python相关性分析与p值检验
## 最近两天的成果
'''
##########################################
# #
# 不忘初心 砥砺前行. #
# 418__yj #
##########################################
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
import datetime
import os
#求原始图像各波段相关系数与P值
def corr_p(data,spad):
print('[INFO]处理原始光谱曲线')
l1=[]
l2=[]
col=data.columns
num=len(data.index)
index=np.linspace(0,num-1,num)
data.index=index
spad.index=index
for i in col:
#pearsonr函数返回两个值,分别为相关系数以及P值(显著性水平)
#l1:相关系数列表,l2:p值列表
value=pearsonr(spad[spad.columns[0]],data[i])
l1.append(value[0])
l2.append(round(value[1],3))
corr_se=pd.Series(l1,index=col)
p_se=pd.Series(l2,index=col)
#因为不可避免的存在0.01,0.05水平线不存在,因此依次在附近寻找了+-0.002范围的值
index_001_list=[0.010,0.011,0.009,0.012,0.008]
index_005_list=[0.050,0.051,0.049,0.052,0.048]
index_001=[]
index_001_01=[]
index_005=[]
index_005_01=[]
for i in index_001_list:
index_001.append(list(p_se[p_se==i].index.values))
index_001_01.append(list(p_se[p_se==-i].index.values))
for i in index_005_list:
index_005.append(list(p_se[p_se==i].index.values))
index_005_01.append(list(p_se[p_se==-i].index.values))
#数据清洗
index_001=[list(i) for i in index_001 if len(list(i))!=0]
index_001_01=[list(i) for i in index_001_01 if len(list(i))!=0]
index_005=[list(i) for i in index_005 if len(list(i))!=0]
index_005_01=[list(i) for i in index_005_01 if len(list(i))!=0]
print(index_001,index_005)
#p=0.01,p=0.05所对应波段的相关系数值
p_001=corr_se[index_001[0][0]]
p_005=corr_se[index_005[0][0]]
#对单个值的横向填充为PD.SERIES
p_001_data=get_p_value(p_001,corr_se,name='p_001')
p_005_data=get_p_value(p_005,corr_se,name='p_005')
corr=pd.concat([corr_se,p_001_data,p_005_data],axis=1)
idmax=corr_se.idxmax()
idmin=corr_se.idxmin()
print('p_001,p_005')
print(p_001,p_005)
print('*')
print('[INFO]idmax:%s,idmin:%s'%(idmax,idmin))
#绘图
s='diff.png'
xticks=np.arange(339,2539,200)
draw(corr,s,xticks)
#写入txt文档,0.01,0.05交点用于分析
with open('./output/corr_original.txt','w') as f:
f.writelines(u'最大相关系数所对应波段:'+str(idmax)+'\n')
f.writelines('相关系数最大值:'+str(corr_se[idmax])+'\n')
f.writelines('负相关最大所对应波段:'+str(idmin)+'\n')
f.writelines('负相关最大值:'+str(corr_se[idmin])+'\n')
f.writelines('0.05水平线与负相关系数曲线交点:'+str(index_005)+'\n')
f.writelines('0.05水平线与正相关系数曲线交点:'+str(index_005_01)+'\n')
f.writelines('0.01水平线与负相关系数曲线交点:'+str(index_001)+'\n')
f.writelines('0.01水平线与正相关系数曲线交点:'+str(index_001_01)+'\n')
def get_p_value(p_value,corr_se,name):
#empty=np.zeros_like(corr_se)
min_corr=corr_se.min()
max_corr=corr_se.max()
if min_corr*max_corr>0:
se=pd.Series(p_value,index=corr_se.index)
