python set() leetcode 签到820. 单词的压缩编码
题目
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 "#" 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
示例:
输入: words = ["time", "me", "bell"]
输出: 10
说明: S = "time#bell#" , indexes = [0, 2, 5] 。
提示:
1 <= words.length <= 2000
1 <= words[i].length <= 7
每个单词都是小写字母 。
思路
从第二个单词开始,与前一个循环倒着比较。记录相同的计算。
笨比解法,最多通过25/30个样例。基本不可能改好了。心累

还是看看官方代码吧。
代码
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
good = set(words)
for word in words:
for k in range(1, len(word)):
good.discard(word[k:])
return sum(len(word) + 1 for word in good)
链接:https://leetcode-cn.com/problems/short-encoding-of-words/solution/dan-ci-de-ya-suo-bian-ma-by-leetcode-solution/
来源:力扣(LeetCode)
真是又触碰到知识盲区了。

set()方法
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
例:
a='handsome'
print(set(a))
结果:
{'o', 'n', 'h', 's', 'e', 'm', 'a', 'd'}
这个元素集,可以使用,update,remove,add等方法
a='handsome'
b=set(a)
print(b)
b.add('me')
b.update('are')
print(b)
b.update('are')
print(b)
b.remove('are')
print(b)
结果:
{'o', 's', 'e', 'm', 'n', 'a', 'h', 'd'}
{'o', 's', 'e', 'm', 'n', 'r', 'me', 'a', 'h', 'd'}
{'o', 's', 'e', 'm', 'n', 'r', 'me', 'a', 'h', 'd'}
set() discard与remove
discard() 方法用于移除指定的集合元素。
该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
字典树
思路
如方法一所说,目标就是保留所有不是其他单词后缀的单词。
算法
去找到是否不同的单词具有相同的后缀,我们可以将其反序之后插入字典树中。例如,我们有 "time" 和 "me",可以将 "emit" 和 "em" 插入字典树中。
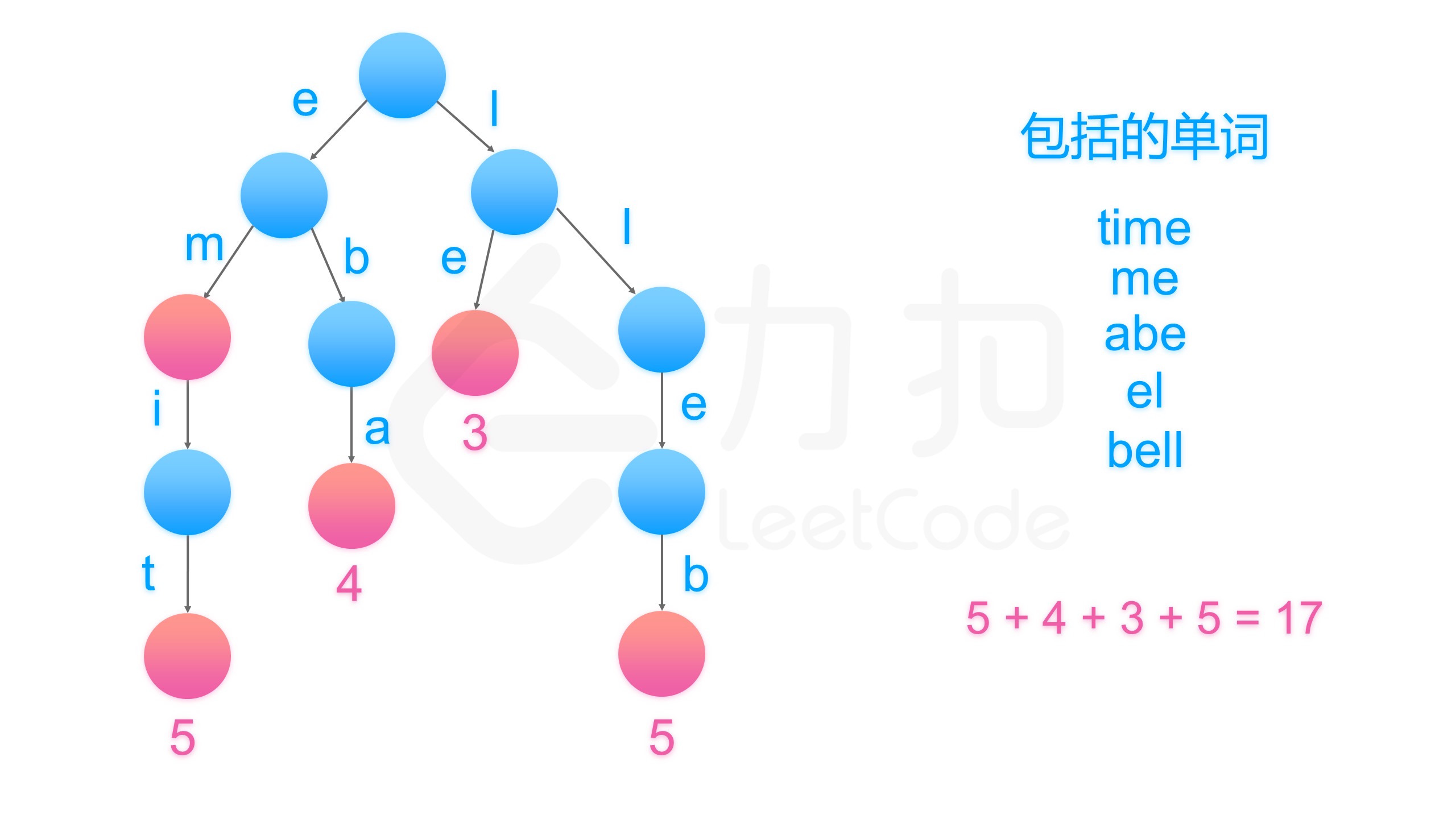
然后,字典树的叶子节点(没有孩子的节点)就代表没有后缀的单词,统计叶子节点代表的单词长度加一的和即为我们要的答案。
链接:https://leetcode-cn.com/problems/short-encoding-of-words/solution/dan-ci-de-ya-suo-bian-ma-by-leetcode-solution/
来源:力扣(LeetCode)
代码
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
words = list(set(words)) #remove duplicates
#Trie is a nested dictionary with nodes created
# when fetched entries are missing
Trie = lambda: collections.defaultdict(Trie)
trie = Trie()
#reduce(..., S, trie) is trie[S[0]][S[1]][S[2]][...][S[S.length - 1]]
nodes = [reduce(dict.__getitem__, word[::-1], trie)
for word in words]
#Add word to the answer if it's node has no neighbors
return sum(len(word) + 1
for i, word in enumerate(words)
if len(nodes[i]) == 0)
python set() leetcode 签到820. 单词的压缩编码的更多相关文章
- leetcode之820. 单词的压缩编码 | python极简实现字典树
题目 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", "bell& ...
