java爬虫系列第四讲-采集"极客时间"专栏文章、视频专辑
1.概述
极客时间(https://time.geekbang.org/),想必大家都知道的,上面有很多值得大家学习的课程,如下图:
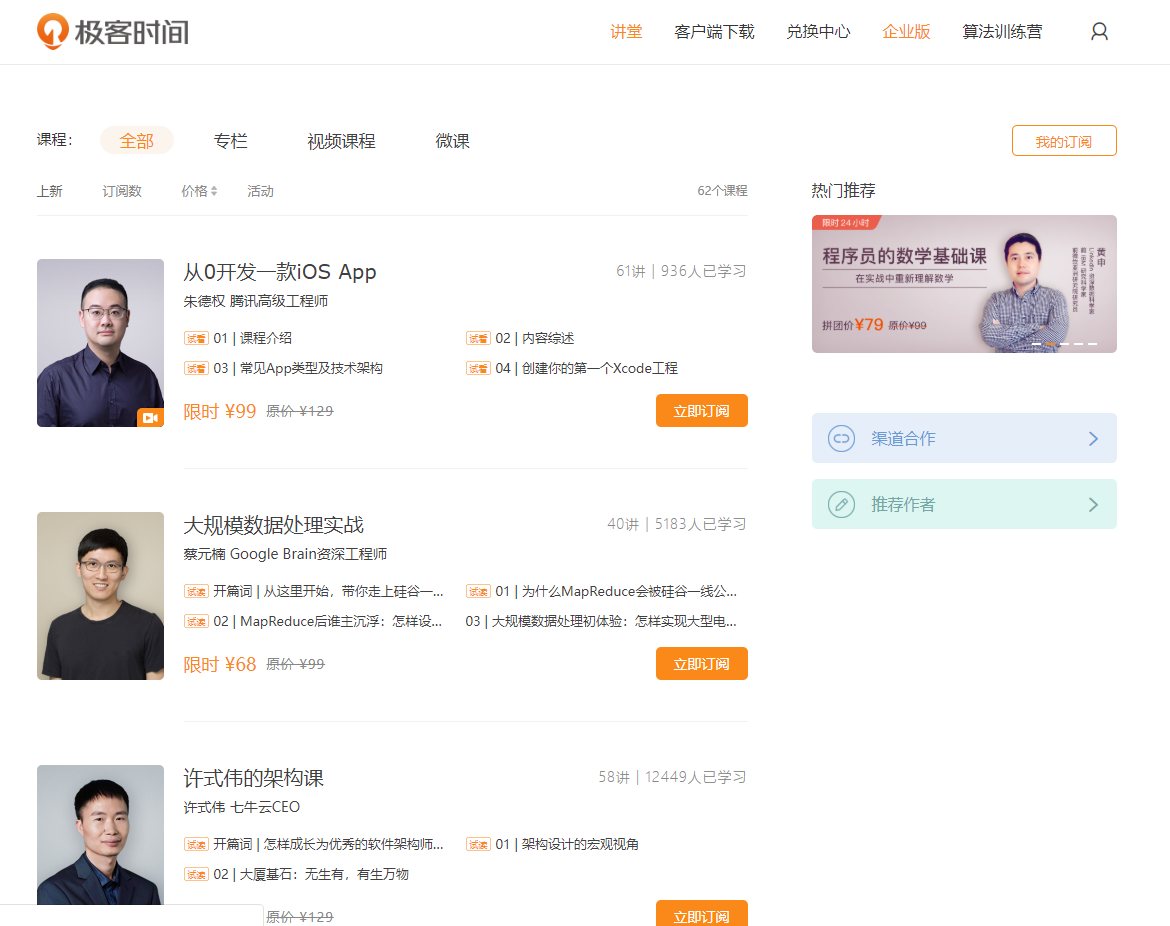
本文主要内容
使用webmagic采集极客时间中某个专栏课程生成html
使用webmagic采集视频课程的文件到本地
直接看一下最终效果图
专栏课程生成本地html
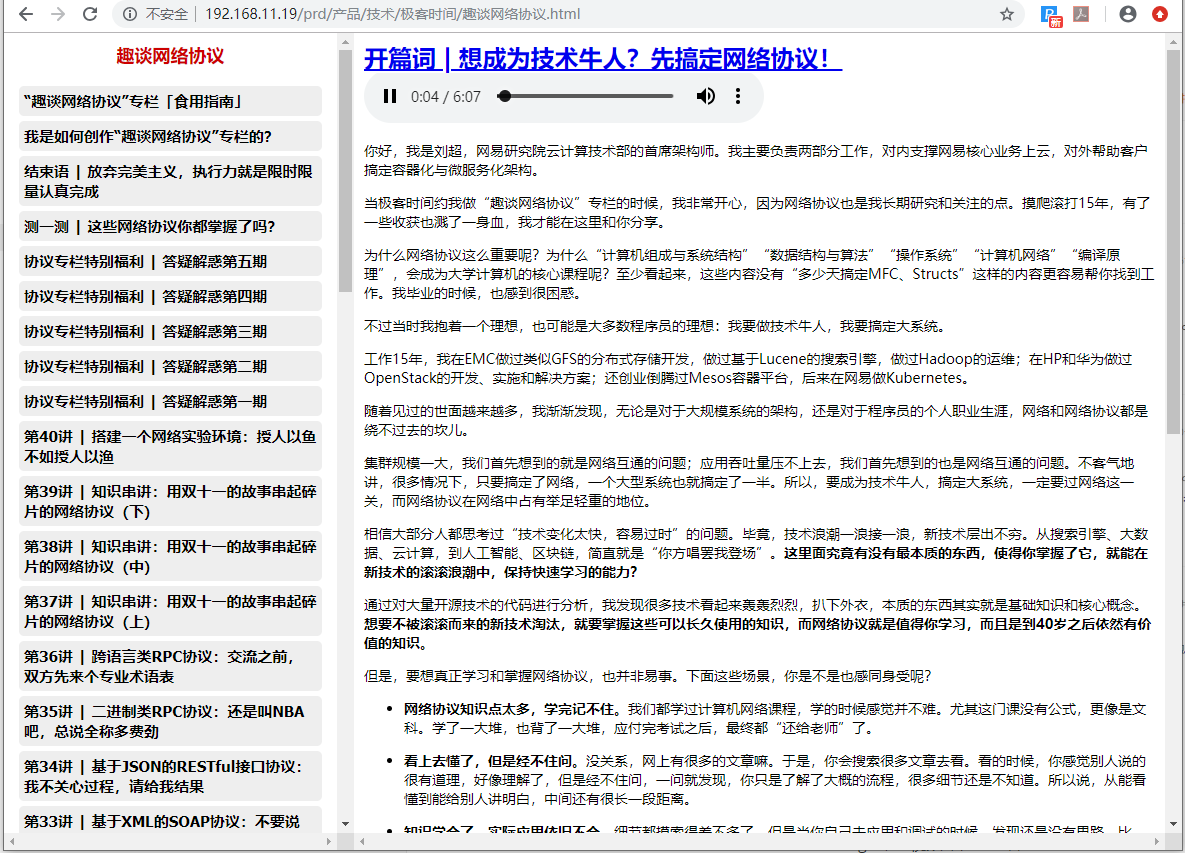
视频课程中的视频文件采集到本地
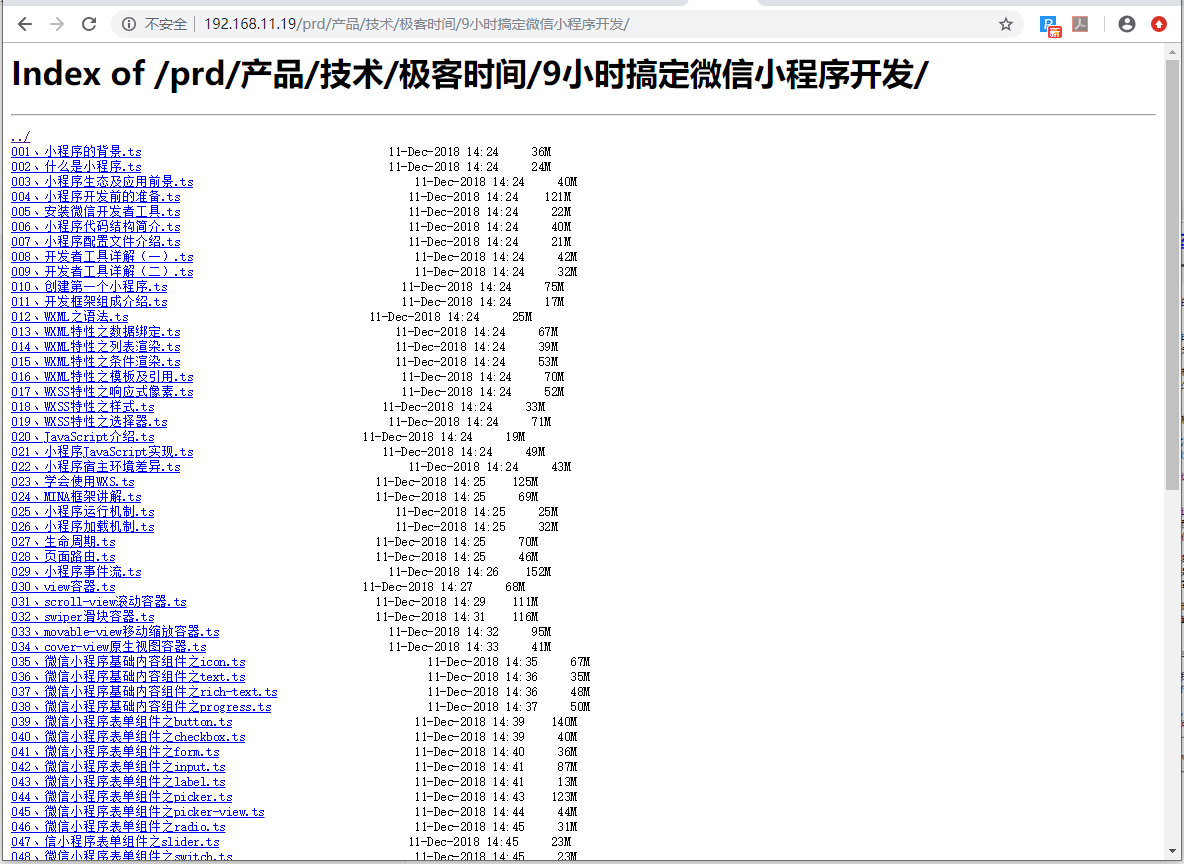
2.专栏课程视频采集
大家请先买某个课程,然后才可以采集
1.登录极客时间
登录地址: https://time.geekbang.org/
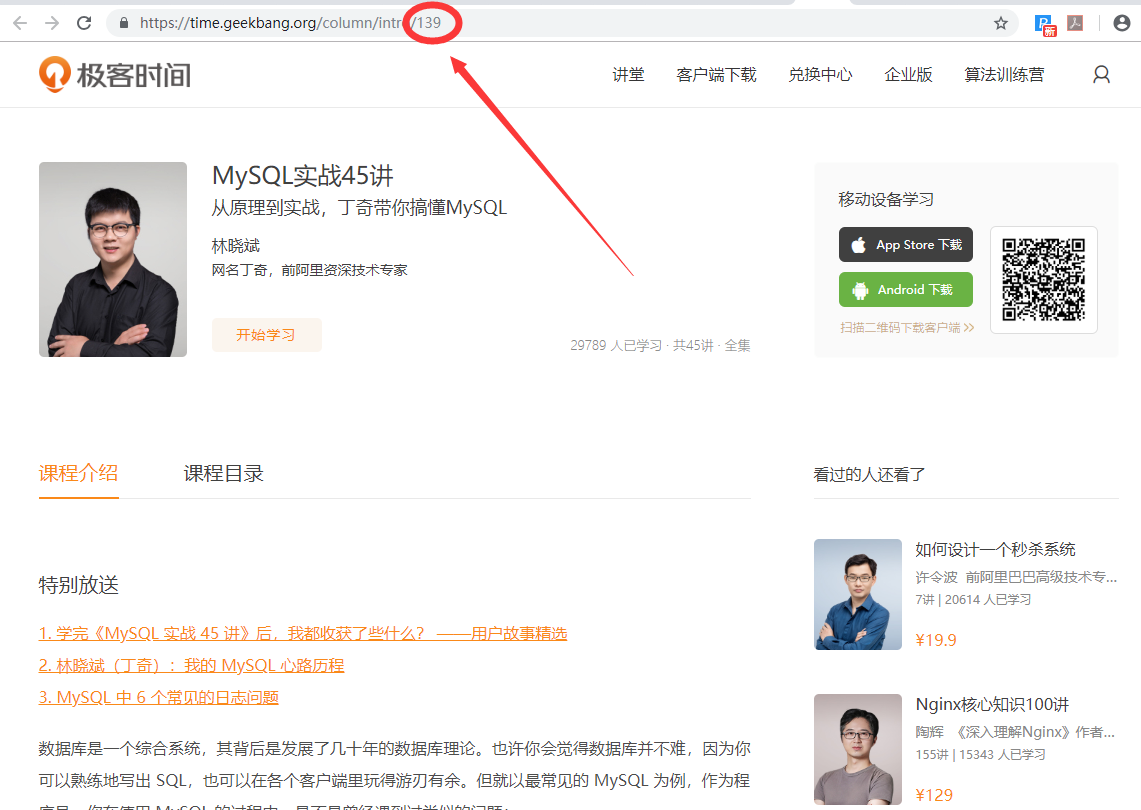
2.极客时间中获取专栏id
3.获取cookie
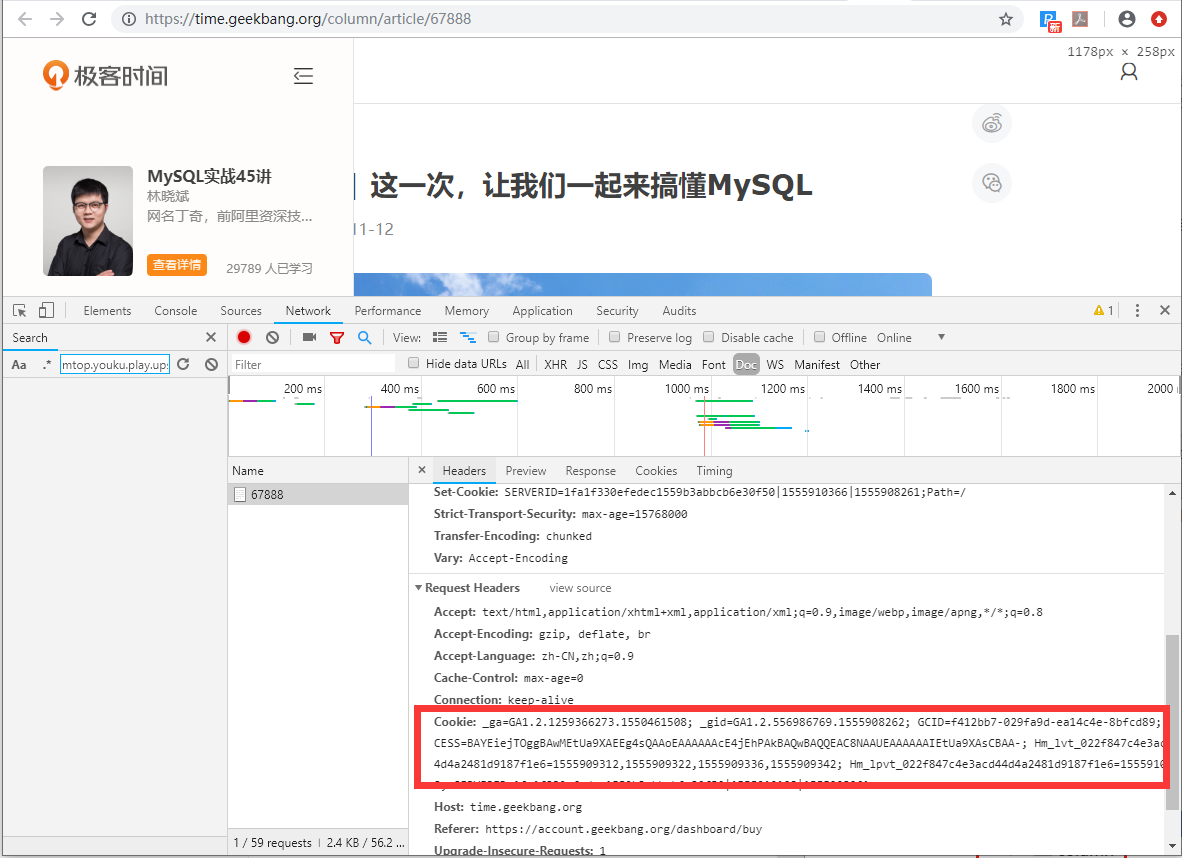
cookie 中存储了当前账号的登录凭证,采集数据的时候需要用到这些信息系,在chrome浏览器中按F12可以获取到cookie信息,如下图:
4.获取专栏采集器代码
采集代码比较多,已上传至gitee:https://gitee.com/likun_557/java-pachong
5.将代码导入idea中

