python cookbook第三版学习笔记三:列表以及字符串
过滤序列元素:
有一个序列,想从其中过滤出想要的元素。最常用的办法就是列表过滤:比如下面的形式:这个表达式的意义是从1000个随机数中选出大于400的数据
test=[]
for i in range(1000):
test.append(random.randint(1,1000))
ret=[n for n in test if n >400]
根据cookbook书上的描述,这个方法适用于小数据的方式。如果数据集非常的大,而且要考虑内存的话建议使用生成器的方式ret=(n for n in test if n >400)
def filter_data(n):
start=time.time()
test=[]
for i in range(n):
test.append(random.randint(1,n))
ret=[n for n in test if n >400]
end=time.time()
print 'Time using list iterater is %s' % (end-start)
start=time.time()
test=[]
for i in range(n):
test.append(random.randint(1,n))
ret=(n for n in test if n >400)
end=time.time()
print 'Time using generater is %s' % (end-start)
我们先看下n=1000的运行结果:
filter_data(1000) 时间都差不多,看不出差别

N=10000的运行结果 用生成器要少于列表过滤的方法
filter_data(10000)

N=100000的运行结果 差距进一步拉大
filter_data(100000)

可以看出随着数据的扩大,确实生成器更能节省时间。
如果我们有两个列表,一个是存储信息的,一个是存储该信息的特征值的时候。我们想吧满足某种特征值的信息提取出来该如何操作呢。这里有个过滤工具itertools.compress
假设我们有下列数据,address存放的是具体的地址信息,count值对应的是各个地址信息的特征值。两者的索引是一一对应
addresses = [
'5412 N CLARK',
'5148 N CLARK',
'5800 E 58TH',
'2122 N CLARK'
'5645 N RAVENSWOOD',
'1060 W ADDISON',
'4801 N BROADWAY',
'1039 W GRANVILLE',
]
counts=[0,3,10,4,1,7,6,1]
如果我们想把特征值大于5的地址信息提取出来。其实方法也比较简单,如下是没有依赖任何模块的写法,也就是通过两个列表一一判断。
for i in range(len(addresses)):
if counts[i] >= 5:
tmp.append(addresses[i])
print tmp
compress的用法如下:首先生成一个feature的列表,这个feature列表根据生成式生成一个满足条件的过滤表。然后调用compress,第一个参数是原始数据,第二个参数是过滤条件。
feature=[n>=5 for n in counts]
print feature
print list(compress(addresses,feature))
两种方法比较,如果过滤条件已经具备,那么使用compress更方便一些。否则从我个人感觉来看没有什么差别。
分割字符串:
如果我们有这样的字符串:字符全部以,为分隔符
line='asdf,fjdk,afed,fjek,asdf,foo'
print line.split(',')
我们可以用字符串自带的split功能进行分割,参数携带分割符号就可以了
但是如果字符是这样的形式:
line='asdf fjdk;afed,fjek,asdf, foo'
可以看到字符串的分隔符不固定,有空格 ; , ,+空格多种形式。那么单纯的用一个分隔符号就搞不定了。这个时候正则表达式就派上用场了。我们先看下正则表达式的用法。参考如下的表格

