如何实现高性能的IO及其原理?
程序运行在内存以及IO的体现
首先普及一下常识,如图所示:
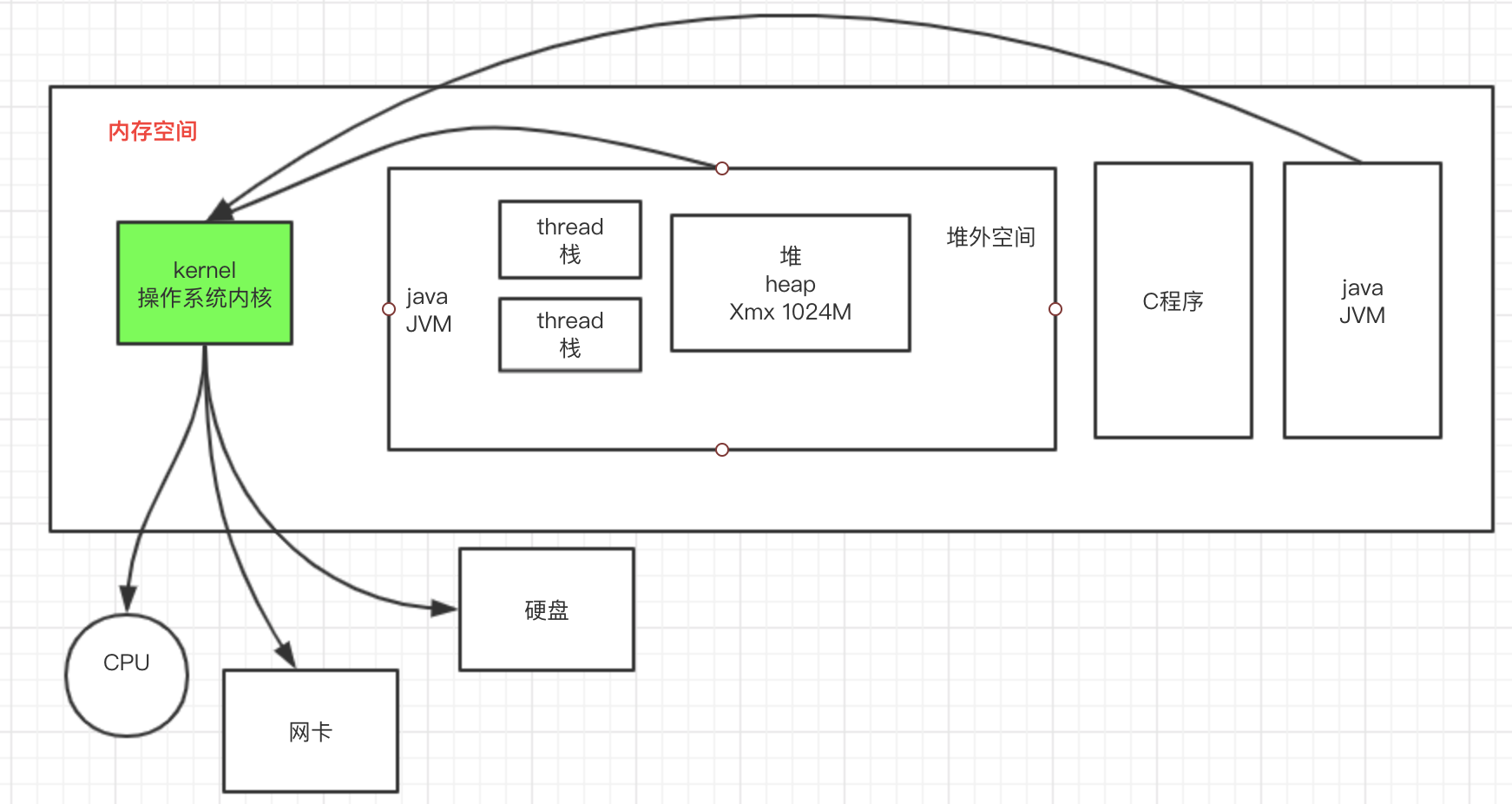
1、在整个内存空间中,跑着各种各样的程序,有Java程序、C程序,他们共用一块内存空间。
2、对于Java程序,JVM会申请一块堆空间,通过Xmx可以设置,其余空间是堆外空间,其中每个线程有自己的线程栈,保证线程内存隔离,堆空间使用完以后,会触发Full FC,堆外空间所有进程可共享使用,无限制。
3、所有系统运行的程序都必须通过操作系统内核进行IO操作,操作系统也是程序,也需要一定的内存空间。
一、使用Buffer代替基本IO
我们写一个方法,此方法使用了FileWriter进行了文件的写操作,我们都知道不调用flush()可能会造成数据丢失,那么为什么呢,flush操作到底做了些什么呢?
