hadoop中OutputFormat 接口的设计与实现
OutputFormat 主要用于描述输出数据的格式,它能够将用户提供的 key/value 对写入特定格式的文件中。 本文将介绍 Hadoop 如何设计 OutputFormat 接口 , 以及一些常用的OutputFormat 实现。
1.旧版 API 的 OutputFormat 解析
如图所示, 在旧版 API 中,OutputFormat 是一个接口,它包含两个方法:
RecordWriter<K, V> getRecordWriter(FileSystem ignored, JobConf job,
String name, Progressable progress)
throws IOException;
void checkOutputSpecs(FileSystem ignored, JobConf job) throws IOException;
checkOutputSpecs 方法一般在用户作业被提交到 JobTracker 之前, 由 JobClient 自动调用,以检查输出目录是否合法。
getRecordWriter 方法返回一个 RecordWriter 类对象。 该类中的方法 write 接收一个key/value 对, 并将之写入文件。在 Task 执行过程中, MapReduce 框架会将 map() 或者reduce() 函数产生的结果传入 write 方法, 主要代码(经过简化)如下。假设用户编写的 map() 函数如下:
public void map(Text key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
// 根据当前 key/value 产生新的输出 <newKey, newValue>, 并输出
……
output.collect(newKey, newValue);
}
则函数 output.collect(newKey, newValue) 内部执行代码如下:
RecordWriter<K, V> out = job.getOutputFormat().getRecordWriter(...);
out.write(newKey, newValue);
Hadoop 自带了很多OutputFormat 实现, 它们与 InputFormat 实现相对应,具体如图所示。所有基于文件的 OutputFormat 实现的基类为 FileOutputFormat, 并由此派生出一些基于文本文件格式、 二进制文件格式的或者多输出的实现。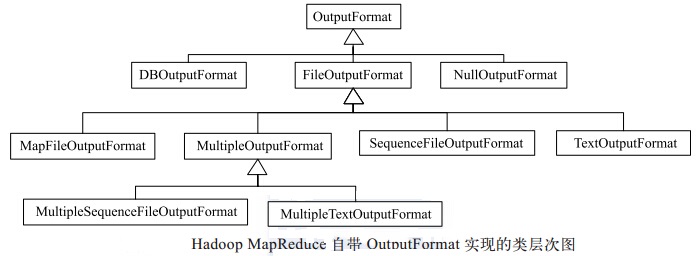
为了深入分析OutputFormat的实现方法,选取比较有代表性的FileOutputFormat类进行分析。同介绍 InputFormat 实现的思路一样,我们先介绍基类FileOutputFormat,再介绍其派生类 TextOutputFormat。基类 FileOutputFormat 需要提供所有基于文件的 OutputFormat 实现的公共功能,总结起来,主要有以下两个:
(1) 实现 checkOutputSpecs 接口
该接口 在作业运行之前被调用, 默认功能是检查用户配置的输出目 录是否存在,如果存在则抛出异常,以防止之前的数据被覆盖。
(2) 处理 side-effect file
任务的 side-effect file 并不是任务的最终输出文件,而是具有特殊用途的任务专属文件。 它的典型应用是执行推测式任务。 在 Hadoop 中,因为硬件老化、网络故障等原因,同一个作业的某些任务执行速度可能明显慢于其他任务,这种任务会拖慢整个作业的执行速度。为了对这种“ 慢任务” 进行优化, Hadoop 会为之在另外一个节点上启动一个相同的任务,该任务便被称为推测式任务,最先完成任务的计算结果便是这块数据对应的处理结果。为防止这两个任务同 时往一个输出 文件中 写入数据时发生写冲突, FileOutputFormat会为每个 Task 的数据创建一个 side-effect file,并将产生的数据临时写入该文件,待 Task完成后,再移动到最终输出目 录中。 这些文件的相关操作, 比如创建、删除、移动等,均由 OutputCommitter 完成。它是一个接口,Hadoop 提供了默认实现 FileOutputCommitter,用户也可以根据自己的需求编写 OutputCommitter 实现, 并通过参数 {mapred.output.committer.class} 指定。OutputCommitter 接口定义以及 FileOutputCommitter 对应的实现如表所示。
表-- OutputCommitter 接口定义以及 FileOutputCommitter 对应的实现
| 方法 | 何时被调用 | FileOutputCommitter 实现 |
| setupJob | 作业初始化 | 创建临时目录 ${mapred.out.dir} /_temporary |
| commitJob | 作业成功运行完成 | 删除临时目录,并在${mapred.out.dir} 目录下创建空文件_SUCCESS |
| abortJob | 作业运行失败 | 删除临时目录 |
| setupTask | 任务初始化 | 不进行任何操作。原本是需要在临时目录下创建 side-effect file 的,但它是用时创建的(create on demand) |
| needsTaskCommit | 判断是否需要提交结果 | 只要存在side-effect file,就返回 true |
| commitTask | 任务成功运行完成 | 提交结果, 即将 side-effect file 移动到 ${mapred.out.dir} 目录下 |
| abortTask | 任务运行失败 | 删除任务的 side-effect file注意默认情况下,当作业成功运行完成后,会在最终结果目录 ${mapred.out.dir} 下生成 |
注意:默认情况下,当作业成功运行完成后,会在最终结果目录 ${mapred.out.dir} 下生成空文件 _SUCCESS。该文件主要为高层应用提供作业运行完成的标识,比如,Oozie 需要通过检测结果目 录下是否存在该文件判 断作业是否运行完成。
2. 新版 API 的 OutputFormat 解析
如图所示,除了接口变为抽象类外,新 API 中的 OutputFormat 增加了一个新的方法:getOutputCommitter,以允许用户自 己定制合适的 OutputCommitter 实现。
参考资料
《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》
hadoop中OutputFormat 接口的设计与实现的更多相关文章
- hadoop中InputFormat 接口的设计与实现
InputFormat 主要用于描述输入数据的格式, 它提供以下两个功能.❑数据切分:按照某个策略将输入数据切分成若干个 split, 以便确定 Map Task 个数以及对应的 split.❑为 M ...
