDB搭建ActiveMQ集群,集群仅提供主备方式的高可用集群功能,避免单点故障.
官网:http://activemq.apache.org/replicated-leveldb-store
2、官网集群原理图
地址:http://activemq.apache.org/replicated-leveldb-store

这幅图的意思就是 当 Master 宕机后,zookeper 监测到没有心跳信号, 则认为 master 宕机了,然后选举机制会从剩下的 Slave 中选出一个作为 新的 Master 。
深入解析:
使用Zookeeper集群注册所有的ActiveMQ Broker但只有其中一个Broker可以提供服务,它将被视为Master,其他的Broker处于待机状态被视为Slave。
如果Master因故障而不能提供服务,Zookeeper会从Slave中选举出一个Broker充当Master。Slave连接Master并同步他们的存储状态,Slave不接受客户端连接。所有的存储操作都将被复制到连接至Maste的Slaves。
如果Master宕机得到了最新更新的Slave会变成Master。故障节点在恢复后会重新加入到集群中并连接Master进入Slave模式。
所有需要同步的消息操作都将等待存储状态被复制到其他法定节点的操作完成才能完成。
所以,如给你配置了replicas=3,name法定大小是(3/2)+1 = 2。Master将会存储更新然后等待(2-1)=1个Slave存储和更新完成,才汇报success,至于为什么是2-1,阳哥的zookeeper讲解过自行复习。
有一个ode要作为观察者存在。当一个新的Master被选中,你需要至少保障一个法定mode在线以能够找到拥有最新状态的ode,这个ode才可以成为新的Master。
因此,推荐运行至少3个replica nodes以防止一个node失败后服务中断。
3、部署规划和步骤
- zookeper : 3.4.9 搭建zookeper 集群,搭建 activemq 集群
- 集群搭建: 新建 /mq_cluster 将原始的解压文件复制三个,修改端口 (jetty.xml)
(1)环境和版本
(2)关闭防火墙并保证各个服务器能够ping通
(3)要求具备zk集群并可以成功启动
配置集群教程:
1,创建我们自己的文件夹存放Zookeeper
mkdir /my_zookeeper
2,下载Zookeeper
wget -P /my_zookeeper/ https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
3,解压
tar -zxvf apache-zookeeper-3.5.6-bin.tar.g
4,修改配置文件
文件名必须叫这个zoo.cfg
cp zoo_sample.cfg zoo.cfg
设置一下自定义的数据文件夹(注意要手动创建这个目录,后面会用到),,注意最后一定要有/结尾,没有/会报错这是坑
dataDir=/my_zookeeper/apache-zookeeper-3.5.6-bin/data/
在zoo.cfg件最后面追加集群服务器
server.1=192.168.10.130:2888:3888
server.2=192.168.10.132:2888:3888
server.3=192.168.10.133:2888:3888
(4)集群部署规划列表

(5)创建3台集群目录


就是一台电脑复制三份ActiveMQ
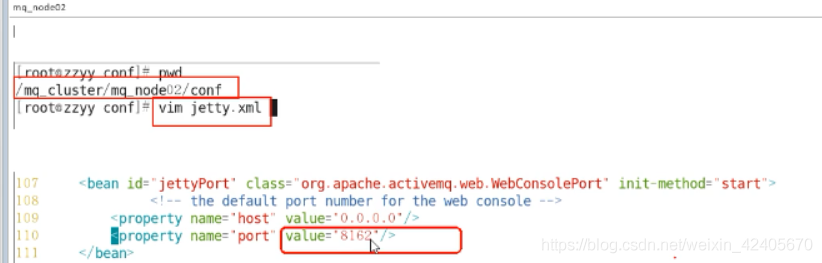
(6)修改管理控制台端口
说明: 就是ActiveMQ后台管理页面的访问端口
(7)增加IP 到域名的映射(/etc/hosts 文件)
说明:hostname名字映射(如果不映射只需要吧mq配置文件的hostname改成当前主机ip)

