Python数据抓取_BeautifulSoup模块的使用
在数据抓取的过程中,我们往往都需要对数据进行处理
本篇文章我们主要来介绍python的HTML和XML的分析库BeautifulSoup
BeautifulSoup 的官方文档网站如下
https://www.crummy.com/software/BeautifulSoup/bs4/doc/

BeautifulSoup可以在HTML和XML的结构化文档中抽取出数据,而且还提供了各类方法,可以很方便的对文档进行搜索、抽取和修改,能极大的提高我们数据挖掘的效率
下面我们来安装BeautifulSoup
(上面我已经安装过了,所以没有显示进度条)
非常简单,无非就是pip install 加安装的包名
pip3 install bs4
下面我们开始正式来学习这个模块
首先还是提供一个目标网址
我的个人网站
http://www.susmote.com

下面我们通过requests的get方法保存这个网址内容的源代码
import requests urls = "http://www.susmote.com" resp = requests.get(urls)
resp.encoding = "utf8"
content = resp.text with open("Bs4_test.html", 'w', encoding="utf8") as f:
f.write(content)
运行起来,我们马上就能得到这个网页的源代码了
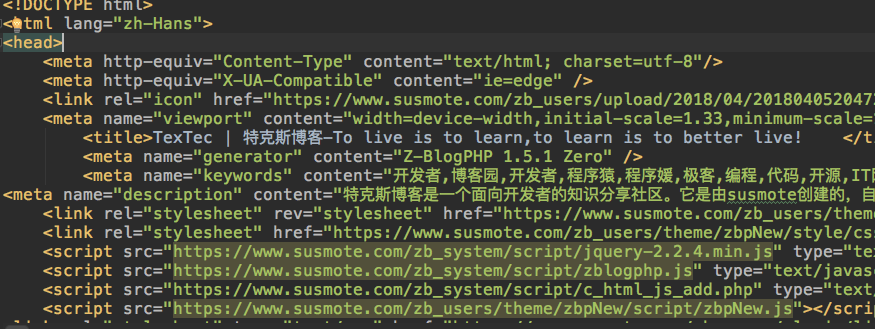
下面我们写的程序就是专门针对这个源代码利用BeautifulSoup来分析
首先我们来获取里面所有的a标签的href链接和对应的文本
代码如下
from bs4 import BeautifulSoup
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read())
a_list = bs.find_all('a')
for a in a_list:
if a.text != "":
print(a.text.strip(), a["href"])
首先我们从BS4里面导入BeautifulSoup
然后以只读模式打开文件打开文件,我们把f.read()作为BeautifulSoup的参数,也就是将字符串初始化,把返回的对象记为bs
然后我们就可以调用BeautifulSoup的方法了,BeautifulSoup的最常用的方法就是find和find_all,可以在文档中找到符合条件的元素,区别就是找到一个,和找到所有
在这里我们使用find_all方法,他的常用形式是
元素列表 = bs.find_all(元素名称, attires = {属性名:属性值})
然后就是依次输出找到的元素,这里就不多说 了
我们在命令行运行这段代码

输出结果如下

找寻的结果太多,不一一呈现
可以看到爬取的链接其中有很多规律
例如标签链接
我们可以对代码进行稍微的更改,以获取网站所有的标签链接,也就是做一个过滤
代码如下
from bs4 import BeautifulSoup
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
a_list = bs.find_all('a')
for a in a_list:
if a.text != "" and 'tag' in a["href"]:
print(a.text.strip(), a["href"])
大致内容没有改变,只是在输出前加了一个判定条件,以实现过滤
我们在命令行运行这个程序