se.name=name
return se
else:
#empty_1=empty.copy()
#empty_1[:]=p_se
se_1=pd.Series(p_value,index=corr_se.index)
se_1.name=name
#empty_2=empty.copy()
#empty_2[:]=-p_se
se_2=pd.Series(-p_value,index=corr_se.index)
se_2.name=name+'_01'
return pd.concat([se_1,se_2],axis=1)
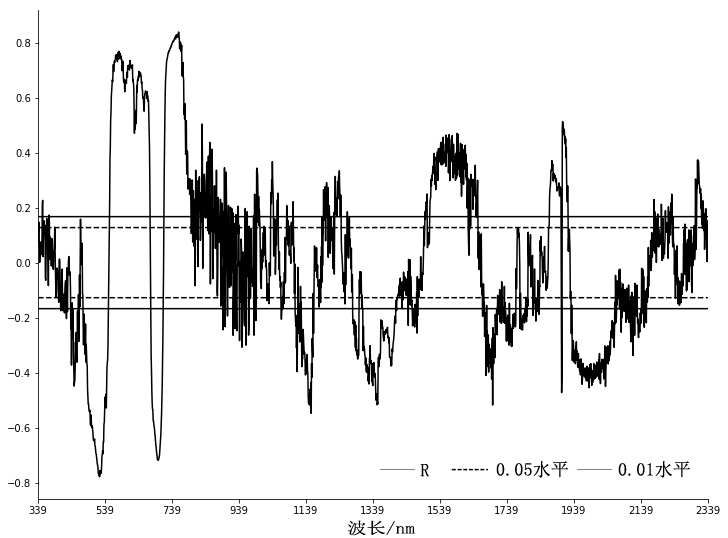
def draw(corr,s,xticks):
'''
if corr.columns[0]==338:
xticks=np.arange(338,2538,200)
xlim=(338,2538)
elif corr.columns[0]==339:
xticks=np.arange(339,2539,200)
xlim=(339,2539)
UnboundLocalError:
'''
print('corrr.columns:%s'%corr.columns)
style={0:'k','p_001':'k','p_001_01':'k','p_005':'k--','p_005_01':'k--'}
corr.plot(style=style,xticks=xticks,xlim=(xticks.min(),xticks.max()),figsize=(12,9))
ax=plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.savefig('./output/'+s)
def diff_corr_p(data,spad):
print('[INFO]处理一阶导数曲线')
l1=[]
l2=[]
#相比原始图像,一阶导数要先转为np.array做差分处理,再转为dataframe
array=np.array(data)
diff_array=np.diff(array,axis=1)
num=len(data.index)
index=np.linspace(0,num-1,num)
spad.index=index
data=pd.DataFrame(diff_array,columns=data.columns[:-1],index=index)
col=data.columns
#输出Excel
#data.to_excel('./output/diff.xlsx')
for i in col:
#pearsonr函数返回两个值,分别为相关系数以及P值(显著性水平)
#l1:相关系数列表,l2:p值列表
value=pearsonr(spad[spad.columns[0]],data[i])
l1.append(value[0])
l2.append(round(value[1],3))
corr_se=pd.Series(l1,index=col)
p_se=pd.Series(l2,index=col)
#因为不可避免的存在0.01,0.05水平线不存在,因此依次在附近寻找了+-0.002范围的值
index_001_list=[0.010,0.011,0.009,0.012,0.008]
index_005_list=[0.050,0.051,0.049,0.052,0.048]
index_001=[]
index_001_01=[]
index_005=[]
index_005_01=[]
for i in index_001_list:
index_001.append(list(p_se[p_se==i].index.values))
index_001_01.append(list(p_se[p_se==-i].index.values))
for i in index_005_list:
index_005.append(list(p_se[p_se==i].index.values))
index_005_01.append(list(p_se[p_se==-i].index.values))
#数据清洗
index_001=[list(i) for i in index_001 if len(list(i))!=0]
index_001_01=[list(i) for i in index_001_01 if len(list(i))!=0]
index_005=[list(i) for i in index_005 if len(list(i))!=0]
index_005_01=[list(i) for i in index_005_01 if len(list(i))!=0]
print(index_001,index_005)
#p=0.01,p=0.05所对应波段的相关系数值
p_001=corr_se[index_001[0][0]]
p_005=corr_se[index_005[0][0]]
#对单个值的横向填充为PD.SERIES
p_001_data=get_p_value(p_001,corr_se,name='p_001')
p_005_data=get_p_value(p_005,corr_se,name='p_005')
corr=pd.concat([corr_se,p_001_data,p_005_data],axis=1)
idmax=corr_se.idxmax()
idmin=corr_se.idxmin()
print('[INFO]idmax:%s,idmin:%s'%(idmax,idmin))
#绘图
s='diff.png'