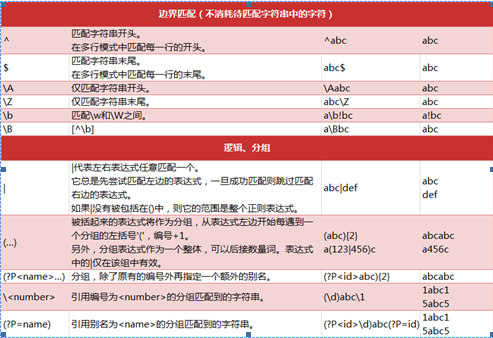

用如下的方式进行分割
print re.split(r'[;,\s]\s*',line)
通过上面的表格可以了解到正则表达式的用法,[]是各种可能出现的符号。然后加上0个或者无限个空格。
即使我们的字符串改成如下的形式,asdf和foo之前有一个,以及多个空格。该方式也能正确的分割出字符
line='asdf fjdk;afed,fjek,asdf, foo'
这里的分割方法只是将字符给分割出来了,如果我们想同时得到分隔符该如何处理呢。这里可以用到分组处理。
print re.split(r'(;|,|\s)\s*',line)
用()分组的方式取代[],然后用|进行分割。通过前面的正则表达式可以了解到这个2个符号的用法。返回的结果如下:可以看到分割符也包含在里面了
['asdf', ' ', 'fjdk', ';', 'afed', ',', 'fjek', ',', 'asdf', ',', 'foo']
如果你仍然想使用分组捕获但是不想分割符好出现,可以用(?:....)非捕获分组的形式。如下,这样的效果就和re.split(r'[;,\s]\s*',line)的效果一致
re.split(r'(?:,|;|\s)\s*', line)
具体的正则表达式用法可以参考<正则表达式>这本书,里面介绍得很详细。对于字符串处理来说,正则表达式可以达到事半功倍的效果。值得好好学学
python cookbook第三版学习笔记三:列表以及字符串的更多相关文章
- 《Linux命令、编辑器与shell编程》第三版 学习笔记---002
<Linux命令.编辑器与shell编程>第三版 学习笔记---001 Linux命令.编辑器与shell编程 Shell准备 1.识别Shell类型 echo $0 echo $BAS ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- python cookbook第三版学习笔记十:类和对象(一)
类和对象: 我们经常会对打印一个对象来得到对象的某些信息. class pair: def __init__(self,x,y): self.x=x self. ...
- python cookbook第三版学习笔记六:迭代器与生成器
假如我们有一个列表 items=[1,2,3].我们要遍历这个列表我们会用下面的方式 For i in items: Print i 首先介绍几个概念:容器,可迭代对象,迭代器 容器是一种存储数据 ...
- python cookbook第三版学习笔记 一
数据结构 假设有M个元素的列表,需要从中分解出N个对象,N<M,这会导致分解的值过多的异常.如下: record=['zhf','zhf@163.com','775-555-1212','847 ...
- python cookbook第三版学习笔记十三:类和对象(三)描述器
__get__以及__set__:假设T是一个类,t是他的实例,d是它的一个描述器属性.读取属性的时候T.d返回的是d.__get__(None,T),t.d返回的是d.__get__(t,T).说法 ...
- python cookbook第三版学习笔记二十:可自定义属性的装饰器
在开始本节之前,首先介绍下偏函数partial.首先借助help来看下partial的定义 首先来说下第一行解释的意思: partial 一共有三个部分: (1)第一部分也就是第一个参数,是一个函数, ...
- python cookbook第三版学习笔记七:python解析csv,json,xml文件
CSV文件读取: Csv文件格式如下:分别有2行三列. 访问代码如下: f=open(r'E:\py_prj\test.csv','rb') f_csv=csv.reader(f) for f in ...
- python cookbook第三版学习笔记十三:类和对象(四)描述器
__get__以及__set__:假设T是一个类,t是他的实例,d是它的一个描述器属性.读取属性的时候T.d返回的是d.__get__(None,T),t.d返回的是d.__get__(t,T).说法 ...
随机推荐
- UIView和UIImageView 旋转消除锯齿方法
方法一: calendarImageView_ =[[UIImageView alloc] initWithFrame:CGRectMake(3,3,60,72)]; calendarImag ...
- MFC中 CDateTimeCtrl 自定义日期显示格式
MFC里的DateTimePicker控件 ,通过属性来设置的话只能设置两种显示方式,要么日期,要么时间,很多时候我们需要在一个DateTimePicker里日期和时间同时显示. 这个时候只能通过自定 ...
- 规划设计系列3 | SketchUp+实景三维,方案现状一起看
将SketchUp中建立的模型与实景三维模型进行集成,既可以充分发挥实景三维在地理空间记录方面的优势,又可以去除SketchUp在周边环境设计上的不足. 同时借助Wish3D Earth丰富的场景浏览 ...
- linux中seq命令用法
NAME seq - print a sequence of numbers SYNOPSIS seq [OPTION]... LAST seq [OPTION]... FIRST LAST seq ...
- VC++动态链接库(DLL)编程深入浅出(二)
好,让我们正式进入动态链接库的世界,先来看看最一般的DLL,即非MFC DLL 上节给大家介绍了静态链接库与库的调试与查看,本节主要介绍非MFC DLL. 4.非MFC DLL 4.1一个简单的DLL ...
- mysqldumps 远程备份
普通模式 mysqldump -uroot -ppassword -h10.26.114.25 -P3306 --databases databasename > XXX.sql 多条在一起模式 ...
- AudioSession/AudioCaptureSession的分析与使用
这个是AudioSession的结构图: 前一个部分已经介绍了AVFoundation对音频录制.播放的一种方法,以下再介绍第二种: AVCaptureSession 用这个类的长处在什么地方呢? ( ...
- fastJson 转换日期格式
第一种方法: JSON.DEFFAULT_DATE_FORMAT = "yyyy-MM-dd"; String str = JSON.toJSONString(user,Seria ...
- 【Android实战】Gallary+ImageSwicther图片查看器
仿照如今各大新闻站点图片新闻的浏览模式,上面展示详细图片(ImageSwitch),以下是能够滑动的小图片(Gallery). 当中须要注意的是ImageSwitch须要定义一个工厂返回的组件,而且能 ...
- 在Mac OS X中下载Android源代码的一些经验
首先说明.随着最近(2014年6月開始)GFW的升级.这个站点:http://www.android.com/ 已经不能正常訪问了,以下的这些操作均是在我连接VPN的时候进行的. 首先,须要做一些准备 ...