java爬虫系列第四讲-采集"极客时间"专栏文章、视频专辑
1.概述
极客时间(https://time.geekbang.org/),想必大家都知道的,上面有很多值得大家学习的课程,如下图:
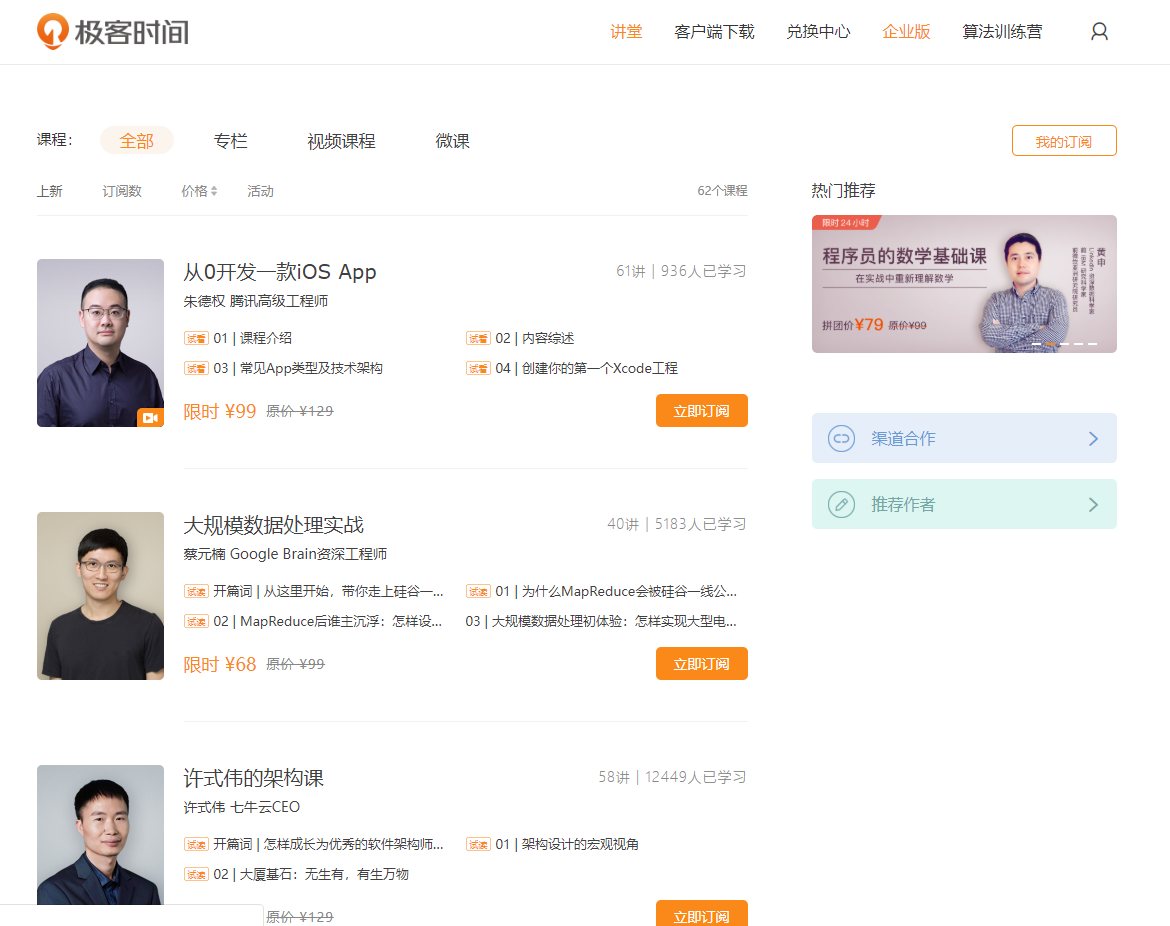
本文主要内容
使用webmagic采集极客时间中某个专栏课程生成html
使用webmagic采集视频课程的文件到本地
直接看一下最终效果图
专栏课程生成本地html
视频课程中的视频文件采集到本地
2.专栏课程视频采集
大家请先买某个课程,然后才可以采集
1.登录极客时间
登录地址: https://time.geekbang.org/
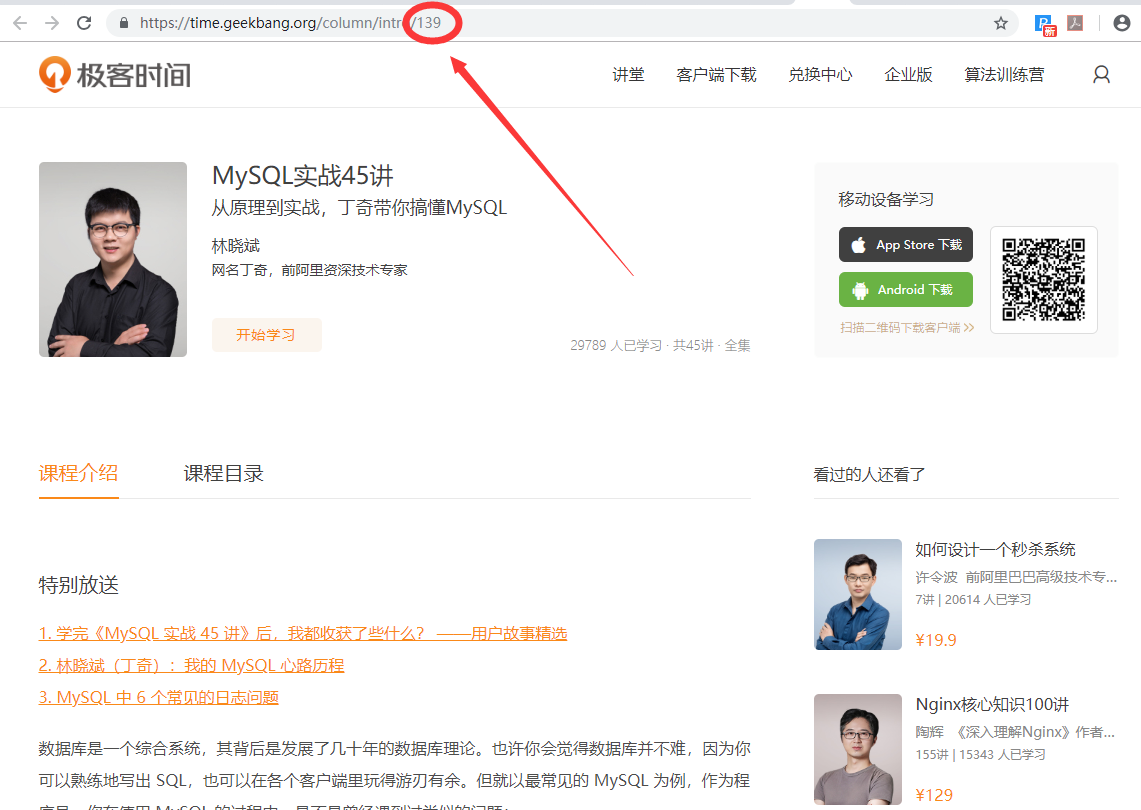
2.极客时间中获取专栏id
3.获取cookie
cookie 中存储了当前账号的登录凭证,采集数据的时候需要用到这些信息系,在chrome浏览器中按F12可以获取到cookie信息,如下图:
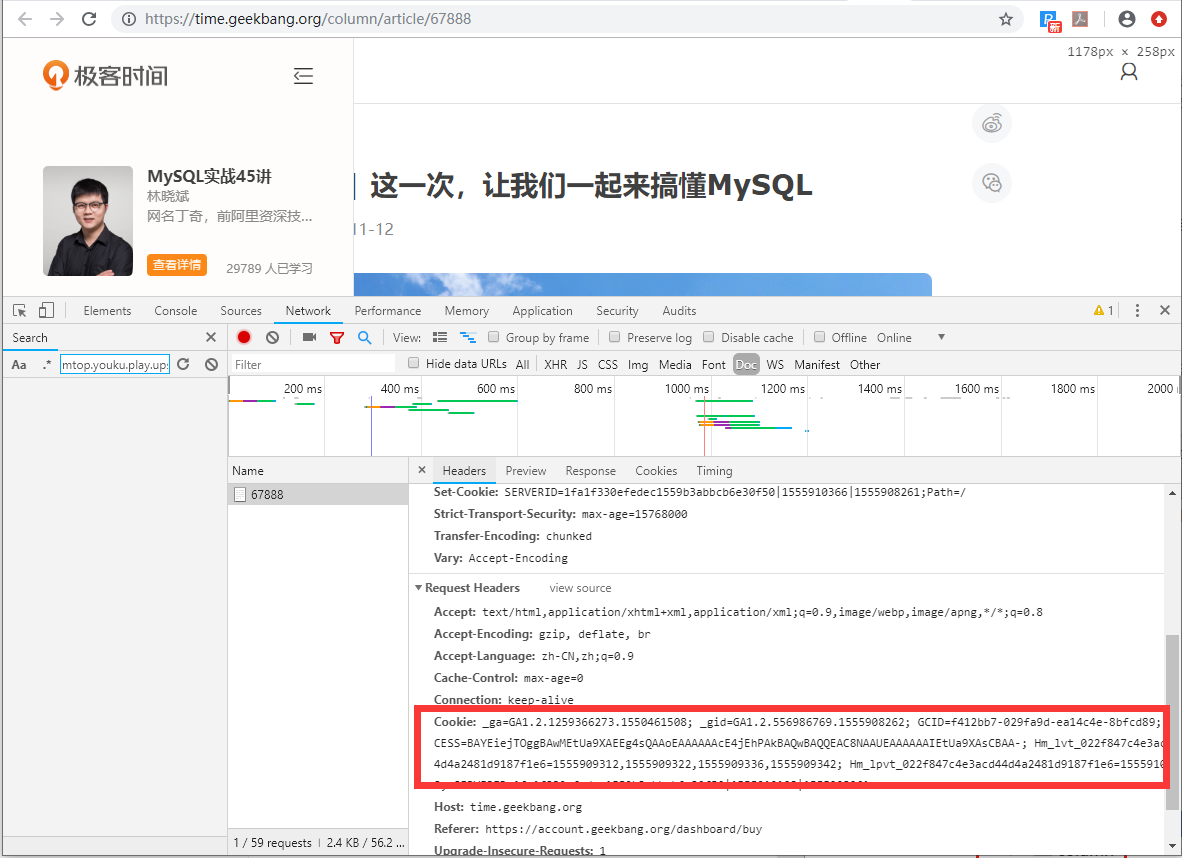
4.获取专栏采集器代码
采集代码比较多,已上传至gitee:https://gitee.com/likun_557/java-pachong
5.将代码导入idea中

6.打开代码,设置cookie
修改com.ady01.demo4.jksj.util.CollectorUtil类中**COOKIE_VALUE*的值替换为你的cookie
public static final String COOKIE_VALUE = "_ga=GA1.2.1259366273.1550461508; _gid=GA1.2.556986769.1555908262; GCID=f412bb7-029";7.设置需要采集的专栏id
修改com.ady01.demo4.jksj.util.CollectorUtilTest中的 cid 的值
@Test
public void articleList() throws Exception {
//需要采集的专栏id
long cid = 139L;
ColumnDto columnDto = CollectorUtil.articleList(cid);
ColumnCollectorResponse columnCollectorResponse = columnDto.getColumnCollectorResponse();
