python爬虫数据解析之xpath
xpath是一门在xml文档中查找信息的语言。xpath可以用来在xml文档中对元素和属性进行遍历。
在xpath中,有7中类型的节点,元素,属性,文本,命名空间,处理指令,注释及根节点。
节点
首先看下面例子:
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book> </bookstore>
上面的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
父:在上面的例子里,book是title,author,year,price的父。
子:反过来,title,author,year,price是book的子。
同胞:title,author,year,price是同胞。
先辈:title的先辈是book,bookstore。
后代:bookstore的后代是book,tite,author,year,price。
再看一个例子:
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore
如何选取节点呢?
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

对应上面的例子,得到结果:

谓语:谓语用来查找某个特定节点或者包含某个指定值的节点。
比如:
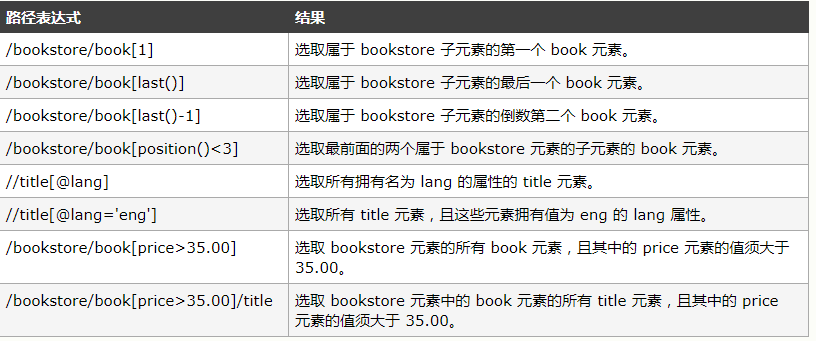
选取未知节点:

比如:

