第19/24周 锁升级(Lock Escalations)
大家好,欢迎回到性能调优培训。上2个星期我们已经讨论了SQLServer里的悲观和乐观锁。今天我想谈下SQL Server里对于锁的一个特殊现象:所谓的锁升级(Lock Escalations)。在我们进入那个问题的细节前,我想先谈下SQL Server内部使用的锁层级(Lock Hierarchy)。
锁层级(Lock Hierarchy)
2个星期前,当我们开始讨论悲观并发模式(pessimistic concurrency)时,我告诉你SQLServer在记录层会获取共享锁(Shared Locks)和排它锁(Exclusive Locks)。遗憾的是,这不是全部事实。完整事实是SQL Server会在不同粒度(granularities)获得锁,例如数据库,不同页,最后在记录层。SQL Server实现整个所层级(lock hierarchy),如下图所示:
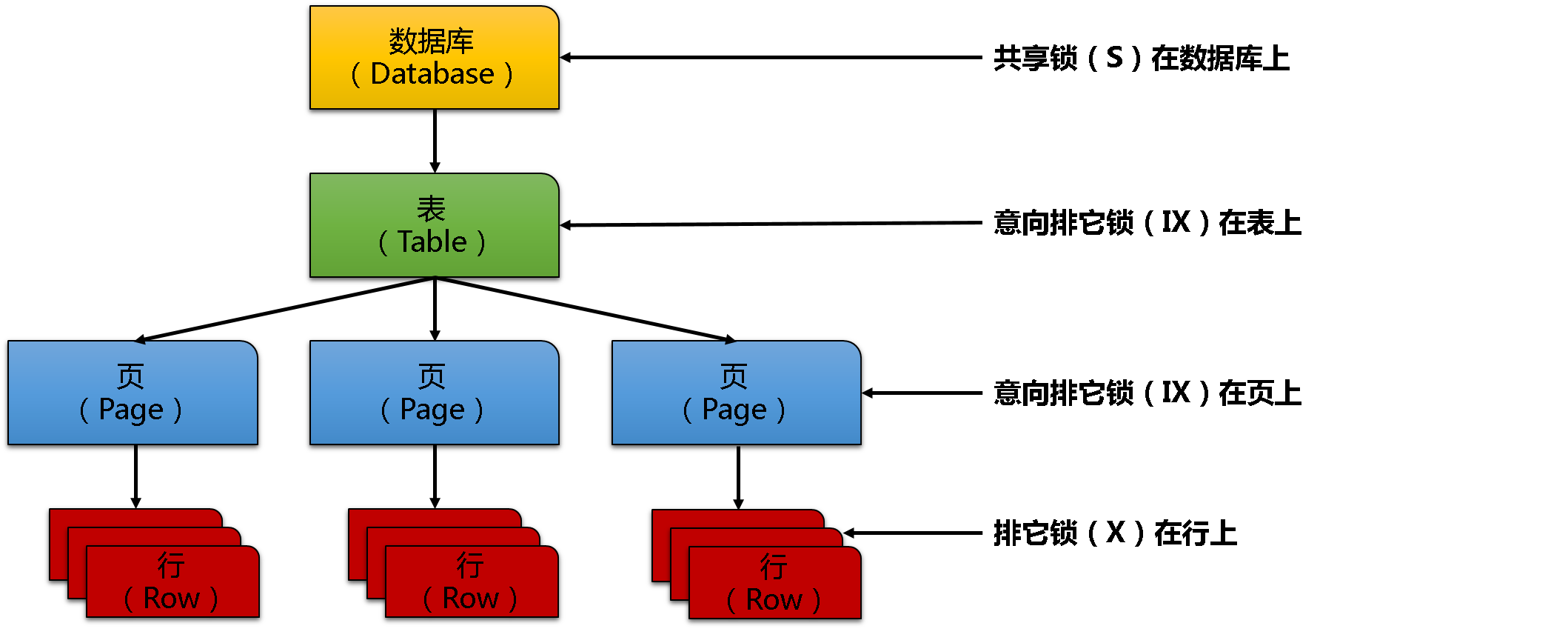
一旦你使用一个数据库,你的会话会在数据库上获得一个共享锁(Shared Lock)。那个共享锁是需要的,因此没有其他人可以删除数据库,或还原数据库备份。这些操作会被阻塞,因为你打开的会话。SQL Server不但在行层上有共享锁和排它锁,SQL Server也在表和页层使用所谓的意向锁(Intent Locks)。
- 在行层有共享锁(Shared Locks),在表和页上拿到意向共享锁(intent shared lock(IS))。
- 在行层有排它锁(Exclusive Locks),在表和页上拿到意向排它锁(intent exclusive lock(IX))。
意向锁(Intent Locks)用来作为1个信号,表示在锁层级(lock hierarchy)里(很可能)有1个不兼容的锁在低一层已获得。意向锁是关系数据库主要性能调优。没有它们的话,锁管理器需要在低1层完全进入列表,来决定高1层的锁是否可以获取。如果你在表层有一个意向排它锁(IX),你就不能在表层获得排它锁(X),因为有些记录在表本身里已经是排它锁(X):在表层获得排它锁(X)会阻塞,因为在表上已经有意向排它锁(IX)。
