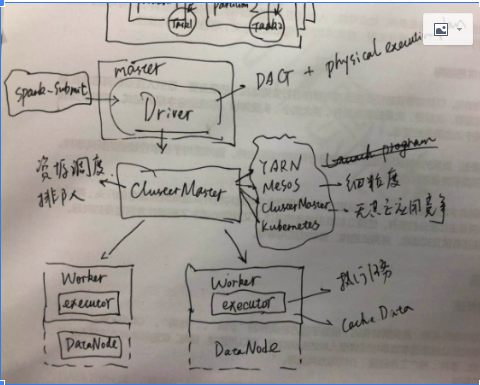
什么是Spark(四)集群
Driver,主要的职责是生成DAG以及生成物理执行计划(Physical Execution Plan);Application,Job以及Stage都是在这个组建中生成的;
ClusterMaster,包括五类:
1)Apache YARN,Hadoop原生资源调度框架
2)Apache Mesos,有粗粒度(coarse-grained,fine-grained),粗粒度资源一旦分配就不再改变;细粒度则是根据应用对于资源的需要动态分配;前者执行速度回比较快,但是有资源滥用的可能;后者执行速度可能会受影响,但是资源共享可以达到最大;
3)Amazon EC2
4)Stand alone Cluster Manager,Spark自带的Cluster Manager,同样提供coarse-grained和fine-grained对于资源的管理。
5)Kubernetes
Executor,主要的职责是执行任务以及缓存数据;在Spark定义的对象中Task就是在这个点上面执行的。
在描述Spark部署的时候,要分清楚角色和组件;master,worker是节点的角色,对应的driver以及executor是组件。
对于Cluster的几点建议:
1)如果是单独spark来使用所有的共享资源;stand alone cluster manager就可以;
2)如果是多个应用来共享资源(比如Hive),那么采用YARN或者是Mesos;
3)如果对于资源比较敏感,请求多,资源相对少,采用Mesos(的细粒度模式);
4)Executor所在的Worker节点最好和Hdfs部署一致;这样取用数据方便,可以有效减少shuffle。
什么是Spark(四)集群的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 04、Spark Standalone集群搭建
04.Spark Standalone集群搭建 4.1 集群概述 独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点.master节点 ...
- 4. Spark在集群上运行
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第四部分是讲的是Spark在集群上运行的知识点. 一.Spark应用组件介绍 二.Spark在集群运行过程 三.Spark配置 ...
随机推荐
- table 转实体
public class Table2Entity<T> where T : class,new() { public static List<T> GetEntitys(Da ...
- 常用的SpringMVC注解
1.@RequestMapping() 访问链接编写: 例如: (1).请求方法: 访问链接: (2).请求参数和请求头: 访问链接: 2.@PathVariable 例如: 访问链接: 结果显示: ...
- day32 Python与金融量化分析(二)
第一部分:金融与量化投资 股票: 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东. 股票的面值与市值 面值表示票面金额 市值表示市场价值 上市/IPO: 企业通过证券交易所公开向社 ...
- ansible入门六(roles)
一.什么场景下会用roles? 假如我们现在有3个被管理主机,第一个要配置成httpd,第二个要配置成php服务器,第三个要配置成MySQL服务器.我们如何来定义playbook? 第一个play用到 ...
- 关于js中的原型链的理解
我们知道无论什么时候只要创建了一个函数,就会为该函数创建一个prototype属性,这个属性指向函数的原型对象,默认情况下所有原型对象都会自动获得一个constructor(构造函数)属性,这个属性包 ...
- Java开发微信公众号模板消息【同步|异步】
第一步:申请模板消息功能并添加模板 在微信公众平台找到你需要的模板,并添加上即可: 第二步:添加功能模块后开始开发 功能中使用的类及代码: 发送数据主实体类: Template.java packag ...
- 012PHP基础知识——运算符(五)
<?php /** * 运算符的短路: * && 逻辑与 || 逻辑或 存在短路: */ /* $a = 1; $a==1 ||$c=100; //逻辑或:第一个表达式返回tru ...
- Prism 4 文档 ---第7章 组成用户界面
一个应用程序的用户界面(UI)可以通用以下几种模式之一来构建: 窗体所需要所有的控件都包含在一个单独的XAML文件中,在设计时组合这个窗体. 窗体的逻辑区域被分割到单独的部分中,通常指哟过户控件.这些 ...
- 使用Unity创建塔防游戏(Part3)—— 项目总结
之前我们完成了使用Unity创建塔防游戏这个小项目,在这篇文章里,我们对项目中学习到的知识进行一次总结. Part1的地址:http://www.cnblogs.com/lcxBlog/p/60759 ...
- Jquery validation自定义验证
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...