选取若干路径:通过在路径表达式中使用“|”运算符,您可以选取若干个路径。

常用xpath属性:
# 找到class属性为song的div标签
//div[@class="song"]
层级定位:
# 找到class属性为tang的div直系字标签ul下的第二个字标签li下的直系字标签a
//div[@class='tang']/ul/li[2]/a
逻辑运算:
找到class属性为空且href属性为tang的a标签
//a[@class='' and @href='tang']
模糊定位
# 查找class属性值里包含'ng'字符串的div标签
//div[contains(@class, 'ng')]
# 配配class属性以ta为开头的div标签
//div[start_with(@class, 'ta')]
获取文本
//div[@class="song"]/p[1]/text()
获取属性
# 获取class属性为tang的div下的第二个li下面a标签的href属性
//div[@class="tang"]//li[2]/a/@href
在python中应用
将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定节点。
1 本地文件:
tree = etree.parse(文档)
tree.xpath(xpath表达式)
2 网络数据:
tree = etree.HTML(网页字符串)
tree.xpath(xpath表达式)
例子1:随机爬取糗事百科糗图首页的一张图片
import requests
from lxml import etree
import random def main():
# 网页url
url = 'https://www.qiushibaike.com/pic/'
ua_headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
# 网页代码
response = requests.get(url=url, headers=ua_headers).text
# 转换为etree对象
tree = etree.HTML(response)
# 匹配到所有class属性为thumb的div标签下的img标签的src属性值,返回一个列表
img_lst = tree.xpath('//div[@class="thumb"]//img/@src')
# 随机挑选一个图片并且下载下来
res = requests.get(url='https:'+random.choice(img_lst), headers=ua_headers).content
# 将图片保存到本地
with open('image.jpg', 'wb') as f:
f.write(res) if __name__ == '__main__':
main()
例子2:爬取煎蛋网首页的图片
import requests
from lxml import etree def main():
url = 'http://jandan.net/ooxx'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) "
"Version/5.1 Safari/534.50"}
response = requests.get(url=url, headers=headers).text
tree = etree.HTML(response)
img_lst = tree.xpath('//div[@class="text"]//img/@src')
for one_image in img_lst:
res = requests.get(url='http:'+one_image, headers=headers).content
with open('image/' + one_image.split('/')[-1] + '.gif', 'wb') as f:
f.write(res) if __name__ == '__main__':
main()
python爬虫数据解析之xpath的更多相关文章
- python爬虫--数据解析
数据解析 什么是数据解析及作用 概念:就是将一组数据中的局部数据进行提取 作用:来实现聚焦爬虫 数据解析的通用原理 标签定位 取文本或者属性 正则解析 正则回顾 单字符: . : 除换行以外所有字符 ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- python爬虫数据解析的四种不同选择器Xpath,Beautiful Soup,pyquery,re
这里主要是做一个关于数据爬取以后的数据解析功能的整合,方便查阅,以防混淆 主要讲到的技术有Xpath,BeautifulSoup,PyQuery,re(正则) 首先举出两个作示例的代码,方便后面举例 ...
- python爬虫数据解析之正则表达式
爬虫的一般分为四步,第二个步骤就是对爬取的数据进行解析. python爬虫一般使用三种解析方式,一正则表达式,二xpath,三BeautifulSoup. 这篇博客主要记录下正则表达式的使用. 正则表 ...
- 070.Python聚焦爬虫数据解析
一 聚焦爬虫数据解析 1.1 基本介绍 聚焦爬虫的编码流程 指定url 基于requests模块发起请求 获取响应对象中的数据 数据解析 进行持久化存储 如何实现数据解析 三种数据解析方式 正则表达式 ...
- python爬虫+数据可视化项目(关注、持续更新)
python爬虫+数据可视化项目(一) 爬取目标:中国天气网(起始url:http://www.weather.com.cn/textFC/hb.shtml#) 爬取内容:全国实时温度最低的十个城市气 ...
- python 爬虫数据存入csv格式方法
python 爬虫数据存入csv格式方法 命令存储方式:scrapy crawl ju -o ju.csv 第一种方法:with open("F:/book_top250.csv" ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
随机推荐
- 在腾讯云(windows)上搭建node.js服务器
1:安装Node.js 使用MSI文件,并按照提示安装node.js,默认情况下,安装程序将 Node.js 发行到 C:\Program Files\nodejs. 但这里我们需要修改安装路径到:D ...
- jQuery学习之旅 Item4 细说DOM操作
jQuery-–DOM操作(文档处理) Dom是Document Object Model的缩写,意思是文档对象模型.DOM是一种与浏览器.平台.语言无关的接口,使用该接口可以轻松访问页面中所有的标准 ...
- Android 实现个性的ViewPager切换动画 实战PageTransformer(兼容Android3.0以下)
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/40411921,本文出自:[张鸿洋的博客] 1.概述 之前写过一篇博文:Andro ...
- engine_init_options.go
package ) type { options.PersistentStorageShards = defaultPersistentStorageShards } }
- BZOJ_3524_[Poi2014]Couriers_主席树
BZOJ_3524_[Poi2014]Couriers_主席树 题意:给一个长度为n的序列a.1≤a[i]≤n. m组询问,每次询问一个区间[l,r],是否存在一个数在[l,r]中出现的次数大于(r- ...
- BZOJ_1800_[Ahoi2009]fly 飞行棋_乱搞
BZOJ_1800_[Ahoi2009]fly 飞行棋_乱搞 Description 给出圆周上的若干个点,已知点与点之间的弧长,其值均为正整数,并依圆周顺序排列. 请找出这些点中有没有可以围成矩形的 ...
- Spring IOC(二)容器初始化
本系列目录: Spring IOC(一)概览 Spring IOC(二)容器初始化 Spring IOC(三)依赖注入 Spring IOC(四)总结 目录 一.ApplicationContext接 ...
- C#进度框
1.方法一:使用线程 功能描述:在用c#做WinFrom开发的过程中.我们经常需要用到进度条(ProgressBar)用于显示进度信息.这时候我们可能就需要用到多线程,如果不采用多线程控制进度条,窗口 ...
- VMware workstation创建虚拟机console
1. 使用VMware workstation创建虚拟机硬件2. 安装操作系统3. 操作系统安装过程 1. 使用VMware workstation创建虚拟机硬件 使用VMware workstati ...
- Pandas 错误笔记(持续更新)
更新至2018.5.1 字典生成DataFrame 今天一个字典生成一个DataFrame,采用了以下形式,每一个value都是一个数(不是vector) df = pd.DataFrame({ 'i ...