Collections.synchronizedMap()、ConcurrentHashMap、Hashtable之间的区别
为什么要比较Hashtable、SynchronizedMap()、ConcurrentHashMap之间的关系?因为常用的HashMap是非线程安全的,不能满足在多线程高并发场景下的需求。
那么为什么说HashTable是线程不安全的?具体参阅关于java集合类HashMap的理解
如何线程安全的使用HashMap
了解了 HashMap 为什么线程不安全,那现在看看如何线程安全的使用 HashMap。这个无非就是以下三种方式:
- Hashtable
- ConcurrentHashMap
- Synchronized Map
Hashtable
那先说说Hashtable,Hashtable源码中是使用 synchronized 来保证线程安全的,比如下面的 get 方法和 put 方法:
public synchronized V get(Object key) {
// 省略实现
}
public synchronized V put(K key, V value) {
// 省略实现
}
所以当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用 put 方法时,另一个线程不但不可以使用 put 方法,连 get 方法都不可以,好霸道啊!!!so~~,效率很低,现在基本不会选择它了。
Collections.synchronizedMap()
看了一下源码,synchronizedMap()的实现还是很简单的。
// synchronizedMap方法
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
// SynchronizedMap类
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L; private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
} SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
} public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
} public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
// 省略其他方法
}
从源码中可以看出调用 synchronizedMap() 方法后会返回一个 SynchronizedMap 类的对象,而在 SynchronizedMap 类中使用了 synchronized 同步关键字来保证对 Map 的操作是线程安全的。
ConcurrentHashMap
Spring的源码中有很多使用ConcurrentHashMap的地方。具体参阅》》》》》》》》。需要注意的是,上面博客是基于 Java 7 的,和8有区别,在8中 CHM 摒弃了 Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。
下面通过一个具体例子看看Collections.synchronizedMap()和ConcurrentHashMap哪个性能更高。
public class Test {
public final static int THREAD_POOL_SIZE = 5;
public static Map<String, Integer> crunchifyHashTableObject = null;
public static Map<String, Integer> crunchifySynchronizedMapObject = null;
public static Map<String, Integer> crunchifyConcurrentHashMapObject = null;
public static void main(String[] args) throws InterruptedException {
// Test with Hashtable Object
crunchifyHashTableObject = new Hashtable<>();
crunchifyPerformTest(crunchifyHashTableObject);
// Test with synchronizedMap Object
crunchifySynchronizedMapObject = Collections.synchronizedMap(new HashMap<String, Integer>());
crunchifyPerformTest(crunchifySynchronizedMapObject);
// Test with ConcurrentHashMap Object
crunchifyConcurrentHashMapObject = new ConcurrentHashMap<>();
crunchifyPerformTest(crunchifyConcurrentHashMapObject);
}
public static void crunchifyPerformTest(final Map<String, Integer> crunchifyThreads) throws InterruptedException {
System.out.println("Test started for: " + crunchifyThreads.getClass());
long averageTime = 0;
for (int i = 0; i < 5; i++) {
long startTime = System.nanoTime();
ExecutorService crunchifyExServer = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
for (int j = 0; j < THREAD_POOL_SIZE; j++) {
crunchifyExServer.execute(new Runnable() {
@SuppressWarnings("unused")
@Override
public void run() {
for (int i = 0; i < 500000; i++) {
Integer crunchifyRandomNumber = (int) Math.ceil(Math.random() * 550000);
// Retrieve value. We are not using it anywhere
Integer crunchifyValue = crunchifyThreads.get(String.valueOf(crunchifyRandomNumber));
// Put value
crunchifyThreads.put(String.valueOf(crunchifyRandomNumber), crunchifyRandomNumber);
}
}
});
}
// Make sure executor stops
crunchifyExServer.shutdown();
// Blocks until all tasks have completed execution after a shutdown request
crunchifyExServer.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS);
long entTime = System.nanoTime();
long totalTime = (entTime - startTime) / 1000000L;
averageTime += totalTime;
System.out.println("2500K entried added/retrieved in " + totalTime + " ms");
}
System.out.println("For " + crunchifyThreads.getClass() + " the average time is " + averageTime / 5 + " ms\n");
}
}
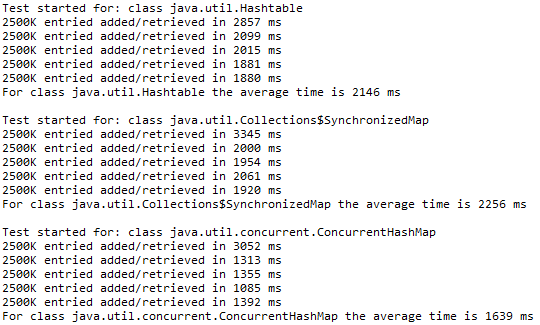
结果显示,ConcurrentHashMap性能是明显优于Hashtable和SynchronizedMap的,ConcurrentHashMap花费的时间比前两个的一半还少。
Collections.synchronizedMap()、ConcurrentHashMap、Hashtable之间的区别的更多相关文章
- ArrayList,Vector,HashMap,HashSet,HashTable之间的区别与联系
在编写java程序中,我们最常用的除了八种基本数据类型,String对象外还有一个集合类,在我们的的程序中到处充斥着集合类的身影!java中集合大家族的成员实在是太丰富了,有常用的ArrayList. ...
