struct:二进制数据结构的打包与解包
介绍
struct模块包括一些函数,这些函数可以完成字节串与原生Python数据类型(如数字和字符串)之间的转换
函数与Struct类
struct提供了一组处理结构值的模块级函数,另外还有一个Struct类,这与处理正则表达式的compile类似。
类比正则:re.match(pattern, text) 使用这种模块级别的函数时,会先将pattern进行编译转换,这个转换是耗费资源的。因此可以先对pattern进行一个编译,comp = re.compile(pattern),comp.match(text).这样的话就只需要转换一次,struct也是类似的情况,所以创建一个Struct实例并在这个实例上调用方法时(不使用模块级函数)只完成一次转换,这会更高效
打包与解包
import struct
'''
Struct支持使用格式指示符将数据打包(packing)为字符串,另外支持从字符串解包(unpacking)数据。
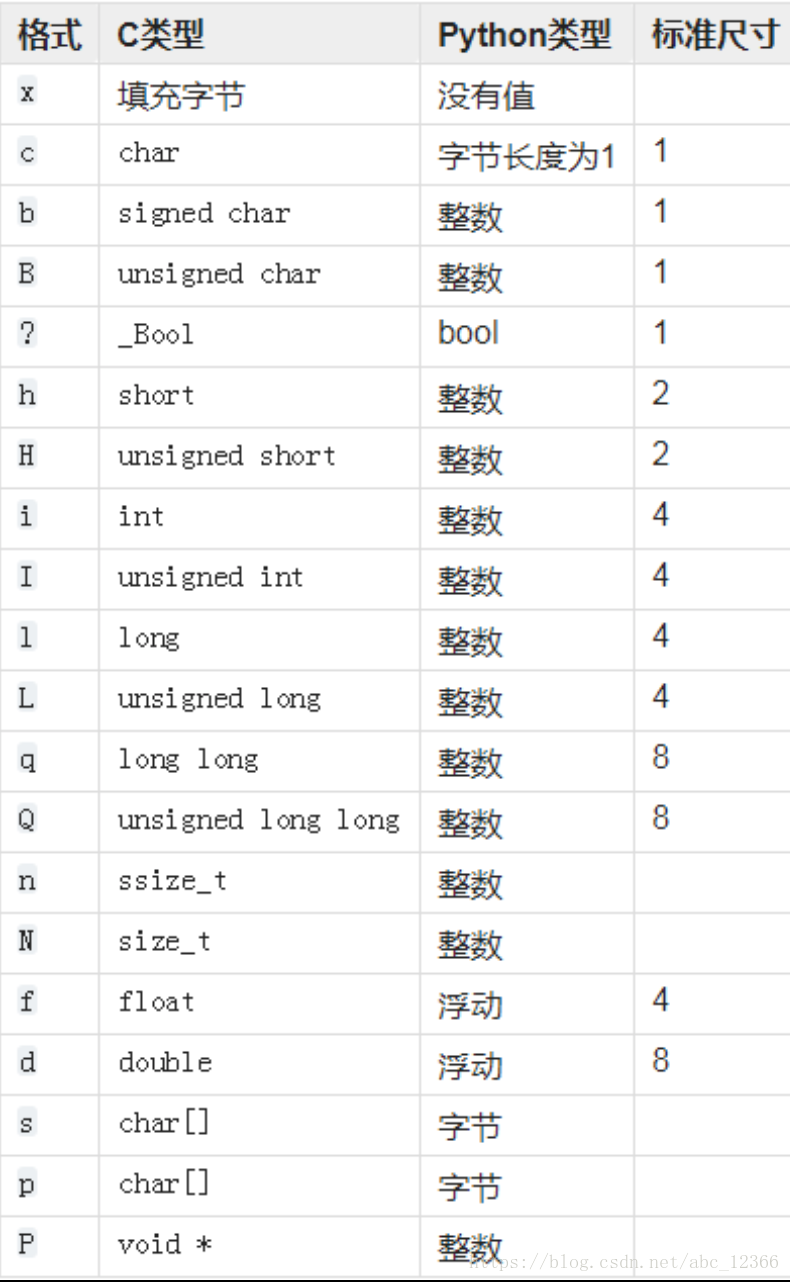
格式指示符由表示数据类型的字符和可选的数量及字节序(endianness)指示符构成。
要全面了解目前可支持的数据结构,可以参考标准库文档
'''
import binascii
# values包含一个整型或长整型,一个两字节字符串,以及一个浮点数。
values = (1, "ab".encode("utf-8"), 2.7)
# 格式指示符中包含的空格用来分割类型指示符,并且在编译格式时会被忽略
# 使用Struct定义格式,I:整型,2s:两个字节的字符,f:浮点数,之间使用空格分隔
# 表示打包的数据有三个,分别是整型,两个字节的字符,以及一个浮点
s = struct.Struct("I 2s f")
# 使用s.pack函数进行打包,将values打开传进去
packed_data = s.pack(*values) # 等价于struct.pack("I 2s f", *values)
# s:Struct对象
print(s) # <Struct object at 0x0000000002924458>
# 原始数据values
print("原始数据:", values) # 原始数据: (1, b'ab', 2.7)
# 打印一下我们的格式,也就是我们传进去的格式
print("格式化字符:", s.format) # 格式化字符: I 2s f
# 查看所用的字节
print("使用:", s.size, "bytes") # 使用: 12 bytes
# 查看打包之后的结果
print("打包后的结果:", packed_data) # 打包后的结果: b'\x01\x00\x00\x00ab\x00\x00\xcd\xcc,@'
print("将打包的结果进行转换:", binascii.hexlify(packed_data)) # 将打包的结果进行转换: b'0100000061620000cdcc2c40'
