【转】GMM与K-means聚类效果实战
原地址:
GMM与K-means聚类效果实战
备注
分析软件:python
数据已经分享在百度云:客户年消费数据
密码:lehv
该份数据中包含客户id和客户6种商品的年消费额,共有440个样本
正文
一、数据探索和预处理
1.读取数据
import numpy as np
import pandas as pd
data = pd.read_excel(r'C:\Users\user\Desktop\客户年消费数据.xlsx')
2.缺失检查
print('各字段缺失情况:\n', data.isnull().sum())
输出:
id 0
Fresh 0
Milk 0
Grocery 0
Frozen 0
Detergents_Paper 0
Delicatessen 0
dtype: int64
观察得出:数据不存在缺失,且数据类型都为整数数值型
3.不同商品消费额分布
为了避免分布图右偏严重,剔除了大于95%分位数的极端值
import matplotlib.pyplot as plt
import seaborn as sns
六种商品年消费额分布图
fig = plt.figure(figsize=(16, 9))
for i, col in enumerate(list(data.columns)[1:]):
plt.subplot(321+i)
q95 = np.percentile(data[col], 95)
sns.distplot(data[data[col] < q95][col])
plt.show()
输出:

从图中看出:商品年消费额基本符合大于0的正态分布
4.极值和异常值处理
features = data[['Fresh', 'Milk', 'Grocery', 'Frozen', 'Detergents_Paper', 'Delicatessen']]
# 剔除极值或异常值
ids = []
for i in list(features.columns):
q1 = np.percentile(features[i], 25)
q3 = np.percentile(features[i], 75)
intervel = 1.6*(q3 - q1)/2
low = q1 - intervel
high = q3 + intervel
ids.extend(list(features[(features[i] <= low) |
(features[i] >= high)].index))
ids = list(set(ids))
features = features.drop(ids)
二、无监督学习-降维和聚类分析
1.整体思路
数据中没有没有明显的目标变量,因此只能对客户的消费特征进行分析,也就是机器学习中所指的无监督方法。这里利用K-means和GMM(Gaussian Mixture Model)两种聚类算法,尝试对客户进行聚类分析,并对比两种算法的聚类结果差异。为了方便分析聚类效果,先用PCA算法降六个特征维度降低到两维。
2.聚类算法原理简述
K-means聚类
该算法利用数据点之间的欧式距离大小,将数据划分到不同的类别,欧式距离较短的点处于同一类。算法结果直接返回的是数据点所属的类别。
GMM
全称Gaussian Mixture Model,可以简单翻译为高斯混合模型,Gaussian指高斯分布(也就是正态分布)。该算法假设所有数据点来自多个参数不同的高斯分布,来自同一分布的数据点被划分为同一类。算法结果返回的是数据点属于不同类别的概率。
3.数据降至二维(PCA)
# 计算每一列的平均值
meandata = np.mean(features, axis=0)
# 均值归一化
features = features - meandata
# 求协方差矩阵
cov = np.cov(features.transpose())
# 求解特征值和特征向量
eigVals, eigVectors = np.linalg.eig(cov)
# 选择前两个特征向量
pca_mat = eigVectors[:, :2]
pca_data = np.dot(features , pca_mat)
pca_data = pd.DataFrame(pca_data, columns=['pca1', 'pca2'])
两个主成分的散点图
plt.subplot(111)
plt.scatter(pca_data['pca1'], pca_data['pca2'])
plt.xlabel('pca_1')
plt.ylabel('pca_2')
plt.show()
输出:

说明:图2.1中,横轴代表第一主成分,纵轴代表第二主成分
4.数据降维后信息保留百分比
print('前两个主成分包含的信息百分比:{:.2%}'.format(np.sum(eigVals[:2])/np.sum(eigVals)))
输出:
前两个主成分包含的信息百分比:92.39%
5.客户聚类
该步骤中,主要是对降维后的二维数据进行GMM和K-means聚类。聚类类别分别为2,3,4,5时,对比时两种算法下,点的的划分结果,并以散点图展现。
先定义make_ellipses函数,用于画出GMM算法中的高斯分布区域:
import matplotlib as mpl
定义make_ellipses函数,根据GMM算法输出的聚类类别,画出相应的高斯分布区域
def make_ellipses(gmm, ax, k):
for n in np.arange(k):
