GIS大数据存储预研
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
1. 背景
在实际项目运行中,时常会出现希望搜索周边所有数据的需求。但是以常规的存储方案,每种资源均为一个图层或一个表,比如人员轨迹表、车辆轨迹表、各类空间图层表等。在进行全文空间收索时,基于传统空间关系库或后台图层服务的遍历查询则过于耗时。这里,我们研究基于ElasticSearch来进行所有数据的整合,以及全文查询服务的提供,并且分别从查询效率、查询精度、查询类型、存储空间四个维度来进行方案的验证。
2.实验数据准备
试验数据包含5个行政面图层、3个线图层(一、二、三级道路中心线)以及75个点图层。一共83个图层。
3.存储设计和对比
a.一个shp对应一个索引。索引中记录shp图层的属性信息和几何信息。
b.增加wkt字段以保存原始坐标。由于ES的空间查询仅支持wgs84坐标,在导入数据时我们将即利用wkt字段保留原始坐标,而es的location字段则保存转换后的wgs84坐标数据结构设计:
以下为点、线、面的存储结构:

点
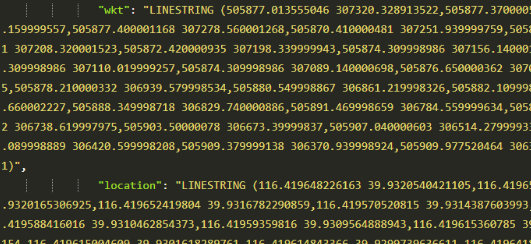
线
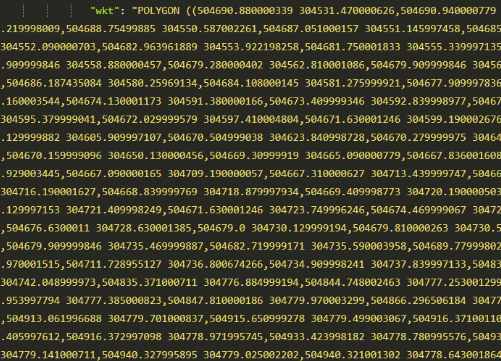
面
83张图层的占用存储空间变化:
|
表名 |
Shp大小 |
储存占用空间 |
|
灯 |
9.91mb |
3.3mb |
行道树 |
25.3mb |
8.3mb |
|
X1井盖 |
23.6mb |
7.7mb |
|
X2井盖 |
24.1kb |
10kb |
|
X3井盖 |
729 kb |
458.8kb |
|
… |
… |
… |
|
合计 |
198mb |
72.5mb |
4.查询验证(类型、效率、精度)
4.1查询类型—面查点
以网格面fid为122的面进行查询。
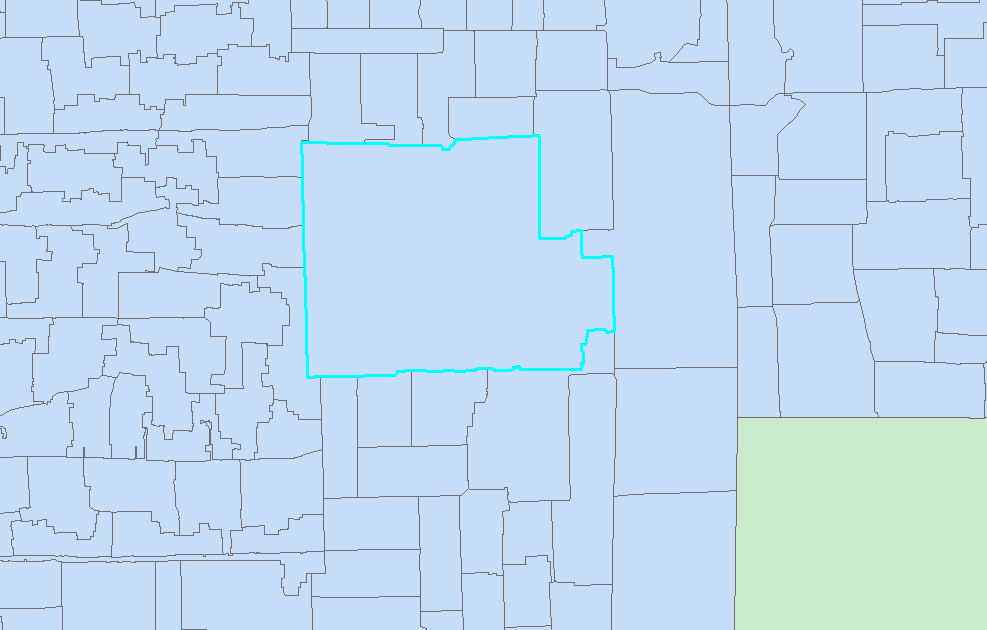
http请求
GET /_all/_search
{
"query":{
"bool": {
"filter": {
"geo_shape": {
"location": {
"shape": wkt,
"relation": "within"
}
}
}
}
}
}
效率:
查询到137个结果,耗时517毫秒
精度:

4.2查询类型—面查线
