MR1和MR2的工作原理
MapReduce1
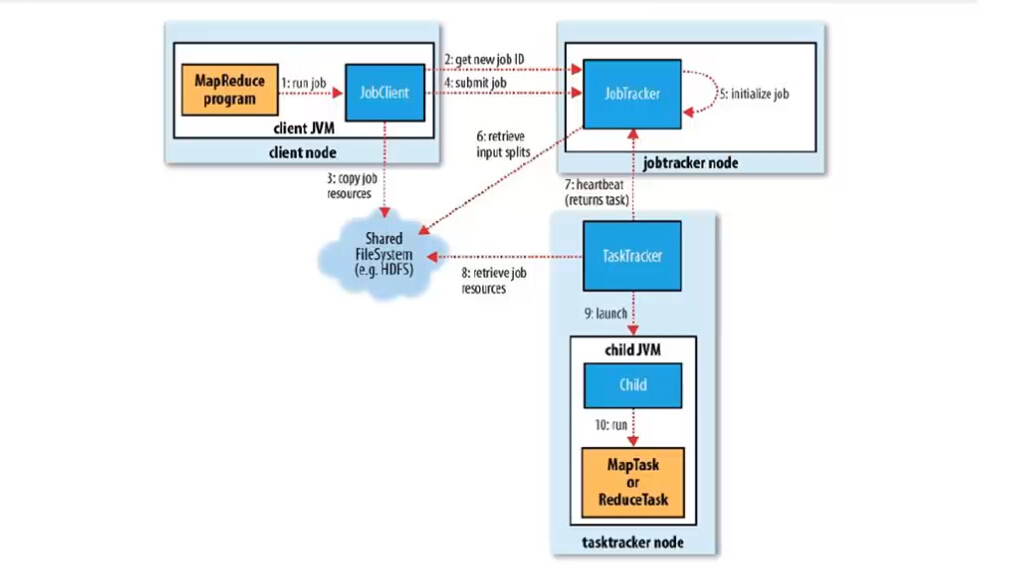
分为6个步骤:
1、作业的提交
1)、客户端向jobtracker请求一个新的作业ID(通过JobTracker的getNewJobId()方法获取,见第2步
2)、计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个以ID命名的jobtracker的文件系统中(HDFS),见第3步
3)、告知jobtracker作业准备执行,见第4步
2、作业的初始化
4)、JobTracker收到对其submitJob()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,见第5步
5)、作业调度器首先从共享文件系统HDFS中获取客户端已经计算好的输入分片,见第6步
6)、为每个分片创建一个map任务和reduce任务,以及作业创建和作业清理的任务。
3、任务的分配
7)、tasktracker定期向jobtracker发送“心跳”,表明自己还活着。见第7步
8)、jobtracker为tasktracker分配任务,对于map任务,jobtracker会考虑tasktracker的网络位置,选取一个距离其输入分片文件最近的tasktracker,对于reduce任务,jobtracker会从reduce任务列表中选取下一个来执行。
4、任务的执行
9)、从HDFS中把作业的jar文件复制到tasktracker所在的文件系统,实现jar文件本地化,同时,tasktracker将应用程序所需的全部文件从分布式缓存中复制到本地磁盘,见第8步,并且tasktracker为任务新建一个本地工作目录,并把jar文件的内容解压到这个文件夹下,然后新建一个taskRunner实例运行该任务
10)、TaskRunner启动一个新的JVM(见第9步)来运行每个任务(见第10步)
5、进度和状态的更新
11)、任务运行期间,对其进度progress保持追踪。对map进度是已经处理输入所占的比例。对于reduce任务,分三部分,与shuffle的三个阶段相对应。
Shuffle是系统执行排序的过程。是mapreduce的心脏。

对于map端而言:每个map任务都有一个环形内存缓冲区,默认是0.8,当缓冲区达到阈值时便开始把内容溢出spill到磁盘,在写入磁盘之前,线程会根据数据最终要传的reducer把数据划分成相应的分区,每个分区中,按键值进行内排序,如果有combine(使结果更紧凑),会在combine完成之后再写入磁盘。
对于reducer端而言,map的输出文件位于tasktracker的本地磁盘,每个map任务完成的时间可能不同,只要有一个完成,就会复制其输出(这就是复制阶段),然后把map的输出进行merge合并,然后直接把数据输入到reduce函数,完成输出。
6、作业的完成
YARN(MapReduce2)
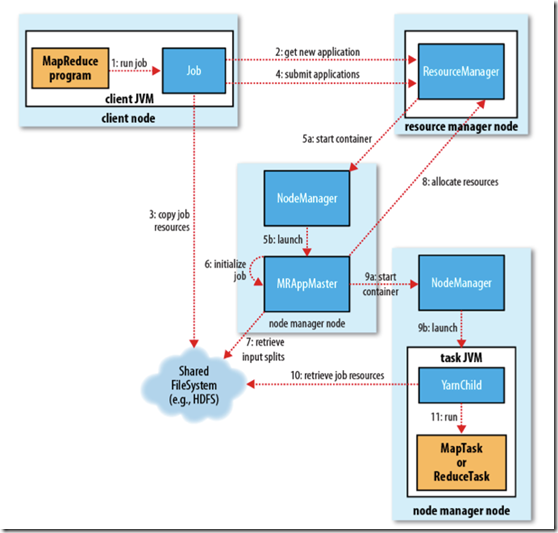
分6步执行:
1、作业提交
1)、客户端向ResourceManager请求一个新的作业ID,ResourceManager收到后,回应一个ApplicationID,见第2步
2)、计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个(HDFS),见第3步
3)、告知ResourceManager作业准备执行,并且调用submitApplication()提交作业,见第4步
2、作业初始化
4)、ResourceManager收到对其submitApplication()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,然后为该其分配一个contain容器,见第5步
5)、并与对应的NodeManager通信见第5a步,要求它在Contain中启动ApplicationMaster见第5b步
6)、ApplicationMaster启动后,会对作业进行初始化,并保持作业的追踪见第6步.
