Hadoop_26_MapReduce_Reduce端使用GroupingComparator求同一订单中最大金额的订单
1. 自定义GroupingComparator
1.1.需求:有如下订单
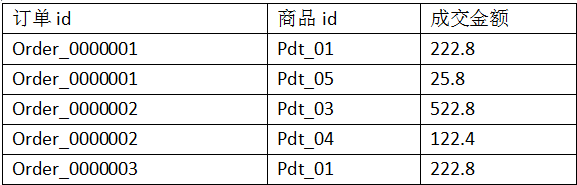
现在需要求出每一个订单中成交金额最大的一笔交易
1.2.分析:
1、利用“订单id和成交金额”Bean作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,
发送到reduce
2、在reduce端利用GroupingComparator将订单id相同的kv聚合成组,然后取第一个即是最大值
定义订单信息bean,实现CompareTo()方法用于排序
package cn.bigdata.hdfs.secondarySort; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
* 订单信息bean,实现hadoop的序列化机制
*/
public class OrderBean implements WritableComparable<OrderBean>{ private Text itemid;
private DoubleWritable amount; public OrderBean() {
} public OrderBean(Text itemid, DoubleWritable amount) {
set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid;
this.amount = amount; } public Text getItemid() {
return itemid;
} public DoubleWritable getAmount() {
return amount;
}
//1.模型必须实现Comparable<T>接口
/*2.Collections.sort(list);会自动调用compareTo,如果没有这句,list是不会排序的,也不会调用compareTo方法
3.如果是数组则用的是Arrays.sort(a)方法*/
//implements WritableComparable必须要实现的方法,用于比较排序
@Override
public int compareTo(OrderBean o) {
//根據ID排序
int cmp = this.itemid.compareTo(o.getItemid());
//id相同根据金额排序
if (cmp == 0) {
cmp = -this.amount.compareTo(o.getAmount());
}
return cmp;
} @Override
public void write(DataOutput out) throws IOException {
out.writeUTF(itemid.toString());
out.writeDouble(amount.get());
} @Override
public void readFields(DataInput in) throws IOException {
String readUTF = in.readUTF();
double readDouble = in.readDouble(); this.itemid = new Text(readUTF);
this.amount= new DoubleWritable(readDouble);
} @Override
public String toString() {
return itemid.toString() + "\t" + amount.get();
}
}
自定义Partitioner用于分区
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean bean, NullWritable value, int numReduceTasks) {
//相同id的订单bean,会发往相同的partition
//而且,产生的分区数,是会跟用户设置的reduce task数保持一致
return (bean.getItemid().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
自定义GroupingComparator,在调用Reduce时对数据分组
package cn.bigdata.hdfs.secondarySort;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; /**
* 用于控制shuffle过程中reduce端对kv对的聚合逻辑
* 利用reduce端的GroupingComparator来实现将一组bean看成相同的key
*/
public class ItemidGroupingComparator extends WritableComparator { //传入作为key的bean的class类型,以及制定需要让框架做反射获取实例对象
protected ItemidGroupingComparator() {
super(OrderBean.class, true);
} @Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b;
//将item_id相同的bean都视为相同,从而聚合为一组
//比较两个bean时,指定只比较bean中的orderid
return abean.getItemid().compareTo(bbean.getItemid());
}
}
编写mapreduce处理流程
/**
* Order_0000001,Pdt_01,222.8
* Order_0000001,Pdt_05,25.8
* Order_0000002,Pdt_05,325.8
* Order_0000002,Pdt_03,522.8
* Order_0000002,Pdt_04,122.4
* Order_0000003,Pdt_01,222.8
*/
public class SecondarySort { static class SecondarySortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{ OrderBean bean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] fields = StringUtils.split(line, ","); bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[2]))); context.write(bean, NullWritable.get());
}
} static class SecondarySortReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{ //到达reduce时,相同id的所有bean已经被看成一组,且金额最大的那个排在第一位
//在设置了groupingcomparator以后,这里收到的kv数据就是: <1001 87.6>,null <1001 76.5>,null ....
//此时,reduce方法中的参数key就是上述kv组中的第一个kv的key:<1001 87.6>
//要输出同一个item的所有订单中最大金额的那一个,就只要输出这个key
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(SecondarySort.class); job.setMapperClass(SecondarySortMapper.class);
job.setReducerClass(SecondarySortReducer.class); job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("F:/secondary"));
FileOutputFormat.setOutputPath(job, new Path("F:/secondaryOut")); //在此设置自定义的Groupingcomparator类
job.setGroupingComparatorClass(ItemidGroupingComparator.class);
//在此设置自定义的partitioner类
job.setPartitionerClass(ItemIdPartitioner.class);
//设置Reduce的数量
job.setNumReduceTasks(2);
job.waitForCompletion(true);
}
}
文件:
Order_0000001,Pdt_01,222.8
Order_0000001,Pdt_05,25.8
Order_0000002,Pdt_05,325.8
Order_0000002,Pdt_03,522.8
Order_0000002,Pdt_04,122.4
Order_0000003,Pdt_01,222.8
Hadoop_26_MapReduce_Reduce端使用GroupingComparator求同一订单中最大金额的订单的更多相关文章
- MapReduce案例:统计共同好友+订单表多表合并+求每个订单中最贵的商品
案例三: 统计共同好友 任务需求: 如下的文本, A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E ...