public void fileIO() throws Exception {
File file = new File("/Volumes/work/temp/temp.txt");
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileInputStream fileInputStream = new FileInputStream(file);
FileWriter fileWriter = new FileWriter(file);
fileWriter.write("hello");
fileWriter.write("world");
fileWriter.write("\nhello world");
Thread.sleep(99999);
fileWriter.flush();
fileWriter.close();
}
我们知道我们在写数据的时候不管是C还是Java都会有两个缓冲区,一个是操作系统的缓冲区sys buffer,还有一个是程序的缓冲区program buffer。那么刚刚的flush操作是把程序的缓冲区内容写到了系统缓冲区,还是把系统缓冲区的内容刷到了硬盘呢?因此我们在调用flush()之前进行了sleep操作,检查在flush之前,具体的内容并未写到temp.txt文件中,当我们睡眠时间结束后,可以看到调用flush方法后则把内容写到了文件中,如图:

实际上FileWriter基本IO是没有先写程序缓存的,那么实际上FileWriter的每次write操作都发生了系统调用,直接写到了内核的系统缓冲区,然后当调用flush操作时,系统缓冲区的内容再刷到了硬盘上。
因此IO性能提升第一步:无论是InputStream还是FileWriter,都是底层的IO,是直接调用内核的,因此写入都是直接写入到内核的系统buffer,因此在使用IO的时候不要使用这类底层IO,否则发生大量系统调用,降低系统性能,而是应该先写到程序buffer然后再调用系统IO,当程序buffer满了后才通过系统调用写到系统buffer空间中,这样减少了大量系统调用,提升了性能。