7)、ApplicationMaster从HDFS中共享资源,,接受客户端计算的输入分片为每个分片。见第7步
3、任务分配
8)、ApplicationMaster想ResourceManager注册,这样就可以直接通过RM查看应用的运行状态,然后为所有的map和reduce任务获取资源,见第8步
4、任务执行
9)、ApplicationMaster申请到资源后,与NodeManager进行交互,要求它在Contain容器中启动执行任务。见第9a、9b步
5、进度和状态的更新
10)、各个任务通过RPC协议umbilical接口向ApplicationMaster汇报自己的状态和进度,方便ApplicationMaster随时掌握各个任务的运行状态。用户也可以向ApplicationMaster查询运行状态。
6、作业完成
11)、应用完成后,ApplicationMaster向ResourceManager注销并关闭自己。
MR1和MR2的工作原理的更多相关文章
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
- Servlet的生命周期及工作原理
Servlet生命周期分为三个阶段: 1,初始化阶段 调用init()方法 2,响应客户请求阶段 调用service()方法 3,终止阶段 调用destroy()方法 Servlet初始化阶段: 在 ...
- 代码管理工具 --- git的学习笔记二《git的工作原理》
通过几个问题来学习代码管理工具之git 一.git是什么?为什么要用它?使用它的好处?它与svn的区别,在Mac上,比较好用的git图形界面客户端有 git 是分布式的代码管理工具,使用它是因为,它便 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 浏览器内部工作原理--作者:Tali Garsiel
本篇内容为转载,主要用于个人学习使用,作者:Tali Garsiel 一.介绍 浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工作原理,我们将看到,从你在地址栏输入google.com到你看到 ...
随机推荐
- python读取txt文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8e in position 8: illegal multibyte sequence
python读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8e in position 8: illegal multibyte ...
- python 获取安装包apk, ipa 信息
# -*- coding:utf-8 -*- import re import os import zipfile from biplist import * from androguard.core ...
- Python学习 第一天(一)初始python
1.python的前世今生 想要充分的了解一个人,无外乎首先充分了解他的过去和现在:咱们学习语言也是一样的套路 1.1 python的历史 Python(英国发音:/ˈpaɪθən/ 美国发音:/ˈp ...
- 关于注解-Hebernate与JPA(java persistence api)
The JPA spec. defines the JPA annotation in the javax.persistence package. Hibernate not only implem ...
- Vue-cli + express 构建的SPA Blog(采用前后端分离方案)
为什么学习并使用Vue 1.发展趋势 最近这几年的前端圈子,由于戏台一般精彩纷呈,从 MVC 到 MVVM,你刚唱罢我登场. backbone,AngularJS 已成昨日黄花,reactjs 如日中 ...
- 4、路由事件 RoutedEvent
路由事件的类型:具体参考https://www.cnblogs.com/jellochen/p/3475754.html Tunnel隧道方式:路由事件使用隧道策略,以便事件实例通过树向下路由(从根到 ...
- H5 设计尺寸
750*1218 微信下 兼容 7plus 内容高度 居中 1000px 内 750*1448 微信下 兼容 iphoneX 微信导航栏高度 64px 64px = 导航栏44+状态栏20 但是现在 ...
- POJ1990--POJ 1990 MooFest(树状数组)
Time Limit: 1000MSMemory Limit: 30000K Total Submissions: 8141Accepted: 3674 Description Every year, ...
- 在Spring Boot快捷地读取文件内容的若干种方式
引言: 在Spring Boot构建的项目中,在某些情况下,需要自行去读取项目中的某些文件内容,那该如何以一种轻快简单的方式读取文件内容呢? 基于ApplicationContext读取 在Spri ...
- LeetCode---Sort && Segment Tree && Greedy
307. Range Sum Query - Mutable 思路:利用线段树,注意数据结构的设计以及建树过程利用线段树,注意数据结构的设计以及建树过程 public class NumArray { ...