- LinkedList,ArrayList,Vector,HashMap,HashSet,HashTable之间的区别与联系
在编写java程序中,我们最常用的除了八种基本数据类型,String对象外还有一个集合类,在我们的的程序中到处充斥着集合类的身影!java中集合大家族的成员实在是太丰富了,有常用的ArrayList. ...
- HashTable、HashMap、ConcurrentHashMap、Collections.synchronizedMap()区别
Collections.synchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步,而ConcurrentHashMap的实现却更加精细,它对Ha ...
- Collections.synchronizedMap()与ConcurrentHashMap的区别
前面文章提到Collections.synchronizedMap()与ConcurrentHashM两者都提供了线程同步的功能.那两者的区别在哪呢?我们们先来看到代码例子. 下面代码实现一个线 ...
- Collections.synchronizedMap()与ConcurrentHashMap区别
Collections.synchronizedMap()与ConcurrentHashMap主要区别是:Collections.synchronizedMap()和Hashtable一样,实现上在调 ...
- ConcurrentHashMap和 CopyOnWriteArrayList提供线程安全性和可伸缩性 以及 同步的集合类 Hashtable 和 Vector Collections.synchronizedMap 和 Collections.synchronizedList 区别缺点
ConcurrentHashMap和 CopyOnWriteArrayList提供线程安全性和可伸缩性 DougLea的 util.concurrent 包除了包含许多其他有用的并发构造块之外,还包含 ...
- 测试HashTable、Collections.synchronizedMap和ConcurrentHashMap的性能
对于map的并发操作有HashTable.Collections.synchronizedMap和ConcurrentHashMap三种,到底性能如何呢? 测试代码: package com. ...
- ConcurrentHashMap vs Collections.synchronizedMap()不同
之前项目中,有用到过Collections.synchronizedMap(),后面发现当并发数很多的时候,出现其他请求等待情况,因为synchronizedMap会锁住所有的资源,后面通过查阅资料, ...
- Hashtable,HashMap和ConcurrentHashMap的原理及区别
一.原理 Hashtable 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashM ...
随机推荐
- 浅谈我为什么选择用Retrofit作为我的网络请求框架
比较AsyncTask.Volley.Retrofit三者的请求时间 使用 单次请求 7个请求 25个请求 AsyncTask 941ms 4539ms 13957ms Volley 560ms 22 ...
- php opcode缓存
本文移至:http://www.phpgay.com/Article/detail/classid/2/id/61.html 1.什么是opcode 解释器分析代码之后,生成可以直接运行的中间代码,就 ...
- OpenCV——PS滤镜,渐变映射
// define head function #ifndef PS_ALGORITHM_H_INCLUDED #define PS_ALGORITHM_H_INCLUDED #include < ...
- 苹果新的编程语言 Swift 语言进阶(十三)--类型检查与类型嵌套
一 类型检查 1. 类型检查操作符 类型检查用来检查或转换一个实例的类型到另外的类型的一种方式. 在Swift中,类型检查使用is和as操作符来实现. is操作符用来检查一个实例是否是某种特定类型,如 ...
- iOS下FMDB的多线程操作(一)
iOS中一些时间比较长的操作都应该放在子线程中,以避免UI的卡顿.而sqlite 是非线程安全的,故在多线程中不能共用同一个数据库连接,否则会导致EXC_BAD_ACCESS.所以我们可以在子线程中创 ...
- RubyMotion之父:Ruby是目前替代Objective-C的最佳iOS开发语言
发表于2012-08-16 00:52| 21716次阅读| 来源CSDN| 24 条评论| 作者杨鹏飞 RubyMotionRubyObjective-CiOSJava 摘要:曾几何时,PC端有那么 ...
- 【redis】Java连接云服务器redis之JedisConnectionException的异常问题
代码很简单: public static void main(String[] args) { Jedis jedis = new Jedis("116.85.10.216",63 ...
- JAVA调用数据库存储过程
下面将举出JAVA对ORACLE数据库存储过程的调用 ConnUtils连接工具类:用来获取连接.释放资源 复制代码 package com.ljq.test; import jav ...
- AS3中的mouseEnabled与mouseChild
InteractiveObject类的一个属性,InteractiveObject类是用户可以使用鼠标和键盘与之交互的所有显示对象的抽象基类.我们不能直接实例化InteractiveObject类.m ...
- OSGi简介
OSGi简介 OSGi是什么 下面来看看“维基百科”给出的解释: OSGi(Open Service Gateway Initiative)有双重含义.一方面它指OSGi Alliance组织:另一方 ...