遗憾的是这个多粒度锁并不是免费的:在SQL Server里每个锁需要96 bytes,因此会消耗一些内存,SQL Server必须保证没有查询使用太多的内存空间,不然的话内存会被耗尽。这就是为什么会有锁升级(lock escalations)的存在。
锁升级(Lock Escalations)
假设下列情景:你更新散布在20万个数据页上的1百万条记录。在那个情况下,你需要在记录本身获得1百万个排它锁(X),在不同页上获得20万个意向排它锁(IX),在表本身上获得1个意向排它锁(IX),你的查询合计需要获得1200001,在锁管理器需要近110M的锁空间——就只对这个简单查询。依据内存占用这个方法非常危险。因此你在一层一旦获得超过5000个锁,SQL Server就会触发锁升级(Lock Escalations)——例如在记录层。在那个情况下,SQL Server升级你个体细密度行锁为1个粗颗粒的表锁:
- 个体X锁升级为1个表的X锁
- 个体S锁升级为1个表的S锁
下图演示了锁升级发生前后的锁保持情况:
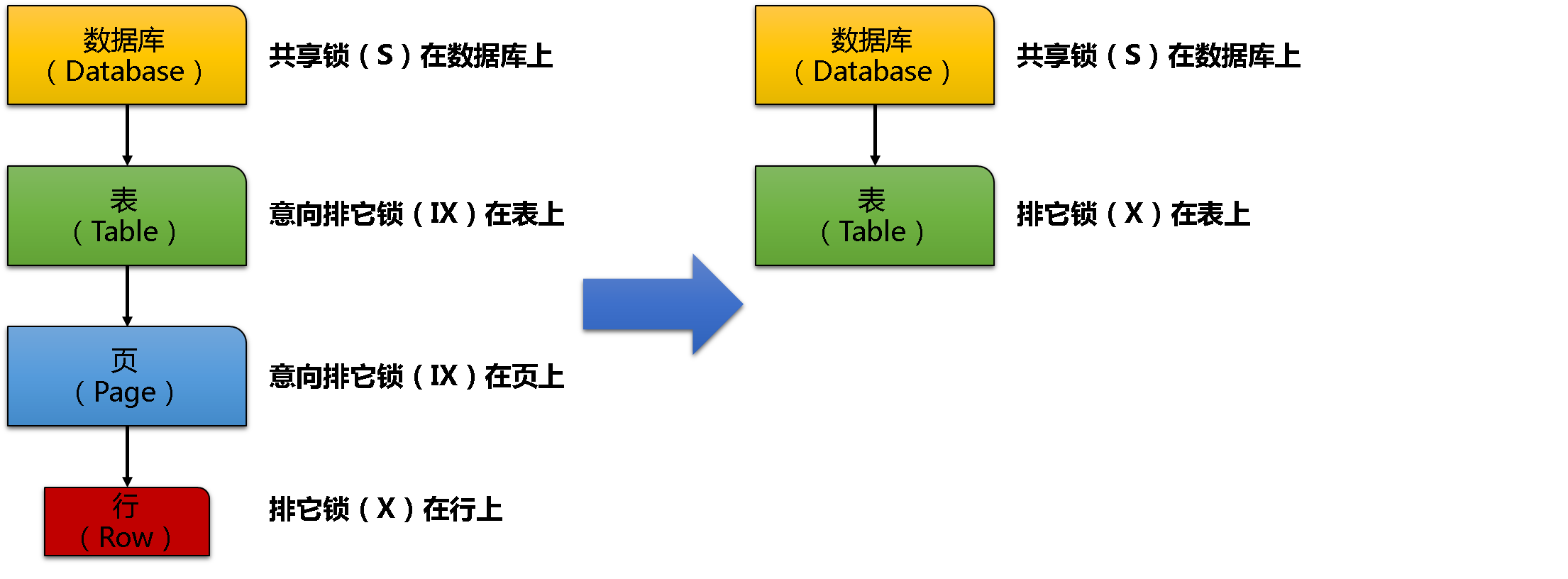
通过锁升级内存占用肯定会下降——但这也会影响你数据库的并发!在表上的排它锁(X)意味着没有其他人可以从你的表读写,在表层上的共享锁(S)意味着你的表是只读的,没有人可以写它!你数据库的吞吐量只会下降!
当你在1个层获得超过5000个锁,SQL Server就会触发锁升级。这是系统硬码限定,不同通过任何配置选项修改。自SQL Server 2008开始,你可以通过如下代码,控制通过ALTER TABLE DDL语句的锁升级:
ALTER TABLE MyTableName
SET
(
LOCK_ESCALATION = TABLE -- or AUTO or DISABLE
)
GO
默认情况,SQL Server总是升级到表级别(Table选项)。如果你设置升级选项为AUTO,当你的表是分区的话,SQL Server可以升级到分区级别。但对这个选项,你要非常仔细,因为如果你用错误的顺序访问分区,它会导致死锁。使用DISABLE选项,对表你停用了锁升级——这会带来刚才提到的所有各个副作用(内存消耗)。现在的问题是,你如何高效修改或删除5000条记录而不触发锁升级?
