python中的apply(),applymap(),map() 的用法和区别
平时在处理df series格式的时候并没有注意 map和apply的差异
总感觉没啥却别。不过还是有区别的。下面总结一下:
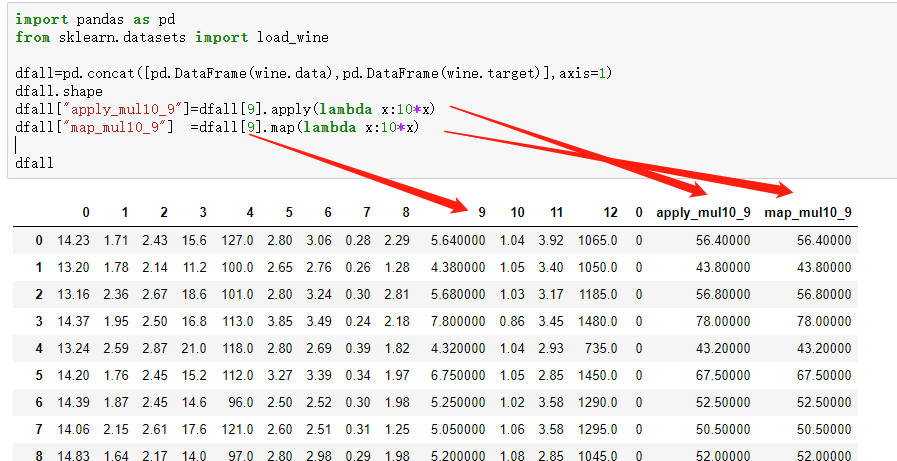
import pandas as pd
df1= pd.DataFrame({
"sales1":[-,,],
"sales2":[,-,],
})
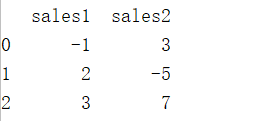
1.apply
1、当我们要对数据框(DataFrame)的数据进行按行或按列操作时用apply()
note:操作的原子是行和列 ,可以用行列统计描述符 min max mean ......
当axis=0的时候是对“列”进行操作
df2=df1.apply(lambda x: x.max()-x.min(),axis=0)
print(type(df2),"\n",df2)

axis=1的时候是对“行”进行操作
df3=df1.apply(lambda x: x.max()-x.min(),axis=1)
print(type(df3),"\n",df3)

2.也可以直接选定一列series,或者df直接操作
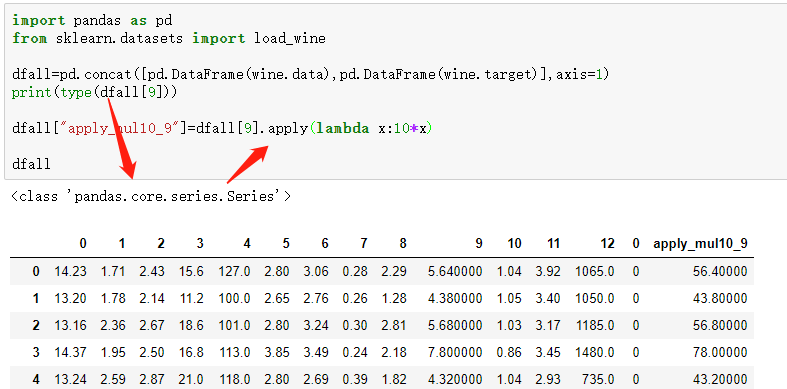
2.applymap
1.applymap函数之后,自动对DataFrame每一个元素进行处理,判断之后输出结果
df4=df1.applymap(lambda x: x>0)
print(type(df4),"\n",df4)

2.applymap是对 DataFrame 进行每个元素的单独操作
ie:不能添加列统计函数,因为是只针对单个元素的操作
df5=df1.applymap(lambda x: x.min())
print(type(df5),"\n",df5)

3.'Series' object has no attribute 'applymap'
df4=df1["sales1"].applymap(lambda x: x>0)
print(type(df4),"\n",df4)

3.map
1.'DataFrame' object has no attribute 'map'
df4=df1.map(lambda x: x**2)
print(type(df4),"\n",df4)

2.map其实是对 列,series 等 进行每个元素的单独操作
ie:不能添加列统计函数,因为是只针对单个元素的操作
df3=df1["sales1"].map(lambda x: x.max()-x.min())
print(type(df3),"\n",df3)

