spark[源码]-Pool分析
概述
这篇文章主要是分析一下Pool这个任务调度的队列。整体代码量也不是很大,正好可以详细的分析一下,前面在TaskSchedulerImpl提到大体的功能,这个点在丰富一下吧。
DAGScheduler负责构建具有依赖关系的任务集,TaskSetManger负责在具体的任务集内部调度任务,而TaskScheduler负责将资源提供给TaskSetManger供其作为调度任务的依据,但是每个sparkContext可能同时存在多个可运行的任务集,因此需要调度池pool来进行协调管理。
初始化源码解析
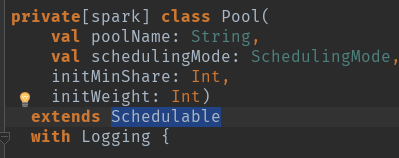
poolname:名字
schedulingMode:调度模式,FAIR(公平调度),FIFO,默认是FIFO的方式。
initWeight:调度池权重
initMinShare:计算资源中的cpu核数
先看一下扩展类Schedulable,Scheduler是一个特征类,pool是其具体的实现.
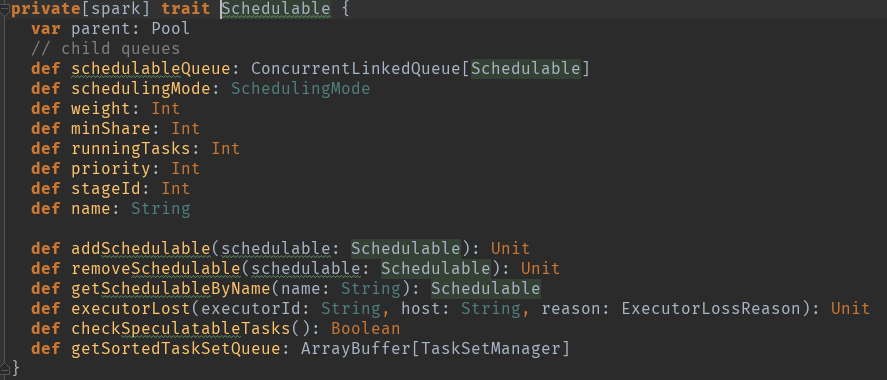
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
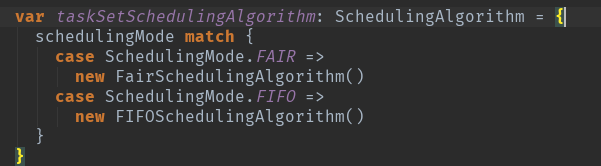
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
方法解析
TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认是FIFO)创建一个rootPool根调度池,之后根据具体的调度模式再进一步创建ScheduleBuilder对象,具体的ScheduleBuilder对象的BuildPools方法将在rootPool的基础上完成整个Pool的构建工作,之后就有通过addSchedulable将taskSetManger和pool关联起来了。
Schedulable有两个类,一个是pool,一个是TaskSetManager。
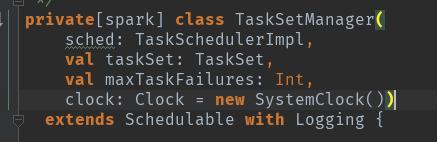
Pool直接管理的是TaskSetManager,每个TaskSetManager创建时都存储了其对应的StageID.
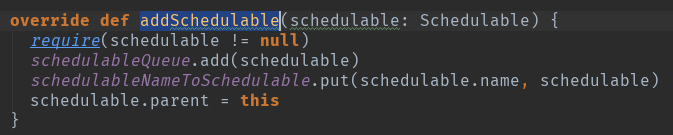
具体的调度算法,等以后的文章在做详细分析吧。
spark[源码]-Pool分析的更多相关文章
- Spark源码分析(一)-Standalone启动过程
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3858065.html 为了更深入的了解spark,现开始对spark源码进行分析,本系列文章以spark ...
- Spark源码分析 -- TaskScheduler
Spark在设计上将DAGScheduler和TaskScheduler完全解耦合, 所以在资源管理和task调度上可以有更多的方案 现在支持, LocalSheduler, ClusterSched ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源码分析之四:Stage提交
各位看官,上一篇<Spark源码分析之Stage划分>详细讲述了Spark中Stage的划分,下面,我们进入第三个阶段--Stage提交. Stage提交阶段的主要目的就一个,就是将每个S ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- spark 源码分析之四 -- TaskScheduler的创建和启动过程
在 spark 源码分析之二 -- SparkContext 的初始化过程 中,第 14 步 和 16 步分别描述了 TaskScheduler的 初始化 和 启动过程. 话分两头,先说 TaskSc ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
随机推荐
- hdu 1520(简单树形dp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1520 思路:dp[u][0]表示不取u的最大价值,dp[u][1]表示取u的最大价值,于是有dp[u] ...
- Codeforces 417 D. Cunning Gena
按monitor排序,然后状压DP... . D. Cunning Gena time limit per test 1 second memory limit per test 256 megaby ...
- ios 开发环境,证书和授权文件
一.成员介绍1. Certification(证书)证书是对电脑开发资格的认证,每个开发者帐号有一套,分为两种:1) Developer Certification(开发证书)安装在电脑上 ...
- vue模糊查询
模糊查询匹配结果 <!-- 搜索框 --> <div class="search-wrapper"> <input type="text&q ...
- kettle中denormalizer(列转行)的使用
转载: 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://sucre.blog.51cto.com/1084905/1434015 ...
- msvcp71.dll 怎么丢失的?如何修复
解决方法:另一台电脑上下载这个dll,再用优盘拷回来,复制到c:\windows\system32\下. 个人遇到的情况:迅雷下载东西时,或者在操作迅雷时出现的. win7 64位下 点击下载
- 文艺青年装B指南
和大龄文艺青年们去凤凰的时候,很难不注意到狭窄小道旁边的文艺小店.有提供焦糖玛奇朵的咖啡店,有兜售梦露赫本明信片和烟雨 凤凰笔记本的店铺,还有复古式的静吧,常驻唱民谣小众歌曲的流浪歌手.我每看 ...
- 170323、Spring 事物机制总结
spring两种事物处理机制,一是声明式事物,二是编程式事物 声明式事物 1)Spring的声明式事务管理在底层是建立在AOP的基础之上的.其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加 ...
- java方法的理解、调用栈与异常处理
一.流程分支 If/else :基于boolean值的双分支 Switch:基于数字(整数.char.byte.枚举).字符串 类型的多分支 Int month =5; Switch 二.方法meth ...
- 【Python之路】Python目录
Python基础1 -- Python由来.Python种类.编码方式, Python基础2 -- Python运算符.数据类型.enumerate.range.for循环 python基础3 -- ...