xticks=np.arange(339,2539,200)
draw(corr,s,xticks)
#写入txt文档,0.01,0.05交点用于分析
with open('./output/corr_diff.txt','w') as f:
f.writelines(u'最大相关系数所对应波段:'+str(idmax)+'\n')
f.writelines('相关系数最大值:'+str(corr_se[idmax])+'\n')
f.writelines('负相关最大所对应波段:'+str(idmin)+'\n')
f.writelines('负相关最大值:'+str(corr_se[idmin])+'\n')
f.writelines('0.05水平线与负相关系数曲线交点:'+str(index_005)+'\n')
f.writelines('0.05水平线与正相关系数曲线交点:'+str(index_005_01)+'\n')
f.writelines('0.01水平线与负相关系数曲线交点:'+str(index_001)+'\n')
f.writelines('0.01水平线与正相关系数曲线交点:'+str(index_001_01)+'\n')
def main():
starttime = datetime.datetime.now()
print(__doc__)
print('''该脚本可能会运行几分钟,最终结果会保存在当前目录的output文件夹下,包括以下内容:
1:经过重采样处理的SVC的.sig文件以EXCEL形式汇总[sig.xlsx]
2: 所有小区一阶导数[diff.xlsx]
3:0.05水平,0.01水平的原始图像相关性检验[original.png]
4:0.05水平,0.01水平的一阶导数光谱相关性检验[diff.png]
5:原始图像相关性最大波段的及相关系数[corr_original.txt]
6:一阶导数相关性最大波段的及相关系数[corr_diff.txt]
说明:本人才疏学浅,对遥感反演原理不甚了解,数据处理中有诸多纰漏,望慎重使用,以免给各位带来不必要的麻烦。
''')
print('[INFO]加载数据集...')
path_sig='../output/sig.xlsx'
sig=pd.read_excel(path_sig,'Sheet3')
path='../spad/spad.xlsx'
spad=pd.read_excel(path)
if not os.path.exists('./output'):
os.mkdir('./output')
corr_p(sig.copy(),spad.copy())
diff_corr_p(sig.copy(),spad.copy())
endtime = datetime.datetime.now()
print('-'*80)
print('程序运行时间:%s s'%((endtime - starttime).seconds))
'''
corr_se[1334]
Out[28]: -0.16722162390032191
EMPTY_SE_001=np.zeros_like(corr_se)
EMPTY_SE_001[:]=-0.16722162390032191
se_01=pd.Series(EMPTY_SE_001,index=index)
corr=pd.concat([corr_se,se_01,se_05],axis=1)
'''
#diff_array=np.diff(sig_array,axis=1)
'''
diff_corr_se[diff_p_se[diff_p_se==0.01].index]
Out[100]:
991 -0.167330
1071 -0.167740
1100 0.166970
1215 0.166174
1232 0.167815
1308 -0.166201
1426 -0.166492
1709 -0.166323
1735 -0.167574
1819 -0.166347
2094 -0.167152
2129 -0.167569
2321 0.167649
2383 0.167009
2478 0.167431
2505 0.166817
dtype: float64
'''
'''
diff_1.idxmax()
Out[139]:
0 759
1 339
2 339
1 339
2 339
dtype: int64
diff_1[0][759]
Out[140]: 0.8388844431717504
diff_1.idxmin()
Out[141]:
0 523
1 339
2 339
1 339
2 339
dtype: int64
diff_1[0][523]
Out[142]: -0.7787709002181252
'''
main()
python相关性分析与p值检验的更多相关文章
- Python文章相关性分析---金庸武侠小说分析
百度到<金庸小说全集 14部>全(TXT)作者:金庸 下载下来,然后读取内容with open('names.txt') as f: data = [line.strip() for li ...
- Python文章相关性分析---金庸武侠小说分析-2018.1.16
最近常听同事提及相关性分析,正巧看到这个google的开源库,并把相关操作与调试结果记录下来. 输出结果: 比较有意思的巧合是黄蓉使出打狗棒,郭靖就用了降龙十八掌,再后测试了名词的解析. 小说集可以百 ...
- python数据相关性分析 (计算相关系数)
#-*- coding: utf-8 -*- #餐饮销量数据相关性分析 计算相关系数 from __future__ import print_function import pandas as pd ...