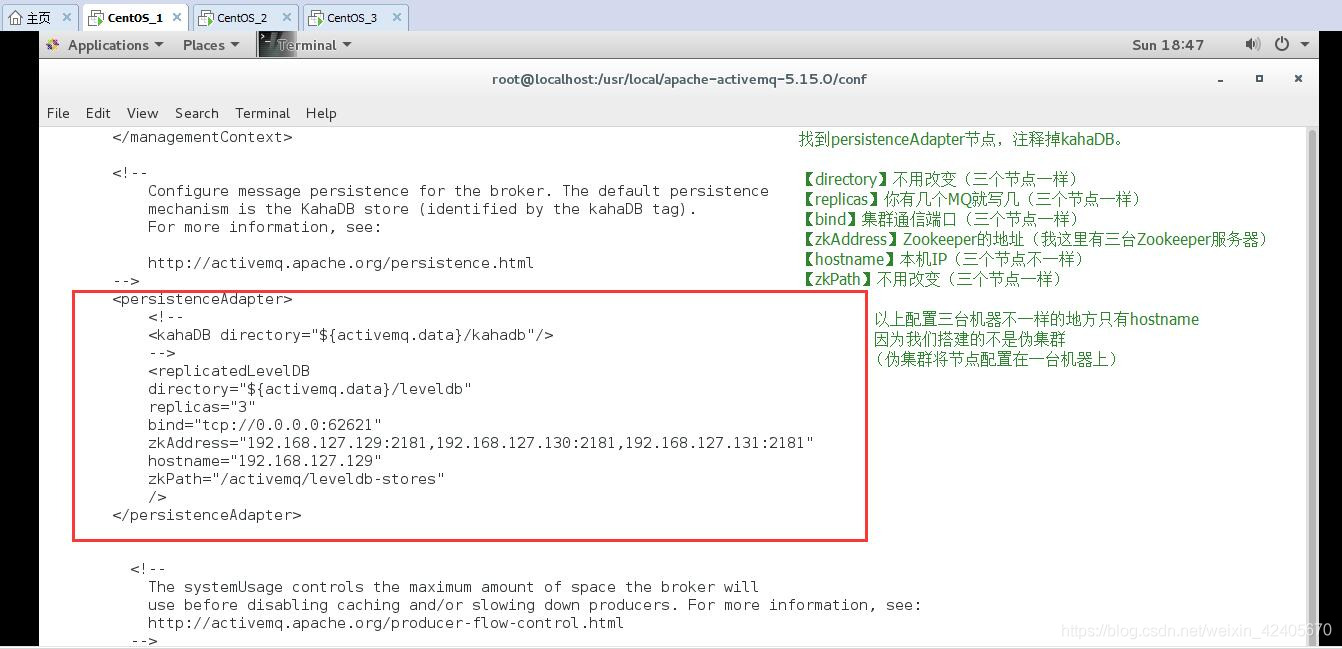
(8)ActiveMQ集群配置
- 配置文件里面的BrokerName要全部一致


2. 持久化配置(必须)
<persistenceAdapter>
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkAddress="192.168.10.130:2181,192.168.10.132:2181,192.168.10.133:2181"
hostname="192.168.10.130"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
(9)修改各个节点的消息端口
02 节点 =》 61617 03 节点 =》 61618

(10)按顺序启动3个ActiveMQ节点,到这步前提是zk集群已经成功启动运行
- 先启动Zk 在启动ActiveMQ
- vim amq_batch.sh
- 想要启动replica leavel DB 必须先启动所有的zookeper 服务,zookeper 的单机伪节点安装这里不细说了,主要说zookeper 复制三份后改配置文件,并让之自动生成 myid 文件,并将zk的端口改为之前表格中对应的端口 。这是conf 下的配置文件