那么什么时候系统buffer中的数据才写入到硬盘呢?2种情况:①.系统buffer满了;②.执行了flush()操作,也就是发生了fsync的系统调用。
public void bufferedIO() throws Exception {
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(file), 1024);
BufferedReader reader = new BufferedReader(new FileReader(file));
bufferedOutputStream.write("hello world\nhello world".getBytes());
bufferedOutputStream.flush();
bufferedOutputStream.close();
String line = reader.readLine();
System.out.println(line);
}
还有另一种是直接写入到内存的,如代码:
public void memoryIO() throws Exception {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(1024);
// 字节数组输出流在内存中创建一个字节数组缓冲区,所有发送到输出流的数据保存在该字节数组缓冲区中。可以通过toString()和toByteArray()获取数据
byteArrayOutputStream.write("hello world".getBytes());
String string = byteArrayOutputStream.toString();
System.out.println(string);
byte[] inData = byteArrayOutputStream.toByteArray();
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(inData);
byte[] data = new byte[1024];
byteArrayInputStream.read(data);
System.out.println(new String(data));
byteArrayOutputStream.flush();
byteArrayOutputStream.close();
}
这样就类似于Redis一样,是对内存进行直接操作,因此这样也能提高不少效率。
二、堆外内存mmap直接映射内核空间
如下图:
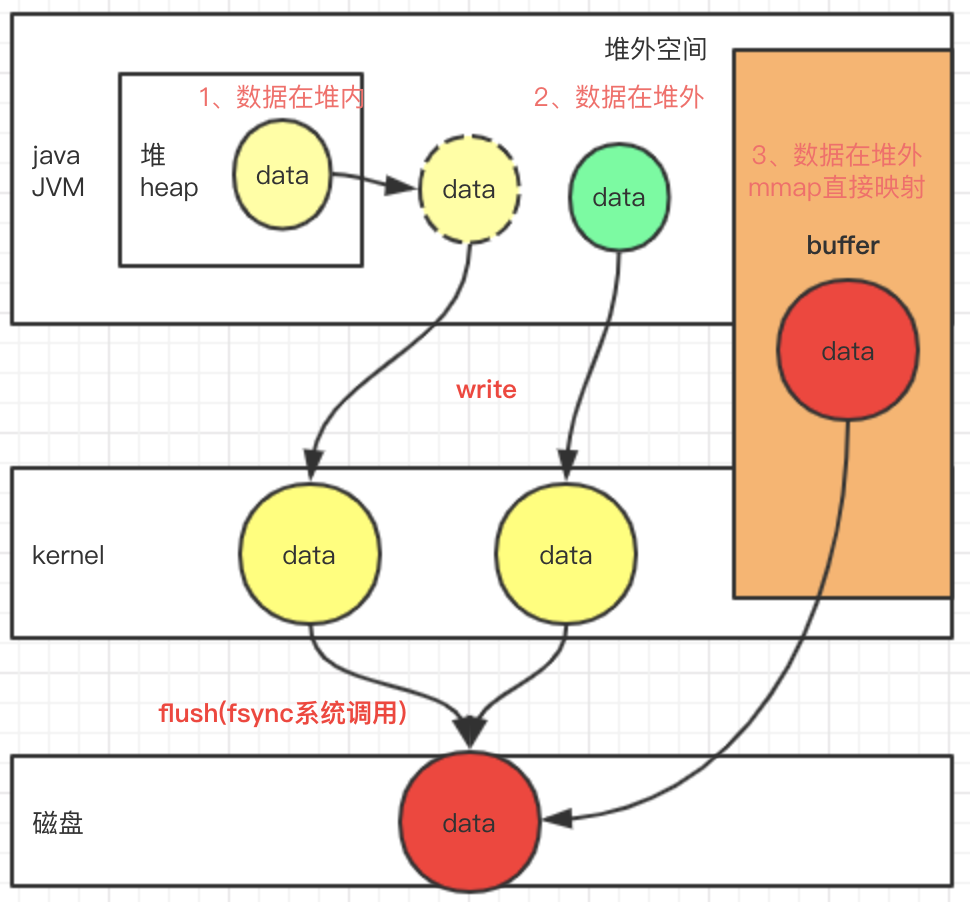
1、如果数据在堆内,那么在写入磁盘时,会先序列化后拷贝到堆外,然后堆外再write到系统内核缓冲区,内核缓冲区通过系统调用fsync写入到磁盘;
2、如果数据是在堆外内存,那么也需要先拷贝到内核缓冲区,在fsync系统调用后也才写入到磁盘;
3、通过系统调用mmap申请一块虚拟的地址空间,这片空间用户程序和系统内核都可以访问到。
如下代码:
public void randomIO() throws Exception{
RandomAccessFile randomAccessFile = new RandomAccessFile(file,"rw");
randomAccessFile.write("hello world\nhello chicago\nhello ChengDu".getBytes());
FileChannel channel = randomAccessFile.getChannel();
/**
* 堆外的数据如果想写磁盘,通过系统调用,经历数据从用户空间拷贝到内核空间
* 堆外mapedBuffer的数据内核直接处理
*/
// 分配在了堆上 heap空间
// ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 分配在了堆外 offheap空间
// ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
//mmap 内核系统调用 堆外空间,直接映射
MappedByteBuffer byteBuffer = channel.map(FileChannel.MapMode.READ_WRITE,0,2018);
byteBuffer.put("byteBuffer testing".getBytes());
randomAccessFile.seek(12);
randomAccessFile.write("*****".getBytes());
}
可以看到通过FileChannel的map方法实现系统调用,申请mmap直接映射空间,数据无需由用户空间拷贝到系统空间,节省了一次拷贝的时间损耗,提升了性能。
三、sendfile零拷贝
在Linux系统中。存储在文件中的信息通过网络传送给客户这样的简单过程中,所涉及的操作。下面是其中的部分简单代码:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
其实过程中实现了多次拷贝,性能很低,如图可知:

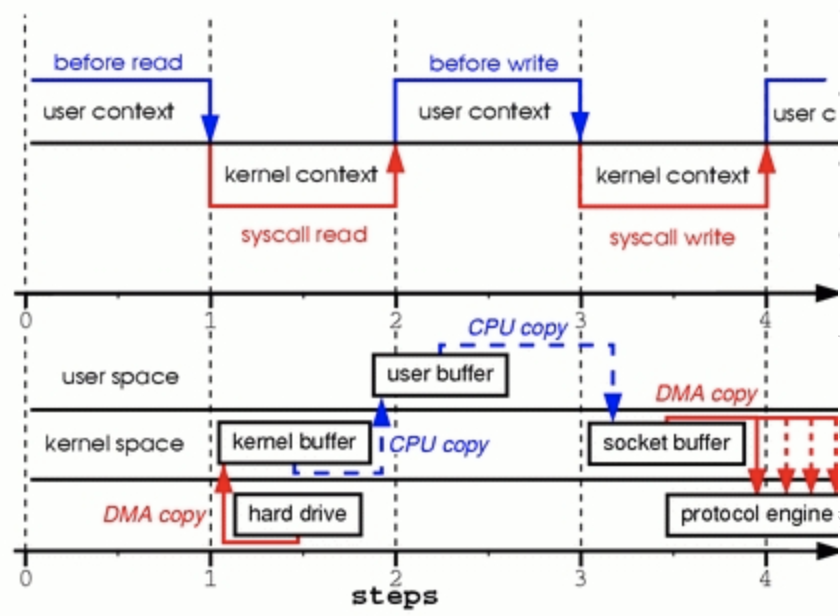
步骤一:系统调用read导致了从用户空间到内核空间的上下文切换。DMA模块从磁盘中读取文件内容,并将其存储在内核空间的缓冲区内,完成了第1次复制。
步骤二:数据从内核空间缓冲区复制到用户空间缓冲区,完成了第2次复制,之后系统调用read返回,这导致了从内核空间向用户空间的上下文切换。此时,需要的数据已存放在指定的用户空间缓冲区内(参数tmp_buf),程序可以继续下面的操作。
步骤三:系统调用write导致从用户空间到内核空间的上下文切换。数据从用户空间缓冲区被再次复制到内核空间缓冲区,完成了第3次复制。不过,这次数据存放在内核空间中与使用的socket相关的特定缓冲区中,而不是步骤一中的缓冲区。