if gmm.covariance_type == 'full':
covariances = gmm.covariances_[n][:2, :2]
elif gmm.covariance_type == 'tied':
covariances = gmm.covariances_[:2, :2]
elif gmm.covariance_type == 'diag':
covariances = np.diag(gmm.covariances_[n][:2])
elif gmm.covariance_type == 'spherical':
covariances = np.eye(gmm.means_.shape[1]) * gmm.covariances_[n]
v, w = np.linalg.eigh(covariances)
u = w[0] / np.linalg.norm(w[0])
angle = np.arctan2(u[1], u[0])
angle = 180 * angle / np.pi # convert to degrees
v = 2. * np.sqrt(2.) * np.sqrt(v)
ell = mpl.patches.Ellipse(gmm.means_[n, :2], v[0], v[1],
180 + angle)
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.3)
ax.add_artist(ell)
再根据模型输出,画出聚类结果对比图:
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.metrics import silhouette_score
score_kmean = []
score_gmm = []
random_state = 87
n_cluster = np.arange(2, 5)
for i, k in zip([0, 2, 4, 6], n_cluster):
# K-means聚类
kmeans = KMeans(n_clusters=k, random_state=random_state)
cluster1 = kmeans.fit_predict(pca_data)
score_kmean.append(silhouette_score(pca_data, cluster1))
# gmm聚类
gmm = GaussianMixture(n_components=k, covariance_type='full', random_state=random_state)
cluster2 = gmm.fit(pca_data).predict(pca_data)
score_gmm.append(silhouette_score(pca_data, cluster2))
# 聚类效果图
plt.subplot(421+i)
plt.scatter(pca_data['pca1'], pca_data['pca2'], c=cluster1, cmap=plt.cm.Paired)
if i == 6:
plt.xlabel('K-means')
plt.subplot(421+i+1)
plt.scatter(pca_data['pca1'], pca_data['pca2'], c=cluster2, cmap=plt.cm.Paired)
make_ellipses(gmm, ax, k)
if i == 6:
plt.xlabel('GMM')
plt.show()
输出:

说明:聚类类别分别为2,3,4,5时,两种聚类算法结果对比(左边是K-means,右边是GMM);点的颜色相同代表被聚为同一类;右图中的透明椭圆区域,代表GMM算法估计出的隐藏高斯分布区域。
三、聚类效果分析
如何评判聚类结果呢?这里引入轮廓分析(Silhouette analysis),轮廓分析主要统计轮廓得分,该指标计算聚类类别与相邻类别之间的总体距离大小,从而判断聚类有效程度。
# 聚类类别从2到11,统计两种聚类模型的silhouette_score,分别保存在列表score_kmean 和score_gmm
score_kmean = []
score_gmm = []
random_state = 87
n_cluster = np.arange(2, 12)
for k in n_cluster:
# K-means聚类
kmeans = KMeans(n_clusters=k, random_state=random_state)
cluster1 = kmeans.fit_predict(pca_data)
score_kmean.append(silhouette_score(pca_data, cluster1))
# gmm聚类
gmm = GaussianMixture(n_components=k, covariance_type='spherical', random_state=random_state)
cluster2 = gmm.fit(pca_data).predict(pca_data)
score_gmm.append(silhouette_score(pca_data, cluster2))
得分变化对比图
sil_score = pd.DataFrame({'k': np.arange(2, 12),
'score_kmean': score_kmean,
'score_gmm': score_gmm})
K-means和GMM得分对比