3.正常
df4=df1["sales1"].map(lambda x: x**2)
print(type(df4),"\n",df4)

python中的apply(),applymap(),map() 的用法和区别的更多相关文章
- python中的filter、map、reduce、apply用法
1. filter 功能: filter的功能是过滤掉序列中不符合函数条件的元素,当序列中要删减的元素可以用某些函数描述时,就应该想起filter函数. 调用: filter(function,seq ...
- apply(), applymap(), map()
Pandas 中map, applymap and apply的区别 https://blog.csdn.net/u010814042/article/details/76401133/ Panda ...
- python中urllib, urllib2,urllib3, httplib,httplib2, request的区别
permike原文python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 若只使用python3.X, 下面可以不看了, 记住有个ur ...
- Java中集合List,Map和Set的区别
Java中集合List,Map和Set的区别 1.List和Set的父接口是Collection,而Map不是 2.List中的元素是有序的,可以重复的 3.Map是Key-Value映射关系,且Ke ...
- python中生成器对象和return 还有循环的区别
python中生成器对象和return 还有循环的区别 在python中存在这么一个关键字yield,这个关键字在项目中经常被用到,比如我写一个函数不想它只返回一次就结束那我们就不能用return,因 ...
- Python中%r和%s的详解及区别_python_脚本之家
Python中%r和%s的详解及区别_python_脚本之家 https://www.jb51.net/article/108589.htm
- python中os.path.abspath与os.path.realpath 区别
python中os.path.abspath与os.path.realpath 区别cd /homemkdir amkdir btouch a/1.txtln -s /home/a/1.txt /ho ...
- 脚本引用中的defer和async的用法和区别
之前的博客漫谈前端优化中的引用资源优化曾经提到过脚本引用异步设置defer.async,没有细说,这里展开一下,谈谈它们的作用和区别,先上张图来个针对没用过的小伙伴有个初始印象: 是的,就是在页面脚本 ...
- 浅谈JS中的!=、== 、!==、===的用法和区别 JS中Null与Undefined的区别 读取XML文件 获取路径的方式 C#中Cookie,Session,Application的用法与区别? c#反射 抽象工厂
浅谈JS中的!=.== .!==.===的用法和区别 var num = 1; var str = '1'; var test = 1; test == num //tr ...
随机推荐
- PYTHON 100days学习笔记005:总结和练习
目录 day005:总结和练习 1.寻找水仙花数 2.寻找"完美数" 3."百鸡百钱"问题 4.生成"斐波那契数列" 5.Craps赌博游戏 ...
- sshpass和做软链接
参考: https://help.aliyun.com/document_detail/54530.html?spm=5176.11065259.1996646101.searchclickresul ...
- [转帖]【架构系列】龙芯loongson简介
[架构系列]龙芯loongson简介 https://blog.csdn.net/SoaringLee_fighting/article/details/97759305 2019年07月30日 10 ...
- [转帖]Linux 下实践 VxLAN:虚拟机和 Docker 场景
Linux 下实践 VxLAN:虚拟机和 Docker 场景 https://www.cnblogs.com/bakari/p/11264520.html 实践了下 没问题 作者写的很perfect ...
- Python学习笔记:运算符
逻辑运算符: + 加 - 减 * 乘 / 除 % 取模-返回除法的余数 ** 幂-返回x的y次方 // 整除 比较运算符: == 等于-比较对象是否相等 != ...
- VirtualBox网络之仅主机(Host-Only)网络
https://blog.csdn.net/dkfajsldfsdfsd/article/details/79441874
- mysql解决fail to open file的方法
由于没有安装有mysql的可视化工具,在使用cmd导入sql文件时,使用source 命令时出现 fail to open file的错误,各种查找后使用以下方法解决了: 1.首先进入mysql数据库 ...
- 用eclipse启动tomcat时报Could not publish server configuration for Tomcat v8.0 Server at localhost..错误
网上的解决方法是: 1.如果是使用的eclipse tomcat 插件,需要在你的工作空间 找到如下文件:.metadata.plugins\org.eclipse.wst.server.cor\e\ ...
- C#实现鼠标滚筒缩放界面的效果
elementCanvas继承UserControl 声明属性: #region 缩放属性添加 float ratio = 1.0f; public float Ratio { set { ratio ...
- QT 安卓 悬浮窗权限动态申请
一:申请方式: String ACTION_MANAGE_OVERLAY_PERMISSION = "android.settings.action.MANAGE_OVERLAY_PERMI ...