pandas contact 之后,若要用到index列,要记得用reset_index去处理index
# -*- coding: utf-8 -*-
import pandas as pd
import sys df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}) df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']}) df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']}) frames = [df1, df2, df3]
result = pd.concat(frames)
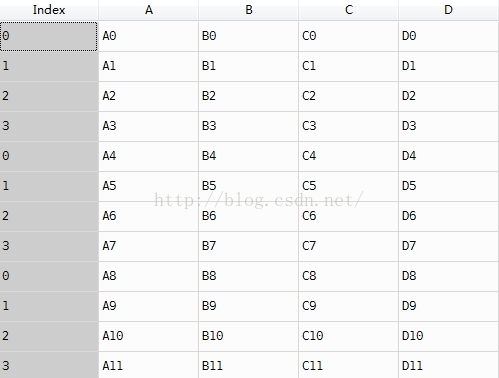
说明:直接contact之后,index只是重复,而不是变成我们希望的那样,这样在后续的操作中,容易出现逻辑错误。
- df4 = pd.DataFrame({'val':[0,1,2,3,4,5,6,7,8,9,10,11],'A': ['A0', 'A1', 'A2', 'A3','A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11'],})
- result['val'] = df4['val']
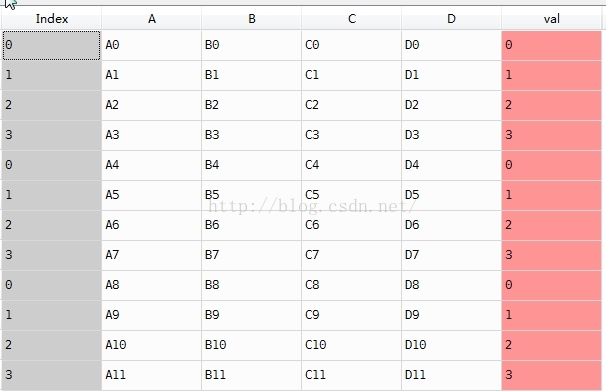
说明:result['val'] = df4['val'] 是按照index赋值的,所以,结果就出乎我们的意料。
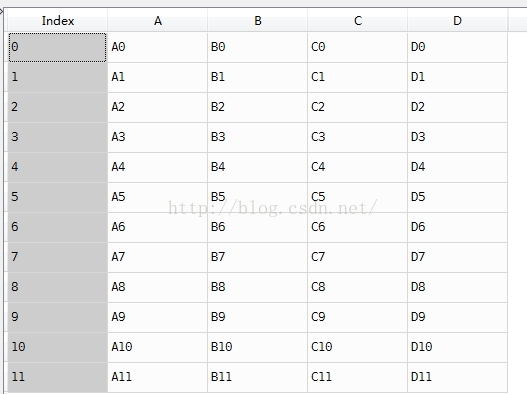
使用result = result.reset_index(drop=True)来改变index就可以了,
转自:https://blog.csdn.net/lujiandong1/article/details/52929090
pandas contact 之后,若要用到index列,要记得用reset_index去处理index的更多相关文章
- Update-Package : Unable to load the service index for source https://api.nuget.org/v3/index.json.
由于更改了项目"属性"的"目标框架"(原来的框架是".NET Frameword4.5"改为了".NET Frameword4&q ...
- Visual Studio 2015 NuGet Update-Package 失败/报错:Update-Package : Unable to load the service index for source https://api.nuget.org/v3/index.json.
起因 为了用VS2015 community中的NuGet获取Quartz,在[工具]-[NuGet包管理器]-[程序包管理器控制台]中执行 Install-Package Quartz. 却报如下错 ...
- MySQL5.6之Index Condition Pushdown(ICP,索引条件下推)-Using index condition
http://blog.itpub.net/22664653/viewspace-1210844/ -- 这篇博客写的更细,以后看 ICP(index condition pushdown)是mysq ...
- pandas数据处理基础——筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 ...
- pandas dataframe在指定的位置添加一列, 或者一次性添加几列,re
相信有很多人收这个问题的困扰,如果你想一次性在pandas.DataFrame里添加几列,或者在指定的位置添加一列,都会很苦恼找不到简便的方法:可以用到的函数有df.reindex, pd.conca ...
- 吴裕雄--天生自然python学习笔记:pandas模块用 dataframe.loc 通过行、列标题读取数据
用 df.va lue s 读取数据的前提是必须知道学生及科目的位置,非常麻烦 . 而 df.loc 可直接通过行.列标题读取数据,使用起来更为方便 . 使用 df.loc 的语法为: 行标题或列标题 ...
- logstash配置白名单决定去哪个index
input { kafka { bootstrap_servers => "127.0.0.1:9092" client_id => "log" a ...
- [Partition][Index]对于Partition表而言,是否Global Index 和 Local Index 可以针对同一个字段建立?
对于Partition表而言,是否Global Index 和 Local Index 可以针对同一个字段建立? 实验证明,对单独的列而言,要么建立 Global Index, 要么建立 Local ...
- index row size 2720 exceeds maximum 2712 for index "xxx" ,Values larger than 1/3 of a buffer page cannot be indexed.
记录一个bug情况: 我有个表NewTable,复合主键(slaveid,resid,owner) CREATE TABLE "public"."NewTable&quo ...
随机推荐
- 三分钟教你学Git (四)之紧急救助
假设你不小心git reset --hard HEAD^ 然后这个commit又没有在别的git仓库中,怎么办?是不是这次改动就丢了呢? 当然不是,git为我们每次都历史都保留了reference l ...
- JavaScript面向对象编程指南(第2版)》读书笔记
一.对象 1.1 获取属性值的方式 water = { down: false } console.log(water.down) // false console.log(water['down'] ...
- 【redis】redis五大类 用法 【转载:https://www.cnblogs.com/yanan7890/p/6617305.html】
转载地址:https://www.cnblogs.com/yanan7890/p/6617305.html
- PHP 输出数据库中文是问号
- java解析json数组
java解析json数组 import org.json.JSONArray; import org.json.JSONException; import org.json.JSONObject; ...
- [Android Pro] Android 必知必会-使用 supportV4 的 RoundedBitmapDrawable 实现圆角
RoundedBitmapDrawable 是 supportV4 下的一个类,有了它,显示圆角和圆形图片的情况下就不需要额外的第三方类库了,还能和各种图片加载库配合使用. 背景 今天无意间看到一段实 ...
- Kafka目录
1. kafka生产者.消费者java示例 2. apache kafka监控系列-KafkaOffsetMonitor(转) 3. Kafka0.8.2删除topic逻辑(转) 4. spark s ...
- Linux系统getopt使用示例
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <stdint.h&g ...
- OpenCV学习(2) OpenCV的配置
下面我们在VS2010中编写一个简单的OpenCV程序,来看看如何在程序中使用OpenCV. 创建一个新的Win32 控制台程序,附加选项为空工程(empty project),并添加一个 ...
- 18 个最好的CSS框架用于提高开发效率
根据维基百科,CSS框架是事先准备好的库,是为了让使用层叠样式表语言来美化网页更容易,更符合标准.在这篇文章中,我们已经收集了一些现成的框架,这将使你减少你的任务流程和代码.我们希望你会发现列表中的方 ...