spark[源码]-Pool分析
概述
这篇文章主要是分析一下Pool这个任务调度的队列。整体代码量也不是很大,正好可以详细的分析一下,前面在TaskSchedulerImpl提到大体的功能,这个点在丰富一下吧。
DAGScheduler负责构建具有依赖关系的任务集,TaskSetManger负责在具体的任务集内部调度任务,而TaskScheduler负责将资源提供给TaskSetManger供其作为调度任务的依据,但是每个sparkContext可能同时存在多个可运行的任务集,因此需要调度池pool来进行协调管理。
初始化源码解析
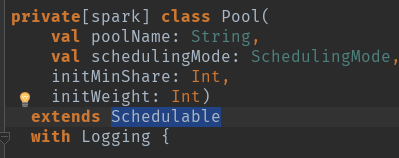
poolname:名字
schedulingMode:调度模式,FAIR(公平调度),FIFO,默认是FIFO的方式。
initWeight:调度池权重
initMinShare:计算资源中的cpu核数
先看一下扩展类Schedulable,Scheduler是一个特征类,pool是其具体的实现.
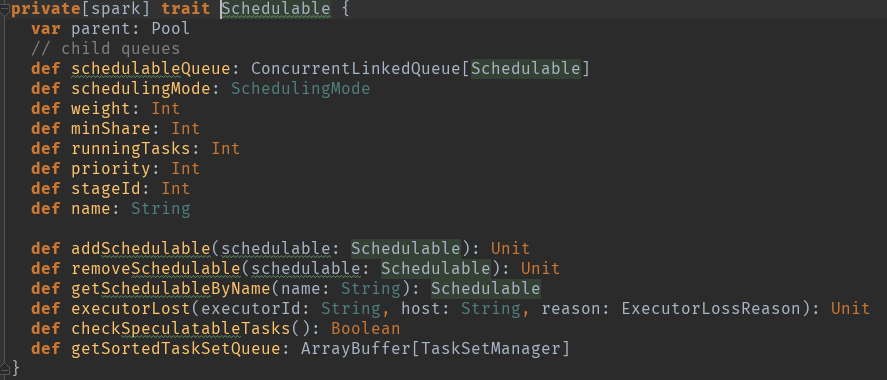
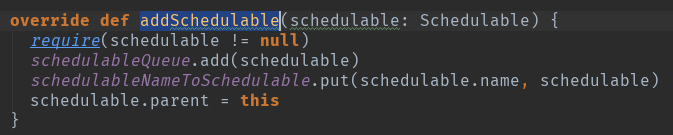
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
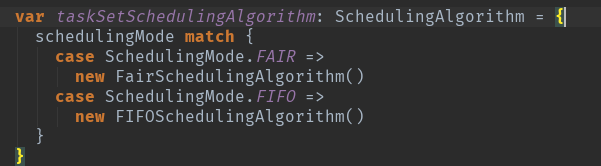
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
方法解析
TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认是FIFO)创建一个rootPool根调度池,之后根据具体的调度模式再进一步创建ScheduleBuilder对象,具体的ScheduleBuilder对象的BuildPools方法将在rootPool的基础上完成整个Pool的构建工作,之后就有通过addSchedulable将taskSetManger和pool关联起来了。
Schedulable有两个类,一个是pool,一个是TaskSetManager。
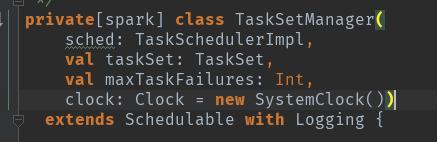
Pool直接管理的是TaskSetManager,每个TaskSetManager创建时都存储了其对应的StageID.
具体的调度算法,等以后的文章在做详细分析吧。
spark[源码]-Pool分析的更多相关文章
- Spark源码分析(一)-Standalone启动过程
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3858065.html 为了更深入的了解spark,现开始对spark源码进行分析,本系列文章以spark ...
- Spark源码分析 -- TaskScheduler
Spark在设计上将DAGScheduler和TaskScheduler完全解耦合, 所以在资源管理和task调度上可以有更多的方案 现在支持, LocalSheduler, ClusterSched ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源码分析之四:Stage提交
各位看官,上一篇<Spark源码分析之Stage划分>详细讲述了Spark中Stage的划分,下面,我们进入第三个阶段--Stage提交. Stage提交阶段的主要目的就一个,就是将每个S ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- spark 源码分析之四 -- TaskScheduler的创建和启动过程
在 spark 源码分析之二 -- SparkContext 的初始化过程 中,第 14 步 和 16 步分别描述了 TaskScheduler的 初始化 和 启动过程. 话分两头,先说 TaskSc ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
随机推荐
- UIViewController三种不同的初始化view的方式
You can specify the views for a view controller using a Storyboard created in Interface Builder. A s ...
- Node.js的全局对象和全局变量
http://blog.csdn.net/leftfist/article/details/41877279
- 剑指 offer set 28 实现 Singleton 模式
singleton 模式又称单例模式, 它能够保证只有一个实例. 在多线程环境中, 需要小心设计, 防止两个线程同时创建两个实例. 解法 1. 能在多线程中工作但效率不高 public sealed ...
- 机器学习(Machine Learning)
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科.
- iOS:友盟SDK第三方登录 分享及友盟统计的使用
本文转载至 http://www.it165.net/pro/html/201503/37101.html Tag标签:第三方 01.#import "UMSocial.h" ...
- Ubuntu安装atom
sudo add-apt-repository ppa:webupd8team/atom sudo apt-get update sudo apt-get install atom 安装的时如果报错, ...
- JavaWeb配置错误页面
我们在实际开发过程中经常会遇到程序出错的各种情况,比如最常见的404错误,500错误等等相关错误,服务器默认会将错误的信息直接显示在浏览器的页面上,如下图所示: 不管是谁如果看到这种情况的话,顿时就会 ...
- POJ3150—Cellular Automaton(循环矩阵)
题目链接:http://poj.org/problem?id=3150 题目意思:有n个数围成一个环,现在有一种变换,将所有距离第i(1<=i<=n)个数小于等于d的数加起来,对m取余,现 ...
- Gartner提出的7种多租户模型
下面,我们就来看看在SaaS应用搭建过程中,可以采用什么样的多租户模型.从而能较为清晰地了解未来使用PaaS平台开发的SaaS,可以为用户提供哪些多租户的服务. Gartner提出了7种 ...
- linux dpdk DDOS清洗和流量行为分析
http://www.linuxidc.com/Linux/2014-09/106285.htm http://www.th7.cn/system/lin/201403/51652.shtml DDO ...