Linux下对superblock的理解
对superblock的理解首先从partition structure的结构开始:
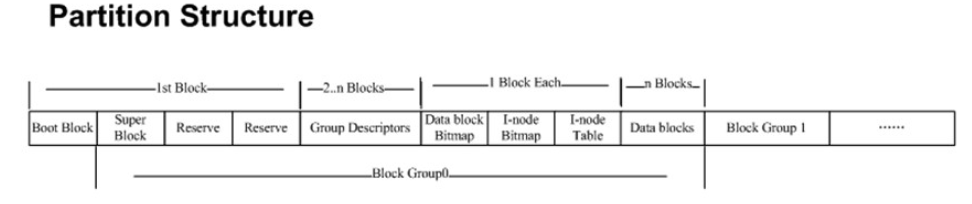
、下面就是对super block的理解了
Super block即为超级块,它是硬盘分区开头——开头的第一个byte是byte 0,从 byte 1024开始往后的一部分数据。由于 block size最小是 1024 bytes,所以super block可能是在block 1中(此时block 的大小正好是 1024 bytes)
超级块中的数据其实就是文件卷的控制信息部分,也可以说它是卷资源表,有关文件卷的大部分信息都保存在这里。例如:硬盘分区中每个block的大小、硬盘分区上一共有多少个block group、以及每个block group中有多少个inode。
对于super block的结构和涵义可以通过查看/usr/include/linux/ext3_fs.h文件:
通过set number:
386 struct ext3_super_block {
386 struct ext3_super_block {
387 /*00*/ __le32 s_inodes_count; /* Inodes count */
388 __le32 s_blocks_count; /* Blocks count */
389 __le32 s_r_blocks_count; /* Reserved blocks count */
390 __le32 s_free_blocks_count; /* Free blocks count */
391 /*10*/ __le32 s_free_inodes_count; /* Free inodes count */
392 __le32 s_first_data_block; /* First Data Block */
393 __le32 s_log_block_size; /* Block size */
394 __le32 s_log_frag_size; /* Fragment size */
395 /*20*/ __le32 s_blocks_per_group; /* # Blocks per group */
396 __le32 s_frags_per_group; /* # Fragments per group */
397 __le32 s_inodes_per_group; /* # Inodes per group */
398 __le32 s_mtime; /* Mount time */
399 /*30*/ __le32 s_wtime; /* Write time */
400 __le16 s_mnt_count; /* Mount count */
401 __le16 s_max_mnt_count; /* Maximal mount count */
402 __le16 s_magic; /* Magic signature */
403 __le16 s_state; /* File system state */
404 __le16 s_errors; /* Behaviour when detecting errors */
405 __le16 s_minor_rev_level; /* minor revision level */
406 /*40*/ __le32 s_lastcheck; /* time of last check */
407 __le32 s_checkinterval; /* max. time between checks */
408 __le32 s_creator_os; /* OS */
409 __le32 s_rev_level; /* Revision level */
410 /*50*/ __le16 s_def_resuid; /* Default uid for reserved blocks */
411 __le16 s_def_resgid; /* Default gid for reserved blocks */
super block的几个重要成员
1、Magic 签名
对于ext2和ext3文件系统来说,这个字段的值应该正好等于0xEF53。如果不等的话,那么这个硬盘分区上肯定不是一个正常的ext2或ext3文件系统。
2、s_log_block_size
从这个字段,我们可以得出真正的block的大小。我们把真正block的大小记作B,B=1 << s_log_block_size + 10),单位是bytes。举例来说,如果这个字段是0,那么block的大小就是 1024bytes,这正好就是最小的block大小;如果这个字段是2,那么block大小就是4096 bytes。从这里我们就得到了block的大小这一非常重要的数据。
3、s_blocks_count和s_blocks_per_group
通过这两个成员,我们可以得到硬盘分区上一共有多少个block group,或者说一共有多少个group descriptors
s_blocks_count记录了硬盘分区上的block的总数,而 s_blocks_per_group记录了每个group中有多少个block。显然,文件系统上的block groups数量,我们把它记作G,G=(s_blocks_count-s_first_data_block- 1)/s_blocks_per_group+1。为什么要减去s_first_data_block,因为s_blocks_count是硬盘分区上全 部的block的数量,而在s_first_data_block之前的block是不归block group管的,所以当然要减去。最后为什么又要加一,这是因为尾巴上可能多出来一些block,这些block我们要把它划在一个相对较小的group 里面。
4、s_inodes_per_group
s_inodes_per_group记载了每个block group中有多少个inode。在从已知的inode号,读取这个inode数据的过程中,s_inodes_per_group起到了至关重要的作用。
用我们得到的inode号数除以s_inodes_per_group,我们就知道了我们要的 这个inode是在哪一个block group里面,这个除法的余数也告诉我们,我们要的这个inode是这个block group里面的第几个inode;然后,我们可以先找到这个block group的group descriptor,从这个descriptor,我们找到这个group的inode table,再从inode table找到我们要的第几个 inode,再以后,我们就可以开始读取inode中的用户数据了。这个公式是这样的:
block_group = (ino - 1) / s_inodes_per_group。这里ino就是我们的inode号数
offset = (ino - 1) % s_inodes_per_group,这个offset就指出了我们要的inode是这个block group里面的第几个inode。
Linux下对superblock的理解的更多相关文章
- Linux下对于makefile的理解
什么是makefile呢?在Linux下makefile我们可以把理解为工程的编译规则.一个工程中源文件不计数,其按类型.功能.模块分别放在若干个目录中,makefile定义了一系列的规则来指定,那些 ...
