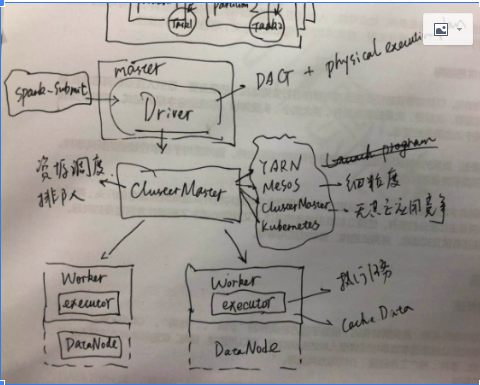
什么是Spark(四)集群
Driver,主要的职责是生成DAG以及生成物理执行计划(Physical Execution Plan);Application,Job以及Stage都是在这个组建中生成的;
ClusterMaster,包括五类:
1)Apache YARN,Hadoop原生资源调度框架
2)Apache Mesos,有粗粒度(coarse-grained,fine-grained),粗粒度资源一旦分配就不再改变;细粒度则是根据应用对于资源的需要动态分配;前者执行速度回比较快,但是有资源滥用的可能;后者执行速度可能会受影响,但是资源共享可以达到最大;
3)Amazon EC2
4)Stand alone Cluster Manager,Spark自带的Cluster Manager,同样提供coarse-grained和fine-grained对于资源的管理。
5)Kubernetes
Executor,主要的职责是执行任务以及缓存数据;在Spark定义的对象中Task就是在这个点上面执行的。
在描述Spark部署的时候,要分清楚角色和组件;master,worker是节点的角色,对应的driver以及executor是组件。
对于Cluster的几点建议:
1)如果是单独spark来使用所有的共享资源;stand alone cluster manager就可以;
2)如果是多个应用来共享资源(比如Hive),那么采用YARN或者是Mesos;
3)如果对于资源比较敏感,请求多,资源相对少,采用Mesos(的细粒度模式);
4)Executor所在的Worker节点最好和Hdfs部署一致;这样取用数据方便,可以有效减少shuffle。
什么是Spark(四)集群的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 04、Spark Standalone集群搭建
04.Spark Standalone集群搭建 4.1 集群概述 独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点.master节点 ...
- 4. Spark在集群上运行
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第四部分是讲的是Spark在集群上运行的知识点. 一.Spark应用组件介绍 二.Spark在集群运行过程 三.Spark配置 ...
随机推荐
- python __new__和__init__
转载:http://www.cnblogs.com/tuzkee/p/3540293.html 1 2 3 4 5 6 7 8 class A(object): def __init__(se ...
- Android_布局属性大全
RelativeLayout 第一类:属性值为true可false android:layout_centerHrizontal 水平居中 android:layout_centerVe ...
- C++复习2.软件开发知识小节
高质量的软件开发 1.满足正确性,健壮性,可靠性,性能,易用性,清晰性,安全性,兼容性,扩展性,可移植性等等来评价软件的质量. 2.没有错误的程序世间难求,任何一个程序,无论他多么的小,总是存在着错误 ...
- PIVOT 和 UNPIVOT 命令的SQL Server版本
I:使用 PIVOT 和 UNPIVOT 命令的SQL Server版本要求 1.数据库的最低版本要求为 SQL Server 2005 或 更高 2.必须将数据库的兼容级别设置为 90 或 更高 3 ...
- Django-自定义分页组件
1.封装的分页代码: class PageInfo(object): def __init__(self,current_page,all_count,per_page,base_url,show_p ...
- Week11《java程序设计》作业总结
Week11<java程序设计>作业总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 答: 2. 书面作业 本次PTA作业题集多线程 1. 源代码 ...
- New Concept English three (24)
33 72 We often read in novels how a seemingly respectable person or family has some terrible secret ...
- 【PL/SQL编程】变量和常量
1. 变量格式 <变量名><数据类型>[(长度):=<初始值>]; v_countryname varchar2(50):='中国'; 2. 常量格式 <常量 ...
- VM遇到的问题参考
http://saturn.blog.51cto.com/184463/950731/
- ROS-I工业机器人培训课程资料 2017-06-30
美国ROS工业联盟于2017年6月6日至8日在德克萨斯州圣安东尼奥市的SwRI举办了ROS工业开发人员培训班.12位与会者代表了一系列不同的组织,包括Bastian Solutions,EWI,Joh ...