# 我们传入values,通过s.pack()得到packed_data,那么我们传入packed_data,可不可以调用一个函数反过来得到values呢?
# 答案是可以的,可以使用s.unpack()
# 值得一提的是,这个binascii.hexlify,还有一个相反的函数叫做binascii.unhexlify
print(packed_data) # b'\x01\x00\x00\x00ab\x00\x00\xcd\xcc,@'
print(binascii.hexlify(packed_data)) # b'0100000061620000cdcc2c40'
print(binascii.unhexlify(binascii.hexlify(packed_data))) # b'\x01\x00\x00\x00ab\x00\x00\xcd\xcc,@'
# 使用s.unpack()
print(s.unpack(packed_data)) # (1, b'ab', 2.700000047683716)
'''
可以看到还是可以转回来的,注意这个浮点数啊,这是计算机的存储误差,任何语言都是有这个问题的。
'''
字节序
import struct
'''
默认地,值会使用原生C库的字节序(endianness)来编码。
只需在格式中提供一个显示的字节序指令,就可以很容易地覆盖这个默认选择
'''
import binascii
values = (1, "ab".encode("utf-8"), 2.7)
print("original values:", values)
endianness = [
("@", "native, native"),
("=", "native, standard"),
("<", "little-endian"),
(">", "big-endian"),
("!", "network")
]
for code, name in endianness:
s = struct.Struct(code + " I 2s f")
packed_data = s.pack(*values)
print("*"*20)
print("Format string: ", s.format, "for", name)
print("uses: ", s.size, "bytes")
print("hex packed data:", binascii.hexlify(packed_data))
print("unpacked data", s.unpack(packed_data))
# @:原生顺序
# =:原生标准
# <:小端
# >:大端
# !:网络顺序
'''
original values: (1, b'ab', 2.7)
********************
Format string: @ I 2s f for native, native
uses: 12 bytes
hex packed data: b'0100000061620000cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: = I 2s f for native, standard
uses: 10 bytes
hex packed data: b'010000006162cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: < I 2s f for little-endian
uses: 10 bytes
hex packed data: b'010000006162cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: > I 2s f for big-endian
uses: 10 bytes
hex packed data: b'000000016162402ccccd'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: ! I 2s f for network
uses: 10 bytes
hex packed data: b'000000016162402ccccd'
unpacked data (1, b'ab', 2.700000047683716)
'''
缓冲区
import struct
'''
通常在强调性能的情况下,或者向扩展模块传入、传出数据时,才会处理二进制打包数据。
通过避免为每个打包结构分配一个新缓冲区所带来的开销,这些情况可以得到优化。
pack_into和unpack_from方法支持直接写入预分配的缓冲区
'''
import binascii
import ctypes
import array
s = struct.Struct("I 2s f")
values = (1, "ab".encode("utf-8"), 2.7)
print("original:", values)
print("---------------")
print("ctypes string buffer")
# 创建一个string缓存,大小为s.size
b = ctypes.create_string_buffer(s.size)
print("before:", b.raw, binascii.hexlify(b.raw))
# s.pack表示打包,s.pack_into表示打包到什么地方,至于第二个参数0表示偏移量,表示从头开始
s.pack_into(b, 0, *values)
print("after:", b.raw, binascii.hexlify(b.raw))
# s.unpack表示解包,s.unpack_from表示从什么地方解包,参数0表示偏移量,表示从头开始
print("unpacked:", s.unpack_from(b, 0))
print("---------------")
print("array")
a = array.array("b", b"\0"*s.size)
print("before:", a, binascii.hexlify(a))
s.pack_into(a, 0, *values)
print("after:", binascii.hexlify(a))
print("unpacked:", s.unpack_from(a, 0))
'''
original: (1, b'ab', 2.7)
---------------
ctypes string buffer
before: b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'000000000000000000000000'
after: b'\x01\x00\x00\x00ab\x00\x00\xcd\xcc,@' b'0100000061620000cdcc2c40'
unpacked: (1, b'ab', 2.700000047683716)
---------------
array
before: array('b', [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) b'000000000000000000000000'
after: b'0100000061620000cdcc2c40'
unpacked: (1, b'ab', 2.700000047683716)
'''
struct:二进制数据结构的打包与解包的更多相关文章
- Python3标准库:struct二进制数据结构
1. struct二进制数据结构 struct模块包括一些函数,这些函数可以完成字节串与原生Python数据类型(如数字和字符串)之间的转换. 1.1 函数与Struct类 struct提供了一组处理 ...