plt.figure(figsize=(10, 6))
plt.bar(sil_score['k']-0.15, sil_score['score_kmean'], width=0.3,
facecolor='blue', label='Kmeans_score')
plt.bar(sil_score['k']+0.15, sil_score['score_gmm'], width=0.3,
facecolor='green', label='GMM_score')
plt.xticks(np.arange(2, 12))
plt.legend(fontsize=16)
plt.ylabel('silhouette_score', fontsize=16)
plt.xlabel('k')
plt.show()
输出:
四、小结和建议
经过本次探索过程,总结以下几点:
1.图2.2,从点的划分情况来看,GMM和K-means的聚类结果具有较强的相似性;
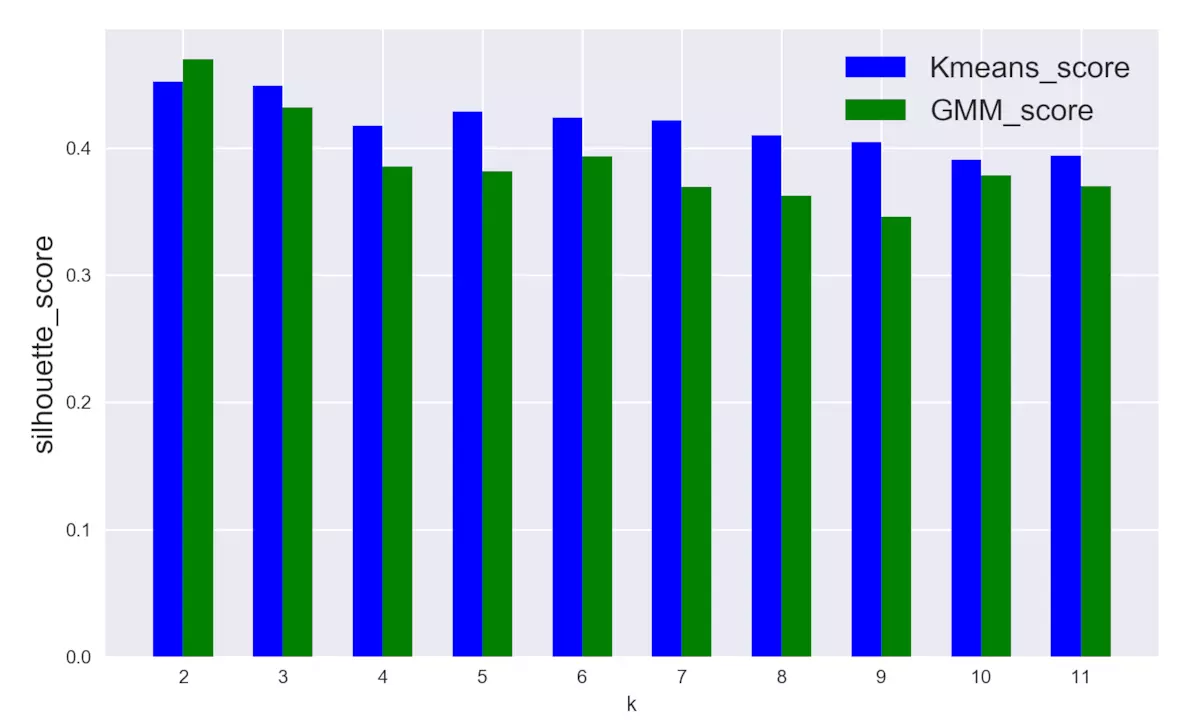
2.图3.1, 从对比的角度,以silhouette_score为评判指标,整体上GMM的模型得分略低于K-means;
3.图3.1,聚类类别增多时,K-means模型的得分比较稳定,几乎没有明显差别,相比之下,GMM模型的得分开始下降幅度较大,但之后也趋于稳定。
4.根据得分情况,最佳聚类类别应该为2或3,此时K-means和GMM模型的表现都比较好。
5.最优k值对应的聚类类别可以作为新的数据特征,用于其它分析。
个人建议:若不考虑运算速度,当两种算法聚类得分差异很小时,推荐使用GMM算法,因为GMM能输出数据点属于某一类别的概率,因此输出的信息丰富程度大大高于K-means算法。
以上为转载内容。
在照葫芦画瓢的时候,遇到一点问题,主要是网络导致的python库文件下载速度慢和一点程序上的小问题。把两个下载时速度慢的库sklearn和xlrd放在github上了,整个python文件也在。
Github-GMM
sklearn.mixture.GaussianMixture 官方操作手册
从手册上查到
gmm.means_ //可以查看均值
gmm.covariances_ //可以查看均方差
【转】GMM与K-means聚类效果实战的更多相关文章
- K均值聚类的失效性分析
K均值聚类是一种应用广泛的聚类技术,特别是它不依赖于任何对数据所做的假设,比如说,给定一个数据集合及对应的类数目,就可以运用K均值方法,通过最小化均方误差,来进行聚类分析. 因此,K均值实际上是一个最 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
随机推荐
- tarjan等
有向图注意v在栈中时,才用dfn更新low.无向图不用判断这个. SCC和边双,都是在返回时判断low==dfn. 点双就是找割点,low(v)>=dfn(u)时,把tarjan(v)过程中放入 ...
- 避免Double数据显示为科学记数
显示现象 数据类型 实体类中为 private Double tradeAmount; Oracle数据库中为 NUMBER(19,4) 解决方式 第一种解决方式 - 无效 将Double转 ...
- mousemove([[data],fn])
mousemove([[data],fn]) 概述 当鼠标指针在指定的元素中移动时,就会发生 mousemove 事件.大理石构件来图加工 mousemove事件处理函数会被传递一个变量——事件对象, ...
- (转)实验文档2:实战交付一套dubbo微服务到kubernetes集群
基础架构 主机名 角色 ip HDSS7-11.host.com k8s代理节点1,zk1 10.4.7.11 HDSS7-12.host.com k8s代理节点2,zk2 10.4.7.12 HDS ...
- 绕过本机DNS缓存
--转载注明来源 http://www.cnblogs.com/sysnap/ 0x1 背景 往HOST文件添加127.0.0.1 www.baidu.com, 可以劫持百度的域名.病毒经常篡改HO ...
- layer快速点击会触发多次回调
场景还原 测试同学反馈点击了一次操作,为什么会有两条操作记录? 我:???? 排查思路 查看日志,看一下是不是发了两次请求,果不其然啊: 并发了,同一时间发送了两次请求,出现了脏写. 原因 系统的co ...
- [go]日志库小例子
输出日志 //输出日志到console msg := fmt.Sprintf(format, args...) //format里的坑 args解出的数据相匹配 fmt.Fprintf(os.Stdo ...
- 【网站部署】flask
记录下常用的命令: nohup gunicorn --workers=2 --timeout=400 app:app &ps -ax scp -p ./***.h5 user@**.**.** ...
- nginx虚拟主机添加
1. 进入 /usr/local/nginx/conf/vhost 目录, 创建虚拟主机配置文件 wbs.test.com.conf ({域名}.conf). 2.打开配置文件, 添加服务如下: lo ...
- Spring Aop(二)——基于Aspectj注解的Spring Aop简单实现
转发地址:https://www.iteye.com/blog/elim-2394762 2 基于Aspectj注解的Spring Aop简单实现 Spring Aop是基于Aop框架Aspectj实 ...