Storm入门(四)WordCount示例
一、关联代码
使用maven,代码如下。
pom.xml 和Storm入门(三)HelloWorld示例相同
RandomSentenceSpout.java

/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cn.ljh.storm.wordcount; import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
import java.util.Random; public class RandomSentenceSpout extends BaseRichSpout {
private static final Logger LOG = LoggerFactory.getLogger(RandomSentenceSpout.class); SpoutOutputCollector _collector;
Random _rand; public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
} public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{
sentence("the cow jumped over the moon"),
sentence("an apple a day keeps the doctor away"),
sentence("four score and seven years ago"),
sentence("snow white and the seven dwarfs"),
sentence("i am at two with nature")};
final String sentence = sentences[_rand.nextInt(sentences.length)]; LOG.debug("Emitting tuple: {}", sentence); _collector.emit(new Values(sentence));
} protected String sentence(String input) {
return input;
} @Override
public void ack(Object id) {
} @Override
public void fail(Object id) {
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} // Add unique identifier to each tuple, which is helpful for debugging
public static class TimeStamped extends RandomSentenceSpout {
private final String prefix; public TimeStamped() {
this("");
} public TimeStamped(String prefix) {
this.prefix = prefix;
} protected String sentence(String input) {
return prefix + currentDate() + " " + input;
} private String currentDate() {
return new SimpleDateFormat("yyyy.MM.dd_HH:mm:ss.SSSSSSSSS").format(new Date());
}
}
}
WordCountTopology.java
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cn.ljh.storm.wordcount; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class WordCountTopology {
public static class SplitSentence implements IRichBolt {
private OutputCollector _collector;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} public Map<String, Object> getComponentConfiguration() {
return null;
} public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
} public void execute(Tuple input) {
String sentence = input.getStringByField("word");
String[] words = sentence.split(" ");
for(String word : words){
this._collector.emit(new Values(word));
}
} public void cleanup() {
// TODO Auto-generated method stub }
} public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>(); public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
} public static class WordReport extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>(); public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
this.counts.put(word, count);
} public void declareOutputFields(OutputFieldsDeclarer declarer) { } @Override
public void cleanup() {
System.out.println("-----------------FINAL COUNTS START-----------------------");
List<String> keys = new ArrayList<String>();
keys.addAll(this.counts.keySet());
Collections.sort(keys); for(String key : keys){
System.out.println(key + " : " + this.counts.get(key));
} System.out.println("-----------------FINAL COUNTS END-----------------------");
} } public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); //ShuffleGrouping:随机选择一个Task来发送。
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
//FiledGrouping:根据Tuple中Fields来做一致性hash,相同hash值的Tuple被发送到相同的Task。
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
//GlobalGrouping:所有的Tuple会被发送到某个Bolt中的id最小的那个Task。
builder.setBolt("report", new WordReport(), 6).globalGrouping("count"); Config conf = new Config();
conf.setDebug(true); if (args != null && args.length > 0) {
conf.setNumWorkers(3); StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
else {
conf.setMaxTaskParallelism(3); LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology()); Thread.sleep(20000); cluster.shutdown();
}
}
}
二、执行效果
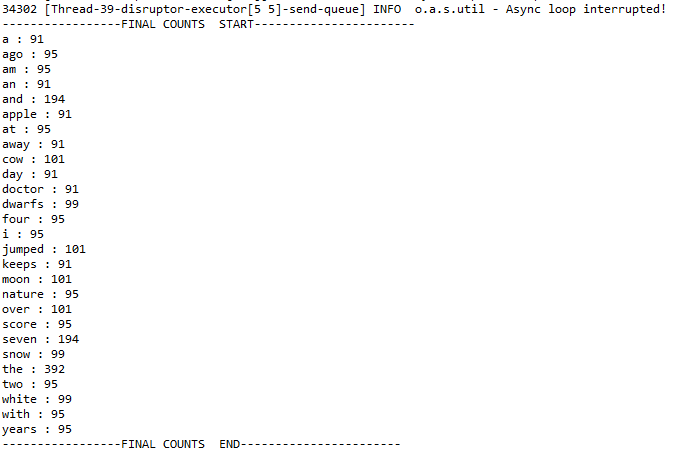
Storm入门(四)WordCount示例的更多相关文章
- 【第四篇】ASP.NET MVC快速入门之完整示例(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 《Storm入门》中文版
本文翻译自<Getting Started With Storm>译者:吴京润 编辑:郭蕾 方腾飞 本书的译文仅限于学习和研究之用,没有原作者和译者的授权不能用于商业用途. 译者序 ...