- 其具体配置为:
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2191 // 自行设置
server.1=192.168.17.3:2888:3888
server.2=192.168.17.3:2887:3887
server.3=192.168.17.3:286:3886
dataDir=/zk_server/data/log1 // 自行设置
- 创建批量启动脚本
#!/bin/sh // 注意这个必须写在第一行
cd /zk_server/zk_01/bin
./zkServer.sh start
cd /zk_server/zk_02/bin
./zkServer.sh start
cd /zk_server/zk_03/bin
./zkServer.sh start
编写这个 zk_batch.sh 之后, 使用
chmod 700 zk_batch.sh
命令即可让它变为可执行脚本, ./zk_batch.sh start 即可 (即启动了三个zk 的服务)
同理可以写一个批处理关闭zk 服务的脚本和 批处理开启mq 服务 关闭 mq 服务的脚本。
完成上述之后连接zk 的一个客户端
./zkCli.sh -server 127.0.0.1:2191
(11) zk集群节点状态说明
连接之后:

表示连接成功!
查看我的三个节点: 我的分别是 0…… 3 …… 4 …… 5
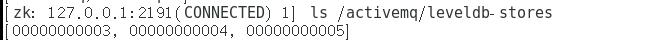
查看我的节点状态
get /activemq/leveldb-stores/00000000003

此次验证表明 00000003 的节点状态是master (即为63631 的那个mq 服务) 而其余的(00000004 00000005) activemq 的节点是 slave
如此集群顺利搭建成功 !

此次测试表明只有 8161 的端口可以使用 经测试只有 61 可以使用,也就是61 代表的就是master

三、测试集群可用性
1、集群可用性
ActiveMQ的客户端只能访问Master的Broker,其他处于Slave的Broker不能访问,所以客户端连接的Broker应该使用failover协议(失败转移)
当一个ActiveMQ节点挂掉或者一个Zookeeper节点挂点,ActiveMQ服务依然正常运转,如果仅剩一个ActiveMQ节点,由于不能选举Master,所以ActiveMQ不能正常运行。
同样的,
如果zookeeper仅剩一个活动节点,不管ActiveMQ各节点存活,ActiveMQ也不能正常提供服务。
(ActiveMQ集群的高可用依赖于Zookeeper集群的高可用)
2、修改代码并测试:
public static final String ACTIVEMQ_URL = "failover:(tcp://192.168.17.3:61616,tcp://192.168.17.3:61617,
tcp://192.168.17.3:61618)?randomize=false";
public static final String QUEUE_NAME = "queue_cluster";
测试:

测试通过连接上集群的 61616
MQ服务收到三条消息:

消息接收
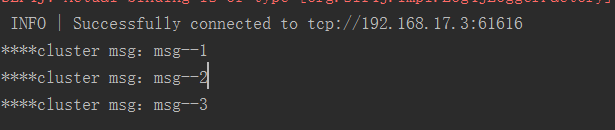
MQ 服务也将消息出队

以上代表集群可以正常使用
3、真正的可用性测试:
杀死 8061 端口的进程 !!!
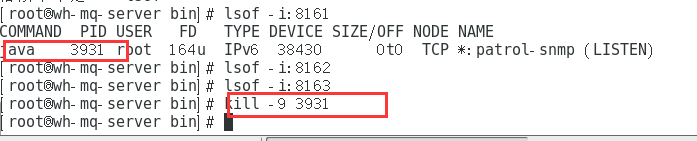
刷新页面后 8161 端口宕掉,但是 8162 端口又激活了