步骤四:系统调用返回,导致了第4次上下文切换。第4次复制在DMA模块将数据从内核空间缓冲区传递至协议引擎的时候发生,这与我们的代码的执行是独立且异步发生的。你可能会疑惑:“为何要说是独立、异步?难道不是在write系统调用返回前数据已经被传送了?write系统调用的返回,并不意味着传输成功——它甚至无法保证传输的开始。调用的返回,只是表明以太网驱动程序在其传输队列中有空位,并已经接受我们的数据用于传输。可能有众多的数据排在我们的数据之前。除非驱动程序或硬件采用优先级队列的方法,各组数据是依照FIFO的次序被传输的(图1中叉状的DMA copy表明这最后一次复制可以被延后)。
因此就诞生了零拷贝:
sendfile(socket, file, len);
如图:
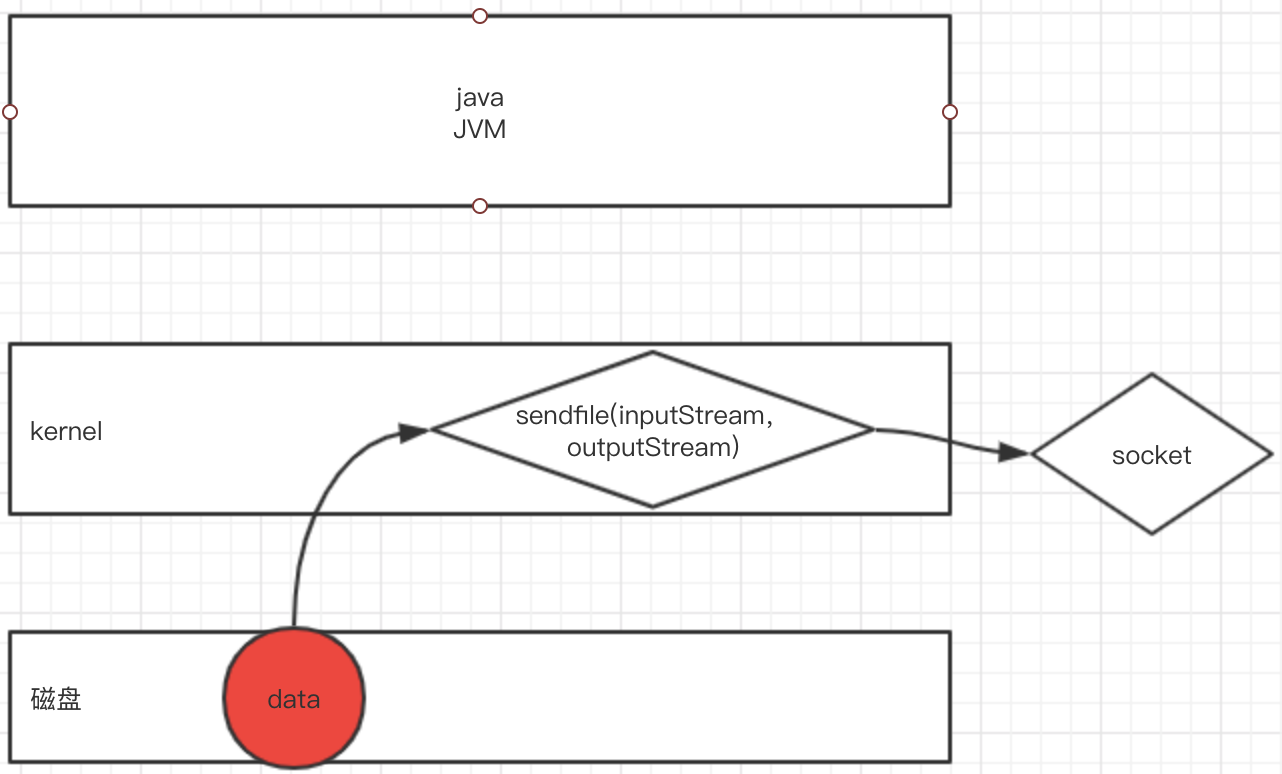
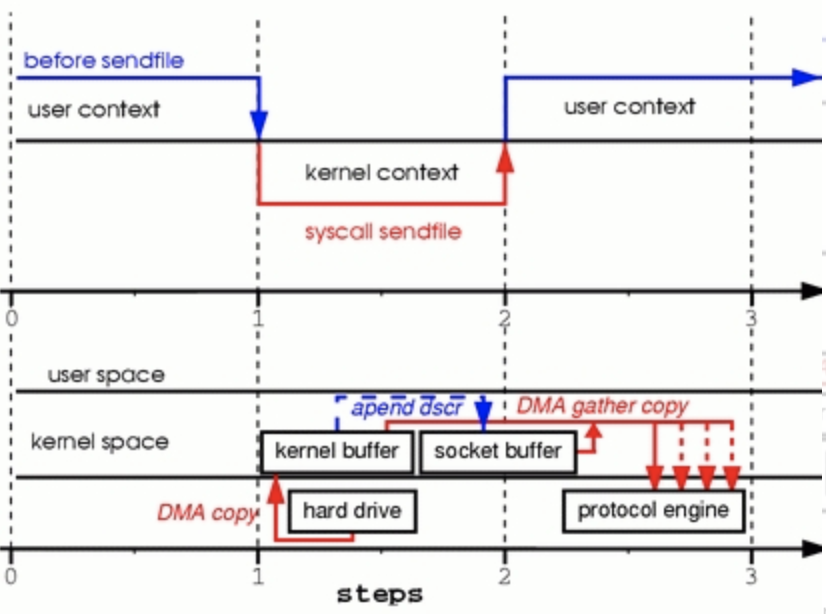
步骤一:sendfile系统调用导致文件内容通过DMA模块被复制到内核缓冲区中。
步骤二:记录数据位置和长度的描述符被加入到socket缓冲区中,DMA模块将数据直接从内核缓冲区传递给协议引擎。
基于以上实现,最终实现了“零拷贝”。
高性能IO应用
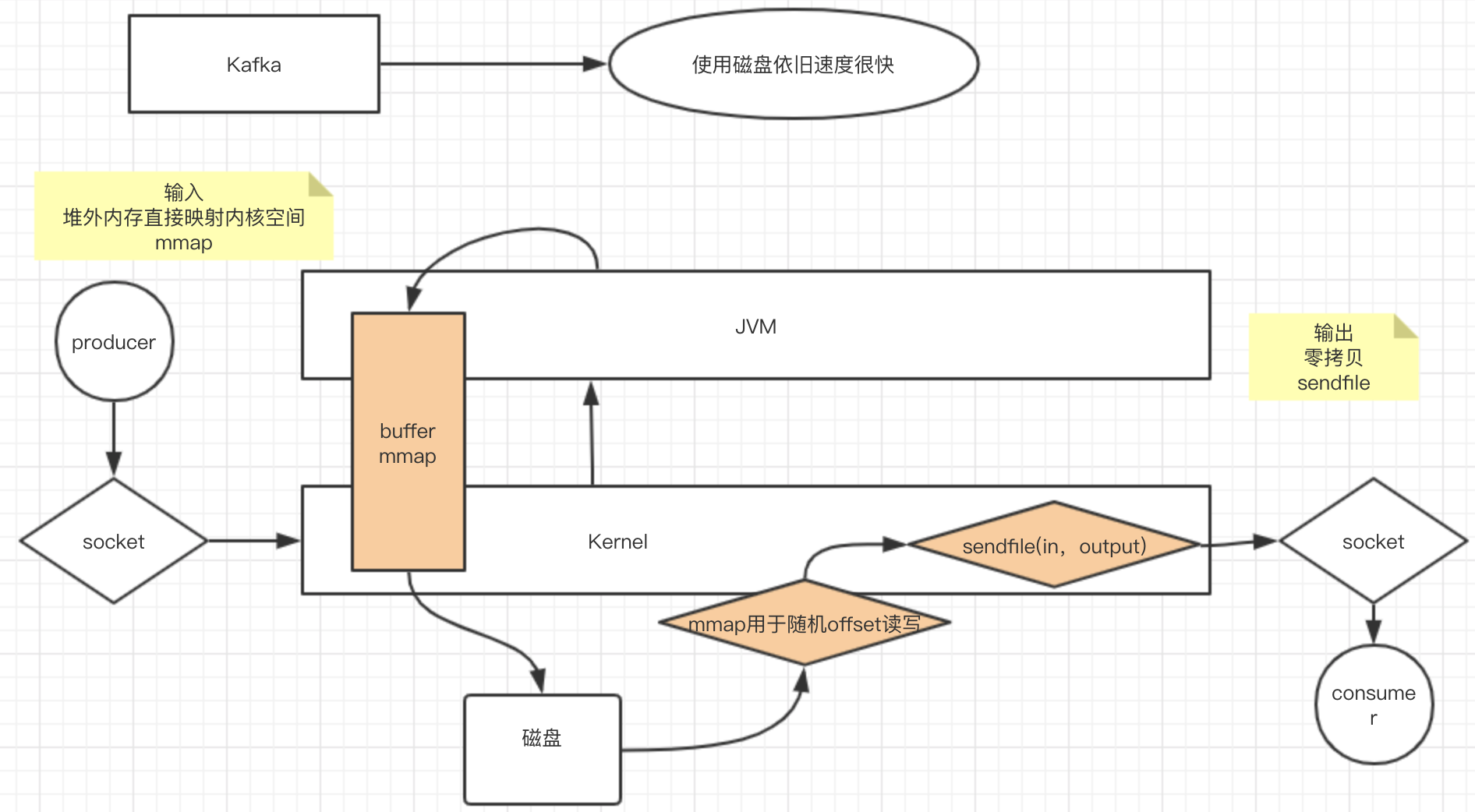
在现实应用中,Kafka常用来进行日志处理,存在着大量的IO,其高性能就是建立在IO上的优化,如图:
如何实现高性能的IO及其原理?的更多相关文章
- 服务器端高性能的IO模型 转自酷勤网
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(BlockingIO):即传统的IO模型. (2)同步非阻塞IO(Non-blockingIO):默认创建的soc ...
- 单片机小白学步系列(二十) IO口原理
IO口操作是单片机实践中最基本最重要的一个知识,本篇花了比較长的篇幅介绍IO口的原理. 也是查阅了不少资料,确保内容正确无误,花了非常长时间写的. IO口原理原本须要涉及非常多深入的知识,而这里尽最大 ...
