SIMD---SSE系列及效率对比
SSE(即Streaming SIMD Extension),是对由MMX指令集引进的SIMD模型的扩展。我们知道MMX有两个明显的缺点:
- 只能操作整数。
- 不能与浮点数同时运行(MMX使用FPU寄存器作为别名)。
而SSE则解决了这个问题,SSE引进了8个专用的浮点寄存器MMX0~MMX7。后来Intel又陆续推出了SSE2、SSE3、SSE4,这使得SSE指令系列同时拥有了浮点数学运算功能和整数运算功能,因此早先的MMX指令就显得有点多余了(虽然可是并行执行SSE、MMX指令来提高性能)。
SSE系列功能特点
SSE1
- 添加8个128位寄存器XMM0~MMX7.
- 操作4个单精度浮点数。
- 支持打包(Packed)和标量(Scaler)操作。
SSE2
- 添加整数向量运算,提升运行性能。
- 支持双精度浮点向量运算。
- 打包类型取消限制,支持8位、16位、32位、64位,包括整数和浮点数。
- 添加缓存控制指令。
- 添加浮点数到整数的转换指令
SSE3
- 寄存器内水平操作,例如打包在一个128位MMX寄存器内的2个64位整数,可以利用新指令对这两个整数进行算数运算。
- 多线程优化指令,在超线程下提高性能。
SSSE3
- 打包整形数据的运算加速。
SSE4
SSE4包含两个子集:SSE4.1和SSE4.2,并兼容以前的64位和IA-32指令集架构。值得指出的是SSE4增加了:1)STTNI(String and Text New Instructions)指令来帮助开发者处理字符搜索和比较,旨在加速对XML文件的解析;2)CRC32指令,帮助计算循环冗余校验值。
SSE效率对比
这里我们就只简单比较下这两个指令集的计算效率,其他功能就不在本次考虑范围内了。像前一篇博客一样,我们同样用对10000000个字符进行加操作来进行对比操作。这里我们全部用Intrinsics来对比,方便编写,不用考虑调用约定。
整数计算 Mmx vs Sse
因为整数操作只在SSE2中支持,所以实际上我们用的是sse2指令。
mmx代码:
void calculateUsingMmx(char* data, unsigned size)
{
assert(size % 8 == 0);
__m64 step = _mm_set_pi8(10, 10, 10, 10, 10, 10, 10, 10);
__m64* dst = reinterpret_cast<__m64*>(data);
for (unsigned i = 0; i < size; i += 8)
{
auto sum = _mm_adds_pi8(step, *dst);
*dst++ = sum;
}
_mm_empty();
}
sse代码:
void calculateUsingSseInt(char* data, unsigned size)
{
assert(size % 16 == 0);
__m128i step = _mm_set_epi8(10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10);
__m128i* dst = reinterpret_cast<__m128i*>(data);
for (unsigned i = 0; i < size; i += 16)
{
auto sum = _mm_add_epi8(step, *dst);
*dst++ = sum;
}
// no need to clear flags like mmx because SSE and FPU can be used at the same time.
}
浮点计算 Asm vs Sse
由于MMX指令集不包含浮点指令,因此我们x86浮点指令来对比,同样对10000000个flaot值进行加操作。
Asm代码:
void calculateUsingAsmFloat(float* data, unsigned count)
{
auto singleFloatBytes = sizeof(float);
auto step = 10.0;
__asm
{
push ecx
push edx
mov edx, data
mov ecx, count
fld step // fld only accept FPU or Memory
calcLoop:
fld [edx]
fadd st(0), st(1)
fstp [edx]
add edx, singleFloatBytes
dec ecx
jnz calcLoop
pop edx
pop ecx
}
}
Sse代码:
void calculateUsingSseFloat(float* data, unsigned count)
{
assert(count % 4 == 0);
assert(sizeof(float) == 4);
__m128 step = _mm_set_ps(10.0, 10.0, 10.0, 10.0);
__m128* dst = reinterpret_cast<__m128*>(data);
for (unsigned i = 0; i < count; i += 4)
{
__m128 sum = _mm_add_ps(step, *dst);
*dst++ = sum;
}
}
运行结果
SSE2的浮点计算对比x86浮点计算性能提升不是非常明显,但是也要考虑Intrinsics使用导致的略微性能缺失。上面两种计算方式的效率对比结果如下:
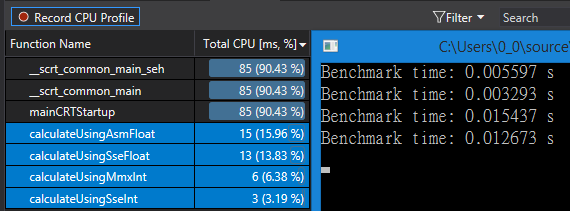
完整代码见链接。
SIMD---SSE系列及效率对比的更多相关文章
- string中Insert与Format效率对比、String与List中Contains与IndexOf的效率对比
关于string的效率,众所周知的恐怕是“+”和StringBuilder了,这些本文就不在赘述了.关于本文,请先回答以下问题(假设都是基于多次循环反复调用的情况下):1.使用Insert与Forma ...