- 【MM系列】SAP MM模块-控制采购订单中某些项目的输出显示
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP MM模块-控制采购订单中某些 ...
- GPU端到端目标检测YOLOV3全过程(中)
GPU端到端目标检测YOLOV3全过程(中) 计算机视觉初级部分知识体系 总结了一下自己在计算机视觉初级部分的知识框架,整理如下. 个人所学并不全面( ...
- Luffy之结算订单页面(订单模型表的创建,订单的生成,以及订单详情展示等)
订单页面 在前面我们已经构建了,购物车的页面,接下来到了结算页面 1.首先,在购物车页面点击去结算按钮时,我们需要做如下动作 .前端发送生成订单的请求,点击标签内触发事件 create_order t ...
- Oracle EBS客户化程序中格式化金额
在Oracle EBS系统中,随处可见金额的显示格式,通常情况下都具有千分位符,同时有一定位数的精度,让我们先来看看一些现成的例子 上面这些列子中的金额都显示了千分位符,同时具备以2位小数,难道 ...
- Java订单号生成,唯一订单号(日均千万级别不重复)
Java订单号生成,唯一订单号 相信大家都可以搜索到很多的订单的生成方式,不懂的直接百度.. 1.订单号需要具备以下几个特点. 1.1 全站唯一性. 1.2 最好可读性. 1.3 随机性,不能重复,同 ...
- 微信公众号支付JSAPI网页,total_fee错误不正确,header重定向参数丢失,无法获取订单号和金额解决
微信公众号支付官方demo错误, 公众号支付只能用在微信里,也就是微信内部浏览器. 1.到WxPayHubHelper.php文件 JsApi_pub()类下createOauthUrlForCode ...
- js中进行金额计算
js中进行金额计算parseFloat 在js中进行以元为单位进行金额计算时 使用parseFloat会产生精度问题var price = 10.99;var quantity = 7;var n ...
- 为什么S/4HANA的销售订单创建会触发生产订单的创建
调用S/4HANA销售订单创建函数SD_SALES_DOCU_MAINTAIN创建一个销售订单时,会触发生产订单的创建. 销售订单的每个行项目对应一个独立的生产订单,SD_SALES_DOCU_MAI ...
随机推荐
- Linux系统管理----LVM逻辑卷和磁盘配额作业习题
1.为主机增加80G SCSI 接口硬盘 2.划分三个各20G的主分区 [root@localhost chen]# fdisk /dev/sdb 命令(输入 m 获取帮助):n Partition ...
- Hadoop入门学习笔记之一
http://hadoop.apache.org/docs/r1.2.1/api/index.html 适当的利用 null 在map中可以实现对文件的简单处理,如排序,和分集合输出等. 需要关心的内 ...
- [学习笔记] 在Eclips 中导出项目
有时候需要将自己完成的项目分享给别人,可以按如下步骤操作: 选择要导出的内容,设置导出的文件名. 然后点击,Finish 即可. 然后到d:\tmp 会看到文件:Hibernat_demo_001.z ...
- 【转贴】linux 终端报Message from syslogd
linux 终端报Message from syslogd xiao9873341760人评论8537人阅读2017-03-27 14:19:31 https://blog.51cto.com/xia ...
- [百家号]铁流:华为Hi1620发布 自研内核还是ARM改?
华为Hi1620发布 自研内核还是ARM改? https://baijiahao.baidu.com/s?id=1618735211251270521&wfr=spider&for=p ...
- [知乎]这可能是最全面的龙芯3A3000处理器评测
这可能是最全面的龙芯3A3000处理器评测 第一千零一个人 已关注 蓬岸 Dr.Quest . https://zhuanlan.zhihu.com/p/50716952 这里面链接很全. 立党 ...
- 【Python】【demo实验36】【基础实验】【求3*3矩阵的主对角线之和】
题目: 求一个3*3矩阵主对角线元素之和. 主对角线:从左上多右下的书归为主对角线 副对角线:从左下至右上的数归为副对角线. 我的源码: #!/usr/bin/python # encoding=ut ...
- Python+requests重定向和追踪
Python+requests重定向和追踪 一.什么是重定向 重定向就是网络请求被重新定个方向转到了其它位置 二.为什么要做重定向 网页重定向的情况一般有:网站调整(如网页目录结构变化).网页地址改变 ...
- 并发一:Java内存模型和Volatile
并发一:Java内存模型和Volatile 一.Java内存模型(JMM) Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和在内存中取出变量的底层细节,是围绕着 ...
- jquery【点击】导航按钮的来回切换
先获取元素的属性值,根据属性值进行判断,点击时对属性进行设置 <i class="layui-icon layui-icon-shrink-right" id="n ...