- IO多路复用原理
(1)IO multiplexing(2)用在什么地方?多路非阻塞式IO.(3)select和poll(4)外部阻塞式,内部非阻塞式自动轮询多路阻塞式IO IO多路复用原理:其实就是整个函数对外表现为 ...
- Netty(RPC高性能之道)原理剖析
转载:http://blog.csdn.net/zhiguozhu/article/details/50517551 1,Netty简述 Netty 是一个基于 JAVA NIO 类库的异步通信框架, ...
- 聊聊redis单线程为什么能做到高性能和io多路复用到底是个什么鬼
1:io多路复用epoll io多路复用简单来说就是一个线程处理多个网络请求 我们知道epoll in 的事件触发是可读了,这个比较好理解,比如一个连接过来,或者一个数据发送过来了,那么in事件就触 ...
- 非阻塞IO模式原理
与阻塞模式对应的另一种模式叫非阻塞IO模式,在整个通信过程中读和写操作不会阻塞,当前处理线程不存在阻塞情况.从A机器到B机器它的通信过程是:A机器一条线程将通道设置为写事件后往下执行,而另外一条线程遍 ...
- 高性能 C++ HTTP 客户端原理与实现
一.什么是Http Client Http协议,是全互联网共同的语言,而Http Client,可以说是我们需要从互联网世界获取数据的最基本方法,它本质上是一个URL到一个网页的转换过程.而有了基本的 ...
- IO多路复用原理&场景
目录 IO多路复用的历史 阻塞 IO 非阻塞 IO IO 多路复用 select poll epoll IO多路复用高效的原因 IO多路复用解决的什么问题 epoll比selector性能一定更好吗 ...
- IO流原理及流的分类
IO原理 I/O是Input/Output的缩写, I/O技术是非常实用的技术,用于 处理设备之间的数据传输.如读/写文件,网络通讯等. Java程序中,对于数据的输入/输出操作以"流(st ...
随机推荐
- Qt编写自定义控件65-光晕日历
一.前言 操作系统的更新迭代速度非常快,基本上三五年就有个新版本出来,WIN10操作系统还是一个比较成功的系统,据说现在市场份额越来越大,XP的份额已经很小,WIN7的份额也在逐步减少,在最新的WIN ...
- 使用SoapUI测试wsdl
webservice服务wsdl地址:http://localhost:8080/services/HelloWorld?wsdl new project: new soap project: 调用测 ...
- 《Learning a Discriminative Feature Network for Semantic Segmentation》解读
旷世18年的CVPR,论文链接:https://arxiv.org/abs/1804.09337 Motivation:针对分割中的“类内不一致”和“类间一致性”的两大问题,设计了结合Smooth n ...
- 小程序报错 thirdScriptError
thirdScriptError sdk uncaught third Error Unexpected token export SyntaxError: Unexpected token expo ...
- 迅速生成项目-react-static
推荐指数:
- 详解consul的安装和配置
Consul 简化了分布式环境中的服务的注册和发现流程,通过 HTTP 或者 DNS 接口发现.支持外部 SaaS 提供者等. consul提供的一些关键特性: service discovery:c ...
- php+memcache高速缓存
原文地址:https://blog.csdn.net/qq_33571752/article/details/86494667 #在lnmp基础上修改 依赖libevent程序库 cd lnmp/ta ...
- Appium移动自动化测试-----(六)2.AppiumDesktop录制脚本生成极简脚本
AppiumDesktop启动页面: 启动AppiumDesktop以后点击该页面右上角的Start New Session按钮,就会启动一个新的会话窗口(如下图),在这个窗口我们需要配置一些Desi ...
- 2019.12.12 Java的多线程&匿名类
Java基础(深入了解概念为主) 匿名类 定义 Java匿名类很像局部或内联系,只是没有明细.我们可以利用匿名类,同时定义并实例化一个类.只有局部类仅被使用一次时才应该这么做. 匿名类不能有显式定义的 ...
- php 微服务
https://neatlifecoco.com/15618891575018.html https://juejin.im/post/5d3927816fb9a07ee27b58df https:/ ...