- FileInputStream 与 BufferedInputStream 效率对比
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3550158.html ,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体 ...
- SSE 系列内置函数中的 shuffle 函数
SSE 系列内置函数中的 shuffle 函数 邮箱: quarrying@qq.com 博客: http://www.cnblogs.com/quarryman/ 发布时间: 2017年04月18日 ...
- java中多种写文件方式的效率对比实验
一.实验背景 最近在考虑一个问题:“如果快速地向文件中写入数据”,java提供了多种文件写入的方式,效率上各有异同,基本上可以分为如下三大类:字节流输出.字符流输出.内存文件映射输出.前两种又可以分为 ...
- golang 浮点数 取精度的效率对比
需求 浮点数取2位精度输出 实现 代码 package main import ( "time" "log" "strconv" " ...
- Snapman系统中TCC执行效率和C#执行效率对比
Snapman集合了TCC编译器可以直接编译执行C语言脚本,其脚本执行效率和C#编译程序进行效率对比,包括下面4方面: 1.函数执行效率 2.数字转换成字符串 3.字符串的叠加 4.MD5算法 这是C ...
- 查询最新记录的sql语句效率对比
在工作中,我们经常需要检索出最新条数据,能够实现该功能的sql语句很多,下面列举三个进行效率对比 本次实验的数据表中有55万条数据,以myql为例: 方式1: SELECT * FROM t_devi ...
- c#中@标志的作用 C#通过序列化实现深表复制 细说并发编程-TPL 大数据量下DataTable To List效率对比 【转载】C#工具类:实现文件操作File的工具类 异步多线程 Async .net 多线程 Thread ThreadPool Task .Net 反射学习
c#中@标志的作用 参考微软官方文档-特殊字符@,地址 https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/toke ...
- EF 数据查询效率对比
优化的地方: 原地址:https://www.cnblogs.com/yaopengfei/p/9226328.html ①:如果仅是查询数据,并不对数据进行增.删.改操作,查询数据的时候可以取消状态 ...
随机推荐
- 内置函数--bin() oct() int() hex()
英文文档: bin(x) Convert an integer number to a binary string. The result is a valid Python expression. ...
- Python基础学习参考(七):字典和集合
一.字典 字典跟列表一样是一组数据的集合.它的特点是什么呢? 特点一:字典具有键(key)和值(value),其中键必须是唯一的,不可重复的,即键必须可以哈希的.对于值没有要求. 特点二:字典是无序的 ...
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 52: invalid continuation byte
代码: df_w = pd.read_table( r'C:\Users\lab\Desktop\web_list_n.txt', sep=',', header=None) 当我用pandas的re ...
- vscode格式化Vue出现的问题
一.VSCode中使用vetur插件格式化vue文件时,js代码会自动加上冒号和分号 本来就是简写比较方便舒服,结果一个格式化回到解放前 最后找到问题原因: 首先,vetur默认设置是这个样的.也就是 ...
- Java兔子问题
题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少? /** * @Title:Rabbit.java ...
- [php错误]PHP中Notice: unserialize(): Error at offset of bytes in on line 的解决方法
使用unserialize函数将数据储存到数据库的时候遇到了这个报错, 后来发现是将gb2312转换成utf-8格式之后, 每个中文的字节数从2个增加到3个之后导致了反序列化的时候判断字符长度出现了问 ...
- HighCharts之2D带Label的折线图
HighCharts之2D带Label的折线图 1.HighCharts之2D带Label的折线图源码 LineLabel.html: <!DOCTYPE html> <html&g ...
- com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown database 'user'
1.错误描述 2014-7-12 21:06:05 com.mchange.v2.c3p0.impl.AbstractPoolBackedDataSource getPoolManager 信息: I ...
- Duplicate entry '0' for key 'PRIMARY'的一种可能的解决办法
在MySQL设计好数据库往往数据库中插入数据的时候, 因为主键ID默认是不赋值的,只给其他项目赋值了,相关的SQL代码是这样的 StringBuilder strSql = new StringBui ...
- JavaScript设计模式(10)-观察者模式
观察者模式 1. 介绍 发布者与订阅者是多对多的方式 通过推与拉获取数据:发布者推送到订阅者或订阅者到发布者那边拉 使并行开发的多个实现能彼此独立地进行修改 其实我们在前端开发中使用到的时间监听就是浏 ...