List<ArticleCollectorResponse> articleCollectorResponseList = columnDto.getArticleCollectorResponseList();
String articleCollectorResponseListJson = FrameUtil.json(articleCollectorResponseList, true);
log.info("articleCollectorResponseList:{}", articleCollectorResponseListJson);
String s = FreemarkerUtil.getFtlToString("column",
FrameUtil.newHashMap(
"articleCollectorResponseListJson", articleCollectorResponseListJson,
"columnCollectorResponse", columnCollectorResponse));
//将采集生成的html保存到本地
FileUtils.write(new File("D:\\极客时间\\" + columnCollectorResponse.getColumn_title() + ".html"), s, "utf-8");
}8.运行代码
执行com.ady01.demo4.jksj.util.CollectorUtilTest中的articleList方法,采集成功

生成的文件

浏览器中打开

3.视频专辑采集
1.打开代码,设置cookie
修改com.ady01.demo4.jksjvideo.util.CollectorUtil类中**COOKIE_VALUE*的值替换为你的cookie
public static final String COOKIE_VALUE = "_ga=GA1.2.1259366273.1550461508; _gid=GA1.2.556986769.1555908262; GCID=f412bb7-029";2.设置需要采集的专栏id
修改com.ady01.demo4.jksjvideo.util.CollectorUtilTest中的 cid 的值
@Test
public void saveCourseDto() throws IOException {