- 【LeetCode】820. 单词的压缩编码 Short Encoding of Words(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode-cn.com/problems/short- ...
- Java实现 LeetCode 820 单词的压缩编码(暴力)
820. 单词的压缩编码 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", & ...
- Java实现 LeetCode 820 单词的压缩编码(字典树)
820. 单词的压缩编码 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", & ...
- python统计文本中每个单词出现的次数
.python统计文本中每个单词出现的次数: #coding=utf-8 __author__ = 'zcg' import collections import os with open('abc. ...
- python版 百度签到
经常玩贴吧,刚学python ,所以自己弄了一个python版的签到程序.自己的东西总是最好的. 登陆模块参考的http://www.crifan.com/emulate_login_website_ ...
- Python常见异常及常用单词翻译
Python常见异常及常用单词意思 AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常:基本上是无法打开文件 ImportE ...
- 【python】Leetcode每日一题-寻找旋转排序数组中的最小元素
[python]Leetcode每日一题-寻找旋转排序数组中的最小元素 [题目描述] 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组.例如,原数组nums ...
- 【python】Leetcode每日一题-删除有序数组中的重复项
[python]Leetcode每日一题-删除有序数组中的重复项 [题目描述] 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 最多出现一次 ,返回删除后数组的新长度. 不要 ...
随机推荐
- 《自动化平台测试开发-Python测试开发实战》第2次印刷
书籍货源比较紧张.紧张啊,如此短的时间,已经第2次印刷.第2次印刷. 第2次印刷. 同时该书已确认与台湾出版社合作翻译成繁体版,甚至有可能与国外出版社合作翻译成英文版. 2018年7月 第1次印刷 2 ...
- cpupower frequency 无法设置userspace的问题
Disable intel_pstate in grub configure file: $ sudo vi /etc/default/grub Append "intel_pstate=d ...
- ProjectSend R561 SQL INJ Analysis
注入出现在./client-edit.php中 ...... if (isset($_GET['id'])) { $client_id = mysql_real_escape_string($_GET ...
- Ubuntu19.10安装OMNeT++ (omnetpp-5.6)中遇到的问题
在官网上下载对应版本的安装包,里面有说明性的文档,先在第五章ubuntu那里配置好前期的环境,再到linux那一章,看进行安装,本文即从这里开始记录. 安装包中的文档目录为:omnetpp-5.6/d ...
- 由一个项目需求引发的 - textarea中的换行和空格
当我们使用 textarea 在前台编辑文字,并用 js 提交到后台的时候,空格和换行是我们最需要考虑的问题.在textarea 里面,空格和换行会被保存为/s和/n,如果我们前台输入和前台显示的文字 ...
- 微信WXSS样式文件
目录 WXSS官方文档 1. WXSS 1.1. 尺寸单位 1.2. 样式导入 1.3. 内联样式 1.4. 选择器 1.5. 全局样式与局部样式 WXSS官方文档 https://developer ...
- Redis 中的客户端
Redis 是一个客户端服务端的程序,服务端提供数据存储等等服务,客户端连接服务端并通过向服务端发送命令,读取或写入数据,简单来说,客户端就是某种工具,我们通过它与 Redis 服务端进行通讯并完成数 ...
- linux 读取 USB HID鼠标坐标和点击 在 LCD上显示
首先要,编译内核时启用了 USB HID 设备.启用了 鼠标 . 在开发板上插入usb 时会有如下提示. 可以看到,多了一个 mouse0 和 eventX 打出来的是我的 联想鼠标. 1, 在 终端 ...
- update join和delete join
UPDATE ASET A.A2 = B.B2FROM BINNER JOIN AON A.A1 = B.B1WHERE B.B2 = "XXX" 上面的语句在SQL SERVER ...
- Java 并发系列之一
Java 并发系列之一 简单的总结了一些 Java 常用的集合之后,发现许多集合都针对多线程提供了支持,比如 ConcurrentHashMap 使用分段锁来提高多线程环境下的性能表现与安全表现.所以 ...