- 用Python学分析 - 单因素方差分析
单因素方差分析(One-Way Analysis of Variance) 判断控制变量是否对观测变量产生了显著影响 分析步骤 1. 建立检验假设 - H0:不同因子水平间的均值无差异 - H1:不同 ...
- SPSS分析技术:CMH检验(分层卡方检验);辛普森悖论,数据分析的谬误
SPSS分析技术:CMH检验(分层卡方检验):辛普森悖论,数据分析的谬误 只涉及两个分类变量的卡方检验有些时候是很局限的,因为混杂因素总是存在,如果不考虑混杂因素,得出的分析结论很可能是谬误的,这就是 ...
- 使用R进行相关性分析
基于R进行相关性分析 一.相关性矩阵计算: [1] 加载数据: >data = read.csv("231-6057_2016-04-05-ZX_WD_2.csv",head ...
- Python股票分析系列——系列介绍和获取股票数据.p1
本系列转载自youtuber sentdex博主的教程视频内容 https://www.youtube.com/watch?v=19yyasfGLhk&index=4&list=PLQ ...
- Python数据采集分析告诉你为何上海二手房你都买不起
感谢关注Python爱好者社区公众号,在这里,我们会每天向您推送Python相关的文章实战干货. 来吧,一起Python. 对商业智能BI.大数据分析挖掘.机器学习,python,R等数据领域感兴趣的 ...
- 【转】python模块分析之collections(六)
[转]python模块分析之collections(六) collections是Python内建的一个集合模块,提供了许多有用的集合类. 系列文章 python模块分析之random(一) pyth ...
随机推荐
- 【构造】Codeforces Round #405 (rated, Div. 1, based on VK Cup 2017 Round 1) A. Bear and Different Names
如果某个位置i是Y,直接直到i+m-1为止填上新的数字. 如果是N,直接把a[i+m-1]填和a[i]相同即可,这样不影响其他段的答案. 当然如果前面没有过Y的话,都填上0就行了. #include& ...
- mysql数据操作
了解:Mysql 账号相关 创建账号: 权限:user(所有库的权限)-->db(某个库的权限)-->table_priv(某张表的权限) -->columns_oriv(某个字段的 ...
- [转]tx:advice标签简介
<Spring高级程序设计>第16章事务管理,通过本章的学习,你知道了如何使用Spring去管理事务,而这种方式几乎不会对你的源代码产生任何影响.你现在知道了如何使用本地和全局事务,并知道 ...
- Xcode9出现错误safe area layout guide before ios 9 真正解决办法
网上很多解决办法瞎扯淡,以讹传讹之势愈演愈烈. 正解是选中控制器,右边面板的Builds for 选择iOS9.0 and Later,如下图红框广为流传的错解是不勾选Use Safe Area La ...
- SQL SERVER 2008 数据库置疑处理办法
1.修改数据库为紧急模式 ALTER DATABASE Zhangxing SET EMERGENCY 2.使数据库变为单用户模式 ALTER DATABASE Zhangxing SET SINGL ...
- 基于指定文本的百度地图poi城市检索的使用(思路最重要)
(转载请注明出处哦)具体的百度地图权限和apikey配置以及基础地图的配置不叙述,百度地图定位可以看这个链接的http://blog.csdn.net/heweigzf/article/details ...
- Git 对比 SVN
转自:http://www.aqee.net/5-fundamental-differences-between-git-svn/ 我是一开始就用Mercurial, Git这类的系统.(现在已经百分 ...
- 【LaTeX】E喵的LaTeX新手入门教程(1)准备篇
昨天熄灯了真是坑爹.前情回顾[LaTeX]E喵的LaTeX新手入门教程(1)准备篇 [LaTeX]E喵的LaTeX新手入门教程(2)基础排版上一期测试答案1.大家一开始想到的肯定是\LaTeX{}er ...
- C语言大总结
C语言大总结 一. C语言基本常识 1.语言由函数组成 2.main是程序入口 3.C语言中不能出现中文或中文字符 (凝视和字符串除外) keyword : C语言提供表示特殊含义的单词 特点 : 1 ...
- [转]使用VS2010的Database 项目模板统一管理数据库对象
本文转自:http://www.cnblogs.com/shanyou/archive/2010/05/08/1730810.html Visual Studio 2010 有一个数据库项目模板:Vi ...