//视频保存的地址
String saveDir = "D:\\极客时间\\%s";
//视频课程id
Long cid = 160L;
CourseDto courseDto = CollectorUtil.courseDto(cid);
log.info("courseDto:{}", FrameUtil.json(courseDto, true));
for (ArticleCollectorResponse articleCollectorResponse : courseDto.getArticleCollectorResponseList()) {
try {
String dir = String.format(saveDir + "\\%s", courseDto.getCourseCollectorResponse().getColumn_title(), articleCollectorResponse.getId());
CollectorUtil.saveFile(articleCollectorResponse, dir);
} catch (IOException e) {
log.error(e.getMessage(), e);
}
}
int i = 1;
for (ArticleCollectorResponse articleCollectorResponse : courseDto.getArticleCollectorResponseList()) {
File file = new File(String.format(saveDir + "\\%s", courseDto.getCourseCollectorResponse().getColumn_title(), articleCollectorResponse.getId()), String.format("%s.%s", articleCollectorResponse.getId(), ".ts"));
String s = FrameUtil.generateCode(i + "", 3, "0", true);
File newFile = new File(String.format(saveDir + "\\video", courseDto.getCourseCollectorResponse().getColumn_title()),
String.format("%s、%s.%s", s, articleCollectorResponse.getArticle_title().substring(articleCollectorResponse.getArticle_title().indexOf("|") + 2), "ts").replaceAll("\\?", ""));
FileUtils.copyFile(file, newFile);
i++;
}
}3.运行代码
执行com.ady01.demo4.jksjvideo.util.CollectorUtilTest中的saveCourseDto方法,采集成功
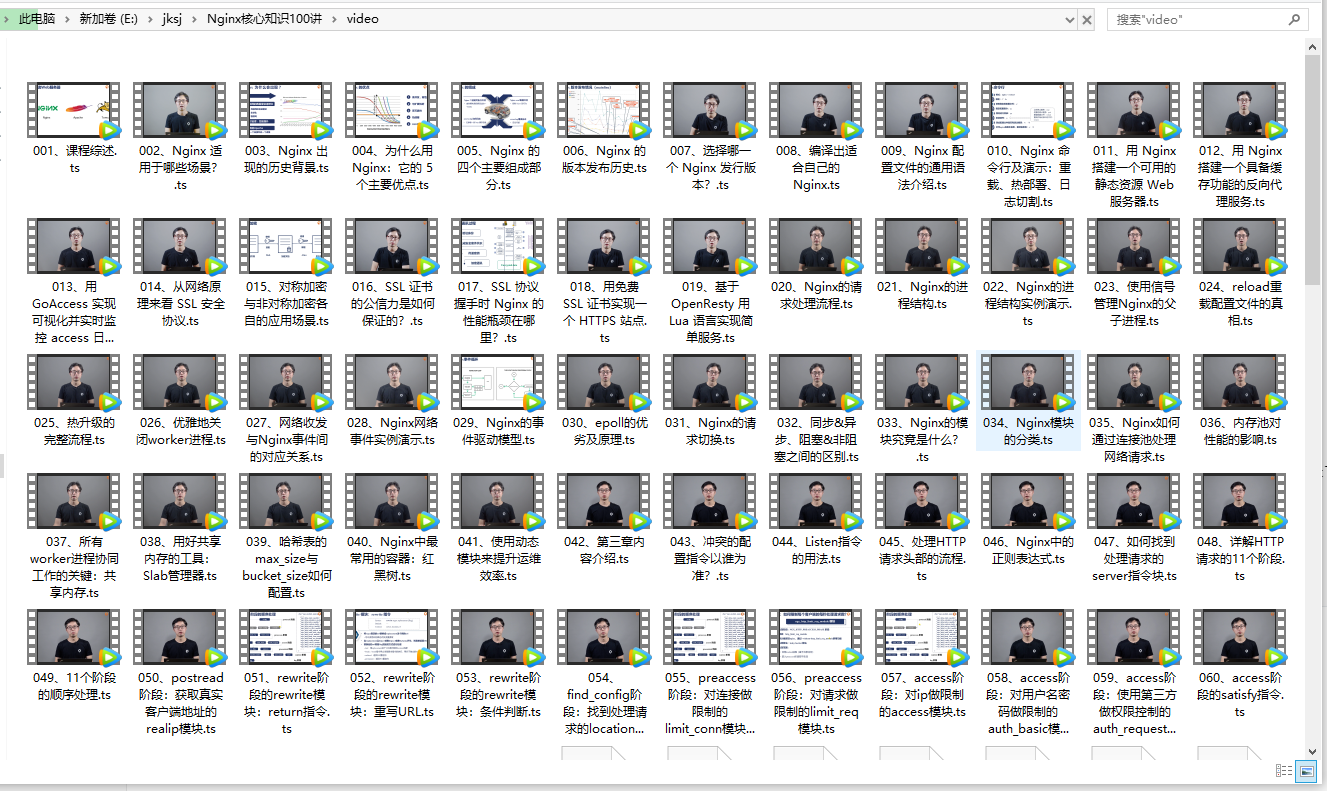
4.获取源码
关注公众号:路人甲Java,发送“极客时间”,获取视频采集的源码
java爬虫系列第四讲-采集"极客时间"专栏文章、视频专辑的更多相关文章
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
- java并发编程实践——王宝令(极客时间)学习笔记
1.并发 分工:如何高效地拆解任务并分配给线程 同步:线程之间如何协作 互斥:保证同一时刻只允许一个线程访问共享资源 Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容.上一篇随笔<Java爬虫系列一:写在开始前>中提到了HttpClient可以抓取页面内 ...
- Java Thread系列(四)线程通信
Java Thread系列(四)线程通信 一.传统通信 public static void main(String[] args) { //volatile实现两个线程间数据可见性 private ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
随机推荐
- Python GIL(Global Interpreter Lock)
一,介绍 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native t ...
- 挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html DBSCAN(Density-Based Spatial Clu ...