6.打开代码,设置cookie
修改com.ady01.demo4.jksj.util.CollectorUtil类中**COOKIE_VALUE*的值替换为你的cookie
public static final String COOKIE_VALUE = "_ga=GA1.2.1259366273.1550461508; _gid=GA1.2.556986769.1555908262; GCID=f412bb7-029";7.设置需要采集的专栏id
修改com.ady01.demo4.jksj.util.CollectorUtilTest中的 cid 的值
@Test
public void articleList() throws Exception {
//需要采集的专栏id
long cid = 139L;
ColumnDto columnDto = CollectorUtil.articleList(cid);
ColumnCollectorResponse columnCollectorResponse = columnDto.getColumnCollectorResponse();
List<ArticleCollectorResponse> articleCollectorResponseList = columnDto.getArticleCollectorResponseList();
String articleCollectorResponseListJson = FrameUtil.json(articleCollectorResponseList, true);
log.info("articleCollectorResponseList:{}", articleCollectorResponseListJson);
String s = FreemarkerUtil.getFtlToString("column",
FrameUtil.newHashMap(
"articleCollectorResponseListJson", articleCollectorResponseListJson,
"columnCollectorResponse", columnCollectorResponse));
//将采集生成的html保存到本地
FileUtils.write(new File("D:\\极客时间\\" + columnCollectorResponse.getColumn_title() + ".html"), s, "utf-8");
}8.运行代码
执行com.ady01.demo4.jksj.util.CollectorUtilTest中的articleList方法,采集成功

生成的文件

浏览器中打开

3.视频专辑采集
1.打开代码,设置cookie
修改com.ady01.demo4.jksjvideo.util.CollectorUtil类中**COOKIE_VALUE*的值替换为你的cookie