结果如下

除了这样,你还可以使用很多方法达到相同的目标
使用attrs = [ 属性名 : 属性值 ] 参数
属性名我相信学过html的人一定都知道,例如"class","id"、"style"都是属性,下面我们逐步深入,利用这个来深入挖掘数据
获取我的博客网站中每篇文章的标题
经过浏览器调试,我们很容易获取到我的博客网页中标题部分的属性样式
如下图
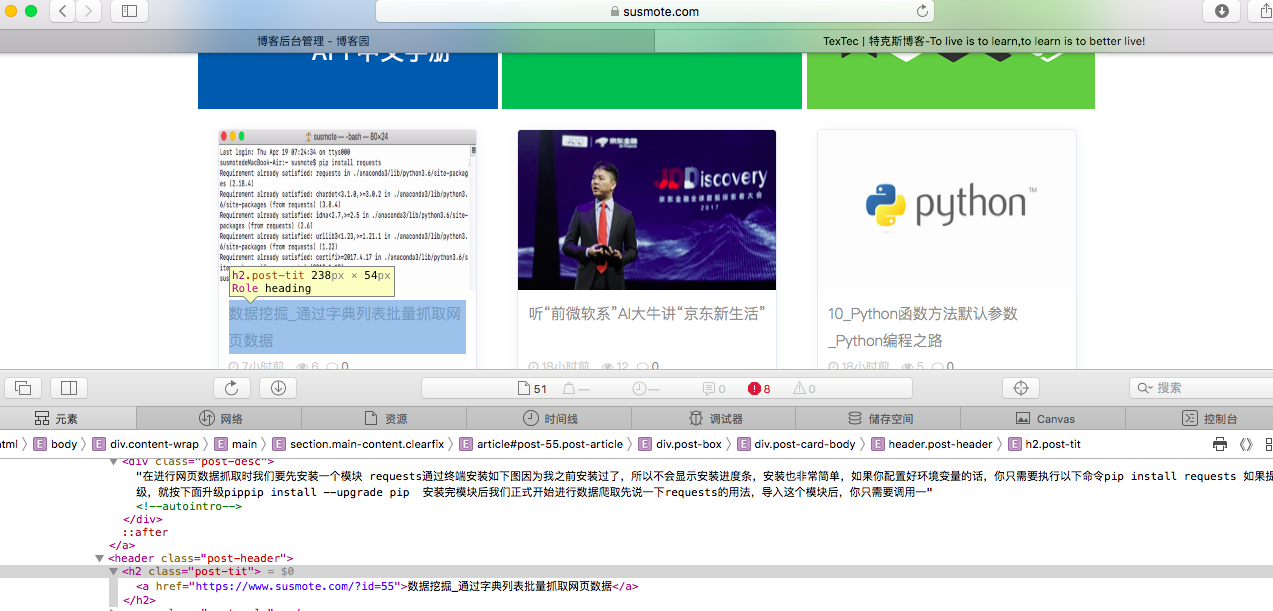
标题样式是一个<header class="post-header">
非常简单的一个属性
下面我们通过代码来实现批量获取文章标题
# coding=utf-8
__Author__ = "susmote" from bs4 import BeautifulSoup
n = 0
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
header_list = bs.find_all('header', attrs={'class': 'post-header'})
for header in header_list:
n = int(n)
n += 1
if header.text != "":
print(str(n) + ": " + header.text.strip() + "\n")
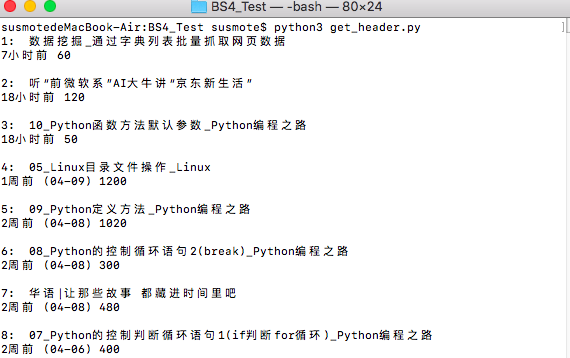
大体上跟之前的代码没什么差别,只是在find_all方法中多加了一个参数,attrs以实现属性过滤,然后为了使结果更清晰,我加了一个n
在命令行下运行,结果如下
利用正则表达式来表达属性值的特征
无非就是在属性值后面加一个正则匹配的方法,我在这就不过多解释了,如果想要了解,可以自行上网百度
我的博客网站 www.susmote.com
Python数据抓取_BeautifulSoup模块的使用的更多相关文章
- python数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- Python数据抓取(1) —数据处理前的准备
(一)数据抓取概要 为什么要学会抓取网络数据? 对公司或对自己有价值的数据,80%都不在本地的数据库,它们都散落在广大的网络数据,这些数据通常都伴随着网页的形式呈现,这样的数据我们称为非结构化数据 如 ...
- Python数据抓取(2) —简单网络爬虫的撰写
(一)使用Requests存储网页 Requests 是什么?网络资源(URLs)抓取套件 优点? 改善urllib2的缺点,让使用者以最简单的方式获取网络资源 可以使用REST操作(POST,PUT ...
- Python数据抓取(3) —抓取标题、时间及链接
本次分享,jacky将跟大家分享如何将第一财经文章中的标题.时间以及链接抓取出来 (一)观察元素抓取位置 网页的原始码很复杂,我们必须找到特殊的元素做抽取,怎么找到特殊的元素呢?使用开发者工具检视每篇 ...
- 数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
随机推荐
- Android,资料分享(2015 版)
Java 学习 我要再次强调,一定要有Java 基础(虽然现在使用其他语言也可以开发Android,但毕竟是很小众),也不要认为学习Java 两三周就可以不用管了,这会在以后的深入学习中暴露出问题,所 ...
- Android类参考---SQLiteOpenHelper
public 抽象类 SQLiteOpenHelper 继承关系 java.lang.Object |____android.database.sqlite.SQLiteOpenHelper 类概要 ...
- java 5线程中 Semaphore信号灯,CyclicBarrier类,CountDownLatch计数器以及Exchanger类使用
先来讲解一下Semaphore信号灯的作用: 可以维护当前访问自身的线程个数,并提供了同步机制, 使用semaphore可以控制同时访问资源的线程个数 例如,实现一个文件允许的并发访问数. 请看下面 ...
- 20162320刘先润第三周Bag类测试
前言 以下内容是本周Bag代码的课后作业,要求是完成伪代码.产品代码和测试代码,为了书写方便我将伪代码以注释的形式写在了产品代码的后面 测试步骤 1.首先对Bag类引用BagInterface的代码进 ...
- TRY
- github上传时出现error: src refspec master does not match any解决办法
github上传时出现error: src refspec master does not match any解决办法 这个问题,我之前也遇到过,这次又遇到了只是时间间隔比较长了,为了防止以后再遇到类 ...
- git基本用法
基本用法(下) 一.实验说明 本节实验为 Git 入门第二个实验,继续练习最常用的git命令. 1.1 实验准备 在进行该实验之前,可以先clone一个练习项目gitproject ...
- hibernate.QueryException: ClassNotFoundException: org.hibernate.hql.ast.HqlToken
环境:weblogic10.3.5,hibernate3,GGTS(groovy/grails tools suite):出现这问题是因为该项目是从weblogic8.1.6下移植到weblogic1 ...
- 一、Django的基本用法
学习Django有一段时间了,整理一下,充当笔记. MVC 大部分开发语言中都有MVC框架 MVC框架的核心思想是:解耦 降低各功能模块之间的耦合性,方便变更,更容易重构代码,最大程度上实现代码的重用 ...
- SQLite 带你入门
SQLite数据库相较于我们常用的Mysql,Oracle而言,实在是轻量得不行(最低只占几百K的内存).平时开发或生产环境中使用各种类型的数据库,可能都需要先安装数据库服务(server),然后才能 ...