- 逐步更新/删除少于5000条记录(例如在WHILE循环里)
- 如果表分区的话,使用分区交换
- 临时停用锁升级,但要注意同时的内存耗用
小结
锁升级(Lock Escalations)是SQL Server提供的安全保障。它们为什么存在有个好理由,但当升级发生时,这个会引入更少并发的副作用。因此当你在写一次处理超过5000条记录的代码时要非常仔细。或许你可以逐步处理这些记录,而不是用1个大的UPDATE/DELETE语句。如果你想了解更多锁升级信息,可以看下我以前写一篇文章《锁升级》。
下周我们继续SQL Server里的锁和阻塞,讲下死锁,还有SQL Server如何处理它们。请继续关注!
围观PPT:
第19/24周 锁升级(Lock Escalations)的更多相关文章
- 第0/24周 SQL Server 性能调优培训引言
大家好,这是我在博客园写的第一篇博文,之所以要开这个博客,是我对MS SQL技术学习的一个兴趣记录. 作为计算机专业毕业的人,自己对技术的掌握总是觉得很肤浅,博而不专,到现在我才发现自己的兴趣所在,于 ...
- (转)DB2性能优化 – 如何通过调整锁参数优化锁升级
原文:http://blog.51cto.com/5063935/2074306 1.概念描述 所谓的锁升级(lock escalation),是数据库的一种作用机制,为了节约内存的开销, 其会将为数 ...
- 锁升级(Lock Escalations)——它们经常发生么?
前段时间,我写了一些SQL Server里锁升级的基础知识,还有它是如何影响执行计划的.今天,我想进一步谈下锁升级: 锁升级什么时候发生? 通常在SQL Server里如果在SQL语句里你请求的行数超 ...
- SQL Server Lock Escalation - 锁升级
Articles Locking in Microsoft SQL Server (Part 12 – Lock Escalation) http://dba.stackexchange.com/qu ...