以街道面fid为2的面进行查询三种道路中心线。
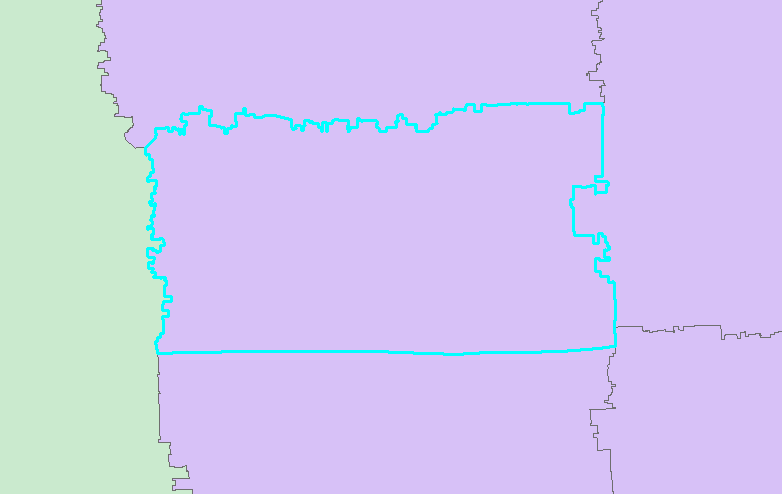
http请求
GET /一级道路中心线,二级道路中心线,三级道路中心线/_search
{
"query":{
"bool": {
"filter": {
"geo_shape": {
"location": {
"shape": wkt,
"relation": "within"
}
}
}
}
}
}
效率:
35条结果,耗时151毫秒
精度:
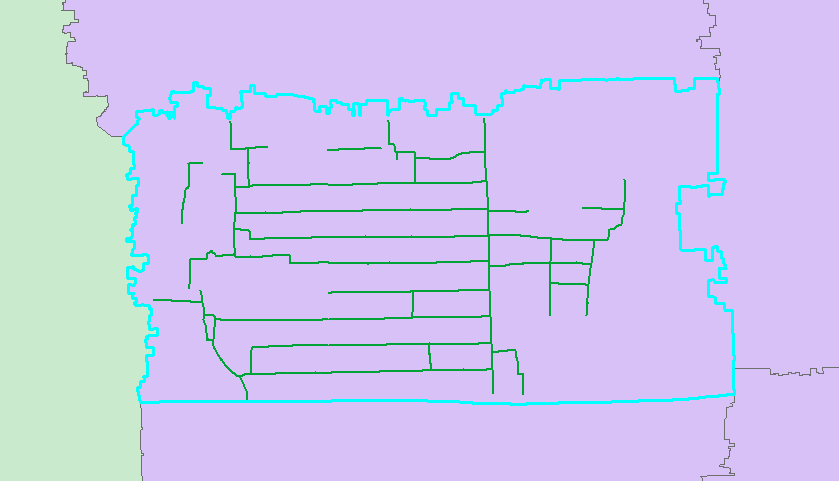
4.3查询类型—面查面
同样以街道面fid为2的面进行查询社区面
http请求
GET /社区面/_search
{
"query":{
"bool": {
"filter": {
"geo_shape": {
"location": {
"shape": wkt,
"relation": "within"
}
}
}
}
}
}
效率:
7条结果,耗时1406毫秒
精度:
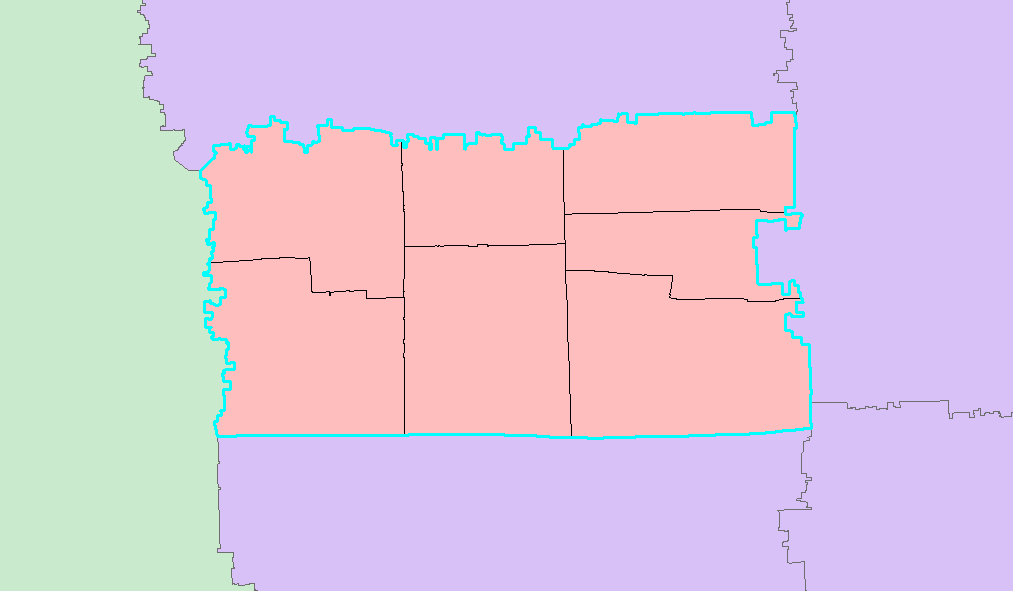
4.4查询类型—点查面
查找井盖fid为10929的点落在哪一块网格、社区、街道内。
http请求
GET /index/_search
{
"query":{
"bool": {
"filter": {
"geo_shape": {
"location": {
"shape": wkt
}
}
}
}
}
}
效率和精度:
查询结果是正确的,耗时都在5毫秒以内。
5.总结
利用ES来进行空间大数据的存储和运用无论从精度、效率、存储利用空间上均是非常合适的选择。但是从项目实施的角度,仍然有以下内容需要完成:
a.elasticsearch的脚本化搭建。
b.入库工具开发
c.后台服务接口封装,对输入参数(坐标等)以及输出结果(坐标等)根据对应环境转换
d.前端将全文检索——文本或空间,以标准功能开发
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^

GIS大数据存储预研的更多相关文章
- MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢? MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式 ...