public static final String COOKIE_VALUE = "_ga=GA1.2.1259366273.1550461508; _gid=GA1.2.556986769.1555908262; GCID=f412bb7-029";2.设置需要采集的专栏id
修改com.ady01.demo4.jksjvideo.util.CollectorUtilTest中的 cid 的值
@Test
public void saveCourseDto() throws IOException {
//视频保存的地址
String saveDir = "D:\\极客时间\\%s";
//视频课程id
Long cid = 160L;
CourseDto courseDto = CollectorUtil.courseDto(cid);
log.info("courseDto:{}", FrameUtil.json(courseDto, true));
for (ArticleCollectorResponse articleCollectorResponse : courseDto.getArticleCollectorResponseList()) {
try {
String dir = String.format(saveDir + "\\%s", courseDto.getCourseCollectorResponse().getColumn_title(), articleCollectorResponse.getId());
CollectorUtil.saveFile(articleCollectorResponse, dir);
} catch (IOException e) {
log.error(e.getMessage(), e);
}
}
int i = 1;
for (ArticleCollectorResponse articleCollectorResponse : courseDto.getArticleCollectorResponseList()) {
File file = new File(String.format(saveDir + "\\%s", courseDto.getCourseCollectorResponse().getColumn_title(), articleCollectorResponse.getId()), String.format("%s.%s", articleCollectorResponse.getId(), ".ts"));
String s = FrameUtil.generateCode(i + "", 3, "0", true);
File newFile = new File(String.format(saveDir + "\\video", courseDto.getCourseCollectorResponse().getColumn_title()),