- MySQL 避免行锁升级为表锁——使用高效的索引
文章目录 普通索引 属性值重复率高 属性值重复率低 小结 众所周知,MySQL 的 InnoDB 存储引擎支持事务,支持行级锁(innodb的行锁是通过给索引项加锁实现的).得益于这些特性,数据库支持 ...
- 面试官:说一下Synchronized底层实现,锁升级的具体过程?
面试官:说一下Synchronized底层实现,锁升级的具体过程? 这是我去年7,8月份面试的时候被问的一个面试题,说实话被问到这个问题还是很意外的,感觉这个东西没啥用啊,直到后面被问了一波new O ...
- 第18/24周 乐观并发控制(Optimistic Concurrency)
大家好,欢迎回到性能调优培训.上个星期我通过讨论悲观并发模式拉开了第5个月培训的序幕.今天我们继续,讨论下乐观并发模式(Optimistic Concurrency). 行版本(Row Version ...
- 再谈synchronized锁升级
在图文详解Java对象内存布局这篇文章中,在研究对象头时我们了解了synchronized锁升级的过程,由于篇幅有限,对锁升级的过程介绍的比较简略,本文在上一篇的基础上,来详细研究一下锁升级的过程以及 ...
- 禁用sqlserver的锁升级
锁升级 SQLSERVER.DB2中的锁是内存里面实现的,这就有个资源消耗问题,当锁的数量达到一个阀值或内存有压力时,就会引发锁升级.实际的情况是从row lock直接升级到table lock,而不 ...
随机推荐
- 【TypeScript】如何在TypeScript中使用async/await,让你的代码更像C#。
[TypeScript]如何在TypeScript中使用async/await,让你的代码更像C#. async/await 提到这个东西,大家应该都很熟悉.最出名的可能就是C#中的,但也有其它语言也 ...
- Spring4:JDBC
数据库连接池 对一个简单的数据库应用,由于对数据库的访问不是很频繁,这时可以简单地在需要访问数据库时,就新创建一个连接,就完后就关闭它,这样做也不会带来什么性能上的开销.但是对于一个复杂的数据库应用, ...
- Java IO7:管道流、对象流
前言 前面的文章主要讲了文件字符输入流FileWriter.文件字符输出流FileReader.文件字节输出流FileOutputStream.文件字节输入流FileInputStream,这些都是常 ...
- TypeError: 'bases' is null or not an object。IE8 bug 腐朽的对象
使用Webapp Builder时候发现,在IE8上很奇怪的一个现象:在ajax回调函数中引用一个闭包作用域链中的对象作为某一个Dijit的实例化参数时有问题:bases is null or not ...
- dijit样式定制之TextBox(一)
参考资料:http://dojotoolkit.org/reference-guide/1.9/dijit/themes.html http://archive.dojotoolkit.org/nig ...
- http学习笔记(二)—— 嘿!伙计,你在哪?(URL)
我们之所以希望浏览网页,其中一个重要的原因就是庞大的web世界中有很丰富的资源,他就像哆啦a梦的口袋,随时都能拿出我们想要的宝贝.这些资源通过http被传送到我们的浏览器,并展示到我们的屏幕上.而我们 ...
- 换个角度理解云计算之MapReduce
上一篇简单讲了一下HDFS,简单来说就是一个叫做“NameNode”的大哥,带着一群叫做“DataNode”的小弟,完成了一坨坨数据的存储,其中大哥负责保存数据的目录,小弟们负责数据的真正存储,而大哥 ...
- ECMAScript5 Array新增方法
数组在各个编程语言中的重要性不言而喻,但是在之前的JavaScript中数组(JavaScript 数组详解)虽然功能已经很强大,但操作方法并不完善,在ECMAScript5中做了适当的补充. Arr ...
- IOS Animation-动画基础、深入
1. Model Layer Tree(模型层树)和Presentation Layer Tree(表示层树) CALayer是动画产生的地方.当我们动画添加到Layer时,是不直接修改layer的属 ...
- iOS Crash常规跟踪方法及Bugly集成运用
当app出现崩溃, 研发阶段一般可以通过以下方式来跟踪crash信息 #1.模拟器运行, 查看xcode错误日志 #2.真机调试, 查看xcode错误日志 #3.真机运行, 查看device系统日志 ...