spark学习之Lambda架构日志分析流水线
单机运行
一、环境准备
Flume 1.6.0
Hadoop 2.6.0
Spark 1.6.0
Java version 1.8.0_73
Kafka 2.11-0.9.0.1
zookeeper 3.4.6
二、配置
spark和hadoop配置见()
kafka和zookeeper使用默认配置
1、kafka配置
启动
bin/kafka-server-start.sh config/server.properties
创建一个test的topic
bin/kafka-topics.sh --create --zookeeper vm: --replication-factor --partitions --topic test
2、flume配置文件,新建一个dh.conf文件,配置如下
其中发送的内容为apache-tomcat-8.0.32的访问日志
#define c1
agent1.channels.c1.type = memory
agent1.channels.c1.capacity =
agent1.channels.c1.transactionCapacity =
#define c1 end #define c2
agent1.channels.c2.type = memory
agent1.channels.c2.capacity =
agent1.channels.c2.transactionCapacity =
#define c2 end #define source monitor a file
agent1.sources.avro-s.type = exec
agent1.sources.avro-s.command = tail -f -n+ /usr/local/hong/apache-tomcat-8.0./logs/localhost_access_log.--.txt
agent1.sources.avro-s.channels = c1 c2
agent1.sources.avro-s.threads = # send to hadoop
agent1.sinks.log-hdfs.channel = c1
agent1.sinks.log-hdfs.type = hdfs
agent1.sinks.log-hdfs.hdfs.path = hdfs://vm:9000/flume
agent1.sinks.log-hdfs.hdfs.writeFormat = Text
agent1.sinks.log-hdfs.hdfs.fileType = DataStream
agent1.sinks.log-hdfs.hdfs.rollInterval =
agent1.sinks.log-hdfs.hdfs.rollSize =
agent1.sinks.log-hdfs.hdfs.rollCount =
agent1.sinks.log-hdfs.hdfs.batchSize =
agent1.sinks.log-hdfs.hdfs.txnEventMax =
agent1.sinks.log-hdfs.hdfs.callTimeout =
agent1.sinks.log-hdfs.hdfs.appendTimeout = #send to kafaka
agent1.sinks.log-sink2.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.log-sink2.topic = test
agent1.sinks.log-sink2.brokerList = vm:
agent1.sinks.log-sink2.requiredAcks =
agent1.sinks.log-sink2.batchSize =
agent1.sinks.log-sink2.channel = c2 # Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = c1 c2
agent1.sources = avro-s
agent1.sinks = log-hdfs log-sink2
三、测试flume发送
1、启动hdfs
./start-dfs.sh
2、启动zookeeper
./zkServer.sh start
3、kafka的见上面
4、启动flume
flume-ng agent -c conf -f dh.conf -n agent1 -Dflume.root.logger=INFO,console
四、测试效果
运行kafka的consumer查看
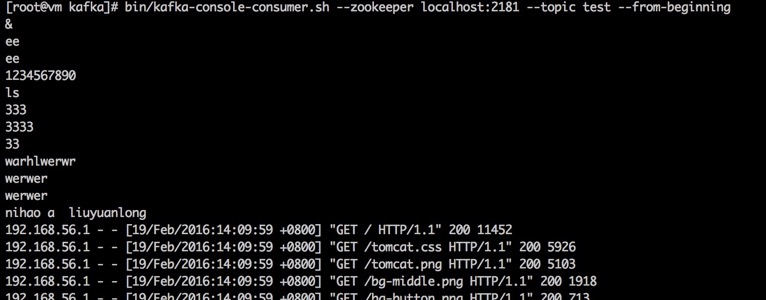
bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning
可以看到如下内容说明kafka和flume的配置成功
访问hdfs查看如果/flume可以下载文件进行查看验证hdfs发送是否成功
spark学习之Lambda架构日志分析流水线的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- Hadoop学习笔记—20.网站日志分析项目案例
1.1 项目来源 本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖.回帖,如图1所示. 图1 项目来源网站-技术学习论坛 本次实践的目的就在于 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- 【Spark】通过Spark实现点击流日志分析
文章目录 数据大致内容及格式 统计PV(PageViews) 统计UV(Unique Visitor) 求取TopN 数据大致内容及格式 194.237.142.21 - - [18/Sep/2013 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- 架构之ELK日志分析系统
ELK多种架构及优劣 既然要谈ELK在大数据运维系统中的应用,那么ELK架构就不得不谈.本章节引出四种笔者曾经用过的ELK架构,并讨论各种架构所适合的场景和优劣供大家参考. 先大致介绍ELK组件.EL ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- redis4. dict字典
基础数据结构: (注意dict是字典,dict->type是相关函数指针, dict->type->keyDup是执行该方法) 具体调用链路: 渐进式rehash: 新增/删除时: ...
- JVM菜鸟进阶高手之路一[z]
https://mp.weixin.qq.com/s/qD1LFmsOiqZHD8iZX97OfA? 问题现象 代码如下,使用 ParNew + Serial Old 回收器组合与使用 ParNew ...
- iOS 隐藏导航栏后,UITableView向下偏移状态栏高度
if (@available(iOS 11.0, *)) { self.mainTableView.contentInsetAdjustmentBehavior = UIScrollViewConte ...
- Mac 配置vscode调试PHP
Mac系统版本:MacOS Mojave 10.14.5 vscode:1.36.0 MacOS Mojave 10.14.5 系统自带 PHP 7.1.23 1.开启php sudo vim / ...
- Scala安装配置和使用
- System.arraycopy() 数组复制方法
一.深度复制和浅度复制的区别 Java数组的复制操作可以分为深度复制和浅度复制,简单来说深度复制,可以将对象的值和对象的内容复制;浅复制是指对对象引用的复制. 二.System.arraycop ...
- SpringBoot: 5.访问静态资源(转)
springboot默认从项目的resources里面的static目录下或者webapp目录下访问静态资源 方式一:在resources下新建static文件(文件名必须是static) 在浏览器中 ...
- vue中如何使用event对象
原文地址 一.event 对象 (一)事件的 event 对象 你说你是搞前端的,那么你肯定就知道事件,知道事件,你就肯定知道 event 对象吧?各种的库.框架多少都有针对 event 对象的处理. ...
- v-for产生的列表,实现active的切换
v-for生成序列 <ul> <li v-for="(info,index) in list" :key="info.id" @click=& ...
- oracle+mybatis批量插入踩坑记
最近在项目中需要使用oracle+mybatis批量插入数据,因为自增主键,遇到问题,现记录如下: 一.常用的两种sql写法报错 1.insert ... values ... <insert ...