String.format("%s、%s.%s", s, articleCollectorResponse.getArticle_title().substring(articleCollectorResponse.getArticle_title().indexOf("|") + 2), "ts").replaceAll("\\?", ""));
FileUtils.copyFile(file, newFile);
i++;
}
}3.运行代码
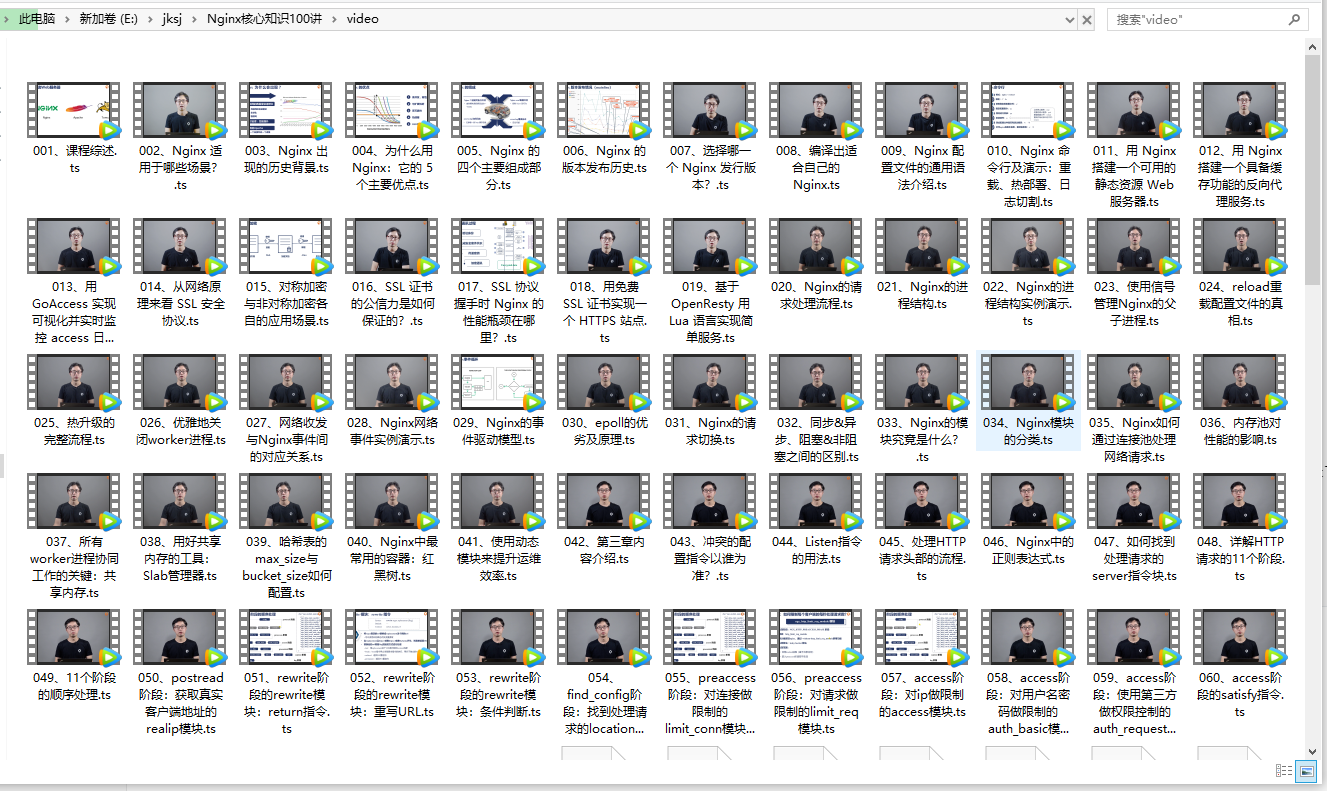
执行com.ady01.demo4.jksjvideo.util.CollectorUtilTest中的saveCourseDto方法,采集成功
4.获取源码
关注公众号:路人甲Java,发送“极客时间”,获取视频采集的源码
java爬虫系列第四讲-采集"极客时间"专栏文章、视频专辑的更多相关文章
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
- java并发编程实践——王宝令(极客时间)学习笔记
1.并发 分工:如何高效地拆解任务并分配给线程 同步:线程之间如何协作 互斥:保证同一时刻只允许一个线程访问共享资源 Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容.上一篇随笔<Java爬虫系列一:写在开始前>中提到了HttpClient可以抓取页面内 ...