- 【原创】NIO框架入门(四):Android与MINA2、Netty4的跨平台UDP双向通信实战
概述 本文演示的是一个Android客户端程序,通过UDP协议与两个典型的NIO框架服务端,实现跨平台双向通信的完整Demo. 当前由于NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能. ...
- Storm系列(二):使用Csharp创建你的第一个Storm拓扑(wordcount)
WordCount在大数据领域就像学习一门语言时的hello world,得益于Storm的开源以及Storm.Net.Adapter,现在我们也可以像Java或Python一样,使用Csharp创建 ...
- 脑残式网络编程入门(四):快速理解HTTP/2的服务器推送(Server Push)
本文原作者阮一峰,作者博客:ruanyifeng.com. 1.前言 新一代HTTP/2 协议的主要目的是为了提高网页性能(有关HTTP/2的介绍,请见<从HTTP/0.9到HTTP/2:一文读 ...
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- WordCount示例深度学习MapReduce过程(1)
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功.在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,Wou ...
随机推荐
- Postgresql数据库部署之:Postgresql本机启动和Postgresql注册成windows 服务
1.初始化并创建数据库(一次即可) initdb \data --locale=chs -U postgres -W You can now start the database server u ...
- [Inside HotSpot] C1编译器工作流程及中间表示
1. C1编译器线程 C1编译器(aka Client Compiler)的代码位于hotspot\share\c1.C1编译线程(C1 CompilerThread)会阻塞在任务队列,当发现队列有编 ...
- 从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 二十五║初探SSR服务端渲染(个人博客二)
缘起 时间真快,现在已经是这个系列教程的下半部 Vue 第 12 篇了,昨天我也简单思考了下,可能明天再来一篇,Vue 就基本告一段落了,因为什么呢,这里给大家说个题外话,当时写博文的时候,只是想给大 ...
- 【Linux篇】--awk的使用
一.前述 awk是一个强大的文本分析工具.相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片 ...
- 网络协议 16 - DNS 协议:网络世界的地址簿
[前五篇]系列文章传送门: 网络协议 11 - Socket 编程(下):眼见为实耳听为虚 网络协议 12 - HTTP 协议:常用而不简单 网络协议 13 - HTTPS 协议:加密路上无尽头 网络 ...
- linux下利用nohup后台运行jar文件包程序
Linux 运行jar包命令如下: 方式一: java -jar XXX.jar 特点:当前ssh窗口被锁定,可按CTRL + C打断程序运行,或直接关闭窗口,程序退出 那如何让窗口不锁定? 方式二 ...
- springboot~使用docker构建gradle项目
这是一篇关系到四个知识点的文章,分别是java,docker,springboot和gradle,我们希望在java环境下,使用springboot框架,通过gradle去构建项目,然后把项目部署和运 ...
- springboot~@Valid注解对嵌套类型的校验
@Valid注解可以实现数据的验证,你可以定义实体,在实体的属性上添加校验规则,而在API接收数据时添加@valid关键字,这时你的实体将会开启一个校验的功能,具体的代码如下,是最基本的应用: 实体: ...
- 【Python3爬虫】斗鱼弹幕爬虫
在网上找到了一份斗鱼弹幕服务器第三方接入协议v1.6.2,有了第三方接口,做起来就容易多了. 一.协议分析 斗鱼后台协议头设计如下: 这里的消息长度是我们发送的数据部分的长度和头部的长度之和,两个消息 ...
- DS控件库 DS按钮多种样式
在DS控件库(DSControls)中,DS按钮的功能非常多,通过设置不同的属性值来使按钮呈现不同的效果.DS按钮的常用属性如下: 使用不同的属性调出不同的外观样式示例