- 大数据存储:MongoDB实战指南——常见问题解答
锁粒度与并发性能怎么样? 数据库的读写并发性能与锁的粒度息息相关,不管是读操作还是写操作开始运行时,都会请求相应的锁资源,如果请求不到,操作就会被阻塞.读操作请求的是读锁,能够与其它读操作共享,但是当 ...
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- 大数据存储的进化史 --从 RAID 到 Hdfs
我们都知道现在大数据存储用的基本都是 Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdfs. 我们先来 ...
- 大数据存储利器 - Hbase 基础图解
由于疫情原因在家办公,导致很长一段时间没有更新内容,这次终于带来一篇干货,是一篇关于 Hbase架构原理 的分享. Hbase 作为实时存储框架在大数据业务下承担着举足轻重的地位,可以说目前绝大多数大 ...
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 快速构建大数据存储分析平台-ELK平台安装
一.概述 ELK是由Elastic公司开发的Elasticsearch.Logstash.Kibana三款开源软件的缩写(但不限于这三款软件). 为什么使用ELK? 在目前流行的微服务架构中,一个大型 ...
- python3如何随机生成大数据存储到指定excel文档里
本次主要采用的是python3的第三方库xlwt,来创建一个excel文件.具体步骤如下: 1.确认存储位置,文件命名跟随时间格式 2.封装写入格式 3.实现随机数列生成 4.定位行和列把随机数写入 ...
随机推荐
- arcEngine开发之加载栅格数据
加载数据思路 在Engine中加载各种各样的数据都是通过这样的格式 IWorkspaceFactory pWorkspace = new IWorkspaceFactory(); IWorkspace ...
- DX11 Without DirectX SDK--使用Windows SDK来进行开发
在看龙书(Introduction to 3D Game Programming with Directx 11)的时候,里面所使用的开发工具包为Microsoft DirectX SDK(June ...
- [ 搭建Redis本地服务器实践系列二 ] :图解CentOS7配置Redis
上一章 [ 搭建Redis本地服务器实践系列一 ] :图解CentOS7安装Redis 详细的介绍了Redis的安装步骤,那么只是安装完成,此时的Redis服务器还无法正常运作,我们需要对其进行一些配 ...
- PAT1046: Shortest Distance
1046. Shortest Distance (20) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The ...
- popup_layer插件示例
导入popup_layer.js插件 设置好显示的div: <div class="main" id="showImg" style="disp ...
- MyBatis xml配置文件详解
http://blog.csdn.net/fenghuibian/article/details/52525671
- mvn -DskipTests和-Dmaven.test.skip=true区别
在使用mvn package进行编译.打包时,Maven会执行src/test/java中的JUnit测试用例,有时为了跳过测试,会使用参数-DskipTests和-Dmaven.test.skip= ...
- 你不知道的JavaScript--Item20 作用域与作用域链(scope chain)
作用域是JavaScript最重要的概念之一,想要学好JavaScript就需要理解JavaScript作用域和作用域链的工作原理.今天这篇文章对JavaScript作用域和作用域链作简单的介绍,希望 ...
- APNs 推送原理及问题
http://bbs.csdn.net/topics/390461996 在 iOS 平台上,大部分应用是不允许在后台运行并连接网络的.在应用没有被运行的时候,只能通过 Apple Push Noti ...
- Android 进阶 教你打造 Android 中的 IOC 框架 【ViewInject】 (上)
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/39269193,本文出自:[张鸿洋的博客] 1.概述 首先我们来吹吹牛,什么叫Io ...