- Linux下对于inode的理解
0x01 什么是inode 文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector),每个扇区储存512字节: 操作系统读取硬盘时,不会一个个扇区地读取,这样效率低,而是一次性连续读取多个扇区 ...
- linux下logrotate 配置和理解
对于Linux 的系统安全来说,日志文件是极其重要的工具.系统管理员可以使用logrotate 程序用来管理系统中的最新的事件,对于Linux 的系统安全来说,日志文件是极其重要的工具.系统管理员可以 ...
- Linux下线程池的理解与简单实现
首先,线程池是什么?顾名思义,就是把一堆开辟好的线程放在一个池子里统一管理,就是一个线程池. 其次,为什么要用线程池,难道来一个请求给它申请一个线程,请求处理完了释放线程不行么?也行,但是如果创建线程 ...
- linux下logrotate配置和理解---转
http://os.51cto.com/art/200912/167478_all.htm 对于Linux 的系统安全来说,日志文件是极其重要的工具.系统管理员可以使用logrotate 程序用来管理 ...
- [转]linux下logrotate 配置和理解
转自:http://blog.csdn.net/cjwid/article/details/1690101 对于Linux 的系统安全来说,日志文件是极其重要的工具.系统管理员可以使用logrotat ...
- 对于linux下system()函数的深度理解(整理)
原谅: http://blog.sina.com.cn/s/blog_8043547601017qk0.html 这几天调程序(嵌入式linux),发现程序有时就莫名其妙的死掉,每次都定位在程序中不同 ...
- 转:对于linux下system()函数的深度理解(整理)
这几天调程序(嵌入式linux),发现程序有时就莫名其妙的死掉,每次都定位在程序中不同的system()函数,直接在shell下输入system()函数中调用的命令也都一切正常.就没理这个bug,以为 ...
- 【转】Linux目录下/dev/shm的理解和使用
一般来说,现场部署 都要根据内存的大小来设定/dev/shm的大小,大部分使用的是默认的值! Linux目录下/dev/shm的理解和使用 [日期:2014-05-16] 来源:Linux社区 作 ...
随机推荐
- JDBC 基本语法总结
实现JDBC操作: 静态SQL执行 ① 注册驱动 Class.forName("com.mysql.jdbc.Driver"); ② 创建连接 Connection con = D ...
- css分层,实现遮罩底层弹出新窗口里可以操作,最下层能看到单不能操作
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Spring @Transactional 浅谈
一般当我们在一个方法里面操作多个数据对象的可持久化操作时,我们通常这些操作能够成功一起事务提交成功.默认情况下,数据库处于自动提交模式.每一条语句处于一个单独的事务中,在这条语句执行完毕时,如果执行成 ...
- (78)zabbix值缓存(value cache)说明
在zabbix-2.2版本之前,zabbix计算trigger与calculated/aggregate值都是直接通过sql语句查询并处理出来的结果,为了提高这块的性能与效率,zabbix引入了val ...
- python字典形list 去重复
data_list = [{"}] run_function = lambda x, y: x if y in x else x + [y] return reduce(run_functi ...
- react与微信小程序
由组员完成 原文链接 都说react和微信小程序很像,但是像在什么部分呢,待我稍作对比. 生命周期 1.React React的生命周期在16版本以前与之后发生了重大变化,原因在于引入的React F ...
- docker安装后无法启动问题
问题报错: Error starting daemon: Error initializing network controller: list bridge addresses failed: no ...
- 本地已经存在的项目如何跟github发生关联
切换到本地项目地址 git init 初始化项目.该步骤会创建一个 .git文件夹是附属于该仓库的工作树. git add . git commit -am 'initial commit' git ...
- Python知识点入门笔记——特色数据类型(元组)
元组(tuple)是Python的另一种特色数据类型,元组和列表是相似的,可以存储不同类型的数据,但是元组是不可改变的,创建后就不能做任何修改操作. 创建元组 用逗号隔开的就是元组,但是为了美观和代码 ...
- 一个batch的数据如何做反向传播
一个batch的数据如何做反向传播 对于一个batch内部的数据,更新权重我们是这样做的: 假如我们有三个数据,第一个数据我们更新一次参数,不过这个更新只是在我们脑子里,实际的参数没有变化,然后使用原 ...