- SpringSecurityOauth RCE (CVE-2016-4977) 分析与复现
目录 0x00 前言 0x01 调试分析 0x02 补丁分析 0x03 参考 影响版本: 2.0.0-2.0.9 1.0.0-1.0.5 0x00 前言 这个漏洞与之前那个SpringBoot的SpE ...
- Python猫荐书系列之五:Python高性能编程
稍微关心编程语言的使用趋势的人都知道,最近几年,国内最火的两种语言非 Python 与 Go 莫属,于是,隔三差五就会有人问:这两种语言谁更厉害/好找工作/高工资…… 对于编程语言的争论,就是猿界的生 ...
- renren-fast开源项目解析日志—1、项目的部署
renren_fast项目解析日志 一.环境搭建 1.后端部署 (1)下载源码 按照步骤,从码云上down了fast,zip的(引maven项目)项目包. (2)安装lombok插件 安装lombok ...
- Javaoop 遇到的问题
一.java 异常的捕获与处理 (免责声明:本博客里所引用的他人博客链接,只用作我个人的学习,同时非常感谢这些作者!) 1. https://blog.csdn.net/wei_zhi/articl ...
- 【原】无脑操作:Chrome浏览器安装Vue.js devtool
学习Vue.js时,Chrome浏览器安装Vue.js devtool能很方便的查看Vue对象.组件.事件等. 本文以Chrome浏览器插件Vue.js devtools_3.1.2_0.crx的安装 ...
- 判断HTML中的checkbox是否被选中
//合法性验证 function checkValidity() { var userNameCheck = $("#userNameCheck").attr('checked') ...
- eShopOnContainers 知多少[1]:总体概览
引言 在微服务大行其道的今天,Java阵营的Spring Boot.Spring Cloud.Dubbo微服务框架可谓是风水水起,也不得不感慨Java的生态圈的火爆.反观国内.NET阵营,微服务却不愠 ...
- JavaScript正则表达式基础
ECMAScript 3 开始支持正则表达式,其语法和 Perl 语法很类似,一个完整的正则表达式结构如下: var expression = / pattern / flags ; 其中,模式(pa ...