当 61616 宕机,代码不变继续发消息 自动连接到 61617 了

这样! 集群的可用性测试成功!
ActiveMQ 笔记(七)ActiveMQ的多节点集群的更多相关文章
- Hadoop学习笔记(两)设置单节点集群
本文描写叙述怎样设置一个单一节点的 Hadoop 安装.以便您能够高速运行简单的操作,使用 Hadoop MapReduce 和 Hadoop 分布式文件系统 (HDFS). 參考官方文档:Hadoo ...
- Hyperledger Fabric 1.0 从零开始(七)——启动Fabric多节点集群
5:启动Fabric多节点集群 5.1.启动orderer节点服务 上述操作完成后,此时各节点的compose配置文件及证书验证目录都已经准备完成,可以开始尝试启动多机Fabric集群. 首先启动or ...
- CentOS7搭建hadoop2.6.4双节点集群
环境: CentOS7+SunJDK1.8@VMware12. NameNode虚拟机节点主机名:master,IP规划:192.168.23.101,职责:Name node,Secondary n ...
- Hadoop-2.2.0中国文献——MapReduce 下一代 —配置单节点集群
Mapreduce 包 你需从公布页面获得MapReduce tar包.若不能.你要将源代码打成tar包. $ mvn clean install -DskipTests $ cd hadoop-ma ...
- Ambari安装之部署单节点集群
前期博客 大数据领域两大最主流集群管理工具Ambari和Cloudera Manger Ambari架构原理 Ambari安装之Ambari安装前准备(CentOS6.5)(一) Ambari安装之部 ...
- Hyperledger Fabric 1.0 从零开始(六)——创建Fabric多节点集群
4:创建Fabric多节点集群 4.1.配置说明 首先可以根据官方Fabric自带的e2e_cli列子中的集群方案来生成我们自己的集群,与案例不同的是我们需要把容器都分配到不同的服务器上,彼此之间通过 ...
- Nova控制节点集群
#Nova控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html ##Nova控制节点集群 # control ...
- Neutron控制节点集群
#Neutron控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html #.Neutron控制节点集群 #本实 ...
- cinder控制节点集群
#cinder控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html #cinder块存储控制节点.txt.s ...
随机推荐
- openshift 4.3 Istio的搭建(istio 系列一)
openshift 4.3 Istio的搭建 本文档覆盖了官方文档的Setup的所有章节 目录 openshift 4.3 Istio的搭建 安装Istio openshift安装Istio 更新is ...
- SVN 报错问题
svn: error: The subversion command line tools are no longer provided by Xcode ```. ## 问题分析 由于Mac绝大部分 ...
- quartus II Warning 好的时序是设计出来的,不是约束出来的
一.Warning (15714): Some pins have incomplete I/O assignments. Refer to the I/O Assignment Warnings r ...
- HDU 2015 (水)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2015 题目大意:给你个长度为n(n<=100)的数列,该数列定义为从2开始的递增有序偶数,让你按 ...
- javaWeb手动分页步骤
一:编写实体类@Setter@Getter@ToString@Entity@Repositorypublic class PageBean<T> { private Integer cur ...
- Spring全家桶之springMVC(一)
Spring MVC简介和第一个spring MVC程序 Spring MVC是目前企业中使用较多的一个MVC框架,被很多业内人士认为是一个教科书级别的MVC表现层框架,Spring MVC是大名鼎鼎 ...
- 【雕爷学编程】Arduino动手做(49)---有源蜂鸣器模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践(动手试试)出真知的理念,以学习和交流为目的,这里准备 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 统一规范API,包装返回模型
上一篇文章(https://www.cnblogs.com/meowv/p/12916613.html)使用自定义仓储完成了简单的增删改查案例,有心的同学可以看出,我们的返回参数一塌糊涂,显得很不友好 ...
- 08-Python之路---初识函数
Python之路---初识函数️ 程序员三大美德: 懒惰 因为一直致力于减少工作的总工作量. 缺乏耐性 因为一旦让你去做本该计算机完成的事,你将会怒不可遏. 傲慢 因为被荣誉感冲晕头的你会把程序写得让 ...
- storm-redis 详解
多的不说,先来代码分析,再贴我自己写的代码.如果代码有错误,求更正.. 导入两个关键包,其他项目需要的包,大家自己导入了,我pom下的包太多,不好一下扔上来. <dependency> & ...