- Hadoop中OutputFormat解析
一.OutputFormat OutputFormat描述的是MapReduce的输出格式,它主要的任务是: 1.验证job输出格式的有效性,如:检查输出的目录是否存在. 2.通过实现RecordWr ...
- Hadoop中常用的InputFormat、OutputFormat(转)
Hadoop中的Map Reduce框架依赖InputFormat提供数据,依赖OutputFormat输出数据,每一个Map Reduce程序都离不开它们.Hadoop提供了一系列InputForm ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
- Hadoop中两表JOIN的处理方法(转)
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的.而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的 ...
- Hadoop中两表JOIN的处理方法
Dong的这篇博客我觉得把原理写的很详细,同时介绍了一些优化办法,利用二次排序或者布隆过滤器,但在之前实践中我并没有在join中用二者来优化,因为我不是作join优化的,而是做单纯的倾斜处理,做joi ...
- Hadoop介绍-4.Hadoop中NameNode、DataNode、Secondary、NameNode、JobTracker TaskTracker
Hadoop是一个能够对大量数据进行分布式处理的软体框架,实现了Google的MapReduce编程模型和框架,能够把应用程式分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行.在MapR ...
- 【总结】浅谈JavaScript中的接口
一.什么是接口 接口是面向对象JavaScript程序员的工具箱中最有用的工具之一.在设计模式中提出的可重用的面向对象设计的原则之一就是“针对接口编程而不是实现编程”,即我们所说的面向接口编程,这个概 ...
随机推荐
- ul>li中自定义属性后取值的问题
动态赋值的li: $.ajax({ type: "POST", url: "${base}/before/subDemand/listType", succes ...
- ref:spring-data-XMLBean XXE复现分析
ref:https://blog.spoock.com/2018/05/16/cve-2018-1259/ 漏洞信息 看pivotal发布的漏洞信息如下 通过发布的漏洞信息可以知道,漏洞组件是在XML ...
- 【UOJ #205】【APIO 2016】Fireworks
http://uoj.ac/problem/205 好神的题啊. dp[i][j]表示以i为根的子树调整成长度j需要的最小代价. 首先要观察到dp值是一个下凸壳. 因为从儿子合并到父亲时要把所有儿子的 ...
- 求矩阵中各列数字的和 Exercise08_01
import java.util.Scanner; /** * @author 冰樱梦 * 时间:2018年12月 * 题目:求矩阵中各列数字的和 * */ public class Exercise ...
- 卡特兰数 codevs 1086 栈
1086 栈 2003年NOIP全国联赛普及组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Description ...
- php 对二维数组的某个字段公用排序的方法
function array_sort($arr ,$keys,$order=0){ if(!is_array($arr)){ return false; } $keysvalue=array(); ...
- HDU 5297 Y sequence 容斥 迭代
Y sequence 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5297 Description Yellowstar likes integer ...
- spring集合类型注入
spring集合类型注入 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE beans PUB ...
- AX5511 Boost Converter
GENERAL DESCRIPTION The AX5511 is a current mode step up converter intended for small, low powera ...
- 面试题1:如何实现C++单例模式?
1. 软件领域中的设计模式为开发人员提供了一种使用专家设计经验的有效途径.设计模式中运用了面向对象编程语言的重要特性:封装.继承.多态.真正领悟设计模式的精髓是可能一个漫长的过程,需要大量实践经验的积 ...