- Java Thread系列(四)线程通信
Java Thread系列(四)线程通信 一.传统通信 public static void main(String[] args) { //volatile实现两个线程间数据可见性 private ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
随机推荐
- 用原生JS从零到一实现Redux架构
前言 最近利用业余时间阅读了胡子大哈写的<React小书>,从基本的原理讲解了React,Redux等等受益颇丰.眼过千遍不如手写一遍,跟着作者的思路以及参考代码可以实现基本的Demo,下 ...
- CentOS 本地和网络yum源简单说明及配置
1.简述 Yellow dog Updater, Modified由Duke University团队,修改Yellow Dog Linux的Yellow Dog Updater开发而成,是一个基于R ...
- python --- 快速排序算法
在快速排序中引入递归和分治的概念(关于递归和分治的概念会单独写一篇来进行介绍) 问的解决思路: 快速排序的基本思想本身就是分治法,通过分割,将无序序列分成两部分,其中前一部分的元素值都要小于后一部分的 ...
- ASP.NET Core在CentOS上的最小化部署实践
引言 本文从Linux小白的视角, 在CentOS 7.x服务器上搭建一个Nginx-Powered AspNet Core Web准生产应用. 在开始之前,我们还是重温一下部署原理,正 ...
- 死磕 java集合之LinkedBlockingQueue源码分析
问题 (1)LinkedBlockingQueue的实现方式? (2)LinkedBlockingQueue是有界的还是无界的队列? (3)LinkedBlockingQueue相比ArrayBloc ...
- Firemonkey 原生二维码扫描优化
之前用了ZXing的Delphi版本,运行自带的例子,速度非常慢,与安卓版本的相比查了很多,因此打算使用集成jar的方法,但是总觉得美中不足. 经过一番研究,基本上解决了问题. 主要有两方面的优化: ...
- 用wGenerator给编程提速
1.需求设定 开发语言: java 数据库: mysql 持久化: mybatis 模式: mvc 视图引擎: thymeleaf 前端框架: bootstrap4 用以上的组合来开发一个公告管理的列 ...
- 实时语音趣味变声,大叔变声“妙音娘子”Get一下
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯游戏云 发表于云+社区专栏 游戏社交化是近年来游戏行业发展的重要趋势,如何提高游戏的社交属性已成为各大游戏厂商游戏策划的重要组成部 ...
- ACM入门之OJ~
所谓OJ,顾名思义Online Judge,一个用户提交的程序在Online Judge系统下执行时将受到比较严格的限制,包括运行时间限制,内存使用限制和安全限制等.用户程序执行的结果将被Online ...
- 结合JDK源码看设计模式——适配器模式
定义: 将一个类的接口转换成客户期望的另外一个接口(重点理解适配的这两个字),使得接口不兼容的类可以一起工作适用场景: 已经存在的类,它的方法和需求不匹配的时候 在软件维护阶段考虑的设计模式 详解 首 ...