- Lua学习教程之 可变參数数据打包与解包
利用table的pack与unpack进行数据打包与解包.測试代码例如以下: print("Test table.pack()----------------"); functio ...
- lambda表达式,filter,map,reduce,curry,打包与解包和
当然是函数式那一套黑魔法啦,且听我细细道来. lambda表达式 也就是匿名函数. 用法:lambda 参数列表 : 返回值 例: +1函数 f=lambda x:x+1 max函数(条件语句的写法如 ...
- MPI 打包与解包函数 MPI_Pack(),MPI_Unpack()
▶ MPI 中与数据打包传输有关的几个函数 ● 函数 MPI_Pack() 与 MPI_Unpack() 的原型 MPI_METHOD MPI_Pack( _In_opt_ const void* i ...
- web socket RFC6455 frame 打包、解包
#ifndef __APP_WEBSOCKET_FRAME_H__ #define __APP_WEBSOCKET_FRAME_H__ #include "memory.hpp" ...
- dpkg打包与解包
1.打包 dpkg -b 2.解包 2.1 dpkg -X 解出包内容 2.2 dpkg -e 输出包控制信息
- CentOS7 tar打包工具 打包,解包,打包压缩,打包解压缩
tar命令 選項與參數: -c :建立打包檔案,可搭配 -v 來察看過程中被打包的檔名(filename) -t :察看打包檔案的內容含有哪些檔名,重點在察看『檔名』就是了: -x :解打包或解壓縮的 ...
- SummerVocation_Learning--java的自动打包与解包
Auto Boxing: 自动将基础类型转换成对象(JDK1.5之后支持) Auto UnBoxing:自动将对象转换成基础类型 如 Map中的put方法,如果要传入键值对<a,1>,&l ...
- Linux下文件打包与解包
打包(.tar): tar -cvf Pro.tar /home/lin/Pro #将/home/lin/Pro文件夹下的所有文件打包成Pro.tar 打解包(.tar.gz) tar -cv ...
随机推荐
- BeanUtils.getProperty性能分析
接上文Java各种反射性能对比 BeanUtils.getProperty的原理其实以下方法类似,但稍有不同 //代码片段4.1 PropertyDescriptor descripto ...
- C语言JS引擎
基础知识 SpiderMonkey 简介 和其他的 JavaScript 引擎一样,SpiderMonkey 不直接提供像 DOM 这样的对象,而是提供解析,执行 JavaSccript 代码,垃圾回 ...
- win系统常用命令
windows常用命令 net user 用户名 密码 /add (建立用户) net localgroup administrators 用户名 /add (将用户加到管理员,使其拥有管理权限) n ...
- 【VS开发】CListCtrl控件使用方法总结
CListCtrl控件使用方法总结 今天第一次用CListCtrl控件,遇到不少问题,查了许多资料,现将用到的一些东西总结如下: 以下未经说明,listctrl默认view 风格为report 相关类 ...
- prometheus 监控的目标 - nginx - apache
1.jvm类型 8563的grafanadashboard: gc时间,使用的现场,加载的类数 2.apache , nginx 用户连接状态,waiting数量 (使用nginx_status) c ...
- ubuntu 设置静态ip,但显示scope global secondary ens33
设置静态ip 修改 /etc/network/interfaces 文件 # The loopback network interface auto lo iface lo inet loopback ...
- Synchronized与Lock的区别与应用场景
转载. https://blog.csdn.net/fly910905/article/details/79765381 同步代码块,同步方法,或者是用java提供的锁机制,我们可以实现对共享资源变量 ...
- Android Application的Gradle说明
//引入插件 apply plugin: 'com.android.application' android { compileSdkVersion 29 buildToolsVersion &quo ...
- Linux系列之putty远程登录
在工作中,我们通常都是通过远程操作Linux服务器的,因此必须熟悉一些远程登录的软件,在此使用的是putty,在Windows上安装putty软件,通过该软件访问Linux主机. 1.远程登录步骤 1 ...
- strCmd.Format("delete FROM userTable where name = '%s'", name);
string.Format("select * from 数据库表 where 用户名='%s' and 密码='%s' ",m_1,m_2); 把[m_1]和[m_2]的值按照[ ...