数据分析之CE找数据大法
一.基本介绍
CE的全称为Cheat Engine,是一款内存修改编辑工具,其官网是http://www.cheatengine.org,可以在其官网下载到最新的CE工具,目前最新版本是Cheat Engine6.5。CE同时也是一款开源的工具,使用者可以在git中下载源代码: https://github.com/cheat-engine/cheat-engine。
CE的功能包括有16进制编辑,反汇编程序,内存查找工具。与同类修改工具相比,它具有强大的反汇编功能及调试功能,可以附加到游戏中进行调试,所以是分析游戏的工具之一。
二.CE内存搜索功能的使用
1. 精确搜索:
CE的主界面如下图所示,使用CE搜索游戏数据,首先需要将CE附加到游戏进程中。
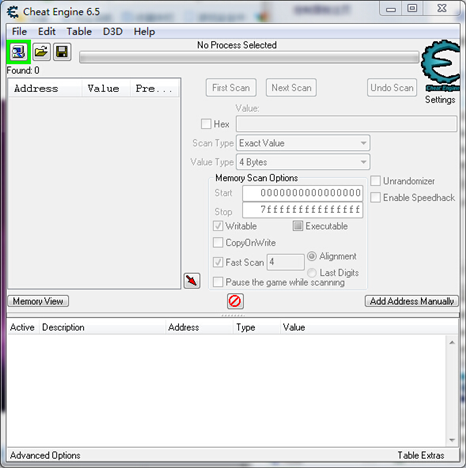
点击左上角菜单下发的绿色方框的按钮,打开进程列表对话框。
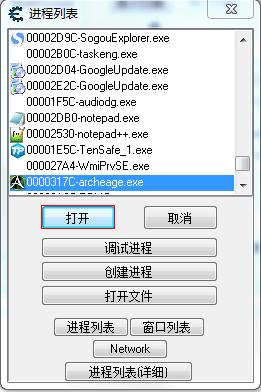
选择相应的游戏并点击打开,此时,就可以在数值搜索框中输入需要搜索的数据。比如搜索游戏中显示角色血量值的存放地址:
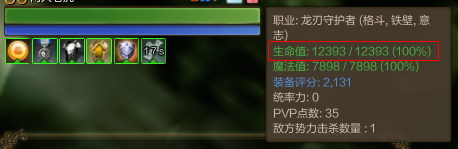
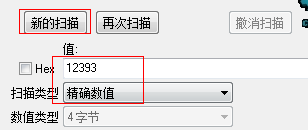
如上图血量所示,在CE的搜索数值输入框中输入“生命值”12393,选择扫描类型为“精确数值”,点击“新的扫描”开始第一次扫描。
搜索出的匹配值有98个,由于结果较多,这个时候不能确定正确的存放地址,需要再次搜索。
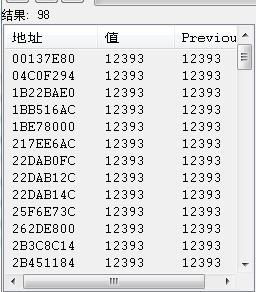
这个时候被怪打一下(使血量变化),输入新的生命值,点击“再次搜索”,此时的搜索值可以缩小到3个。
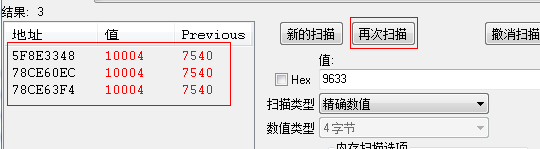
此时经过测试就可以发现第一个地址就是存放游戏界面中血量显示的地址。
2. 模糊搜索
如果搜索数值不确定的话,就需要使用模糊搜索的方法。使用模糊搜索的情况主要有具体数值不显示在游戏界面上,比如血量用百分比表示。模糊搜索的类型比较多,如下图所示:
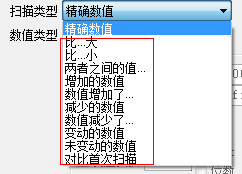
同样以搜索生命值为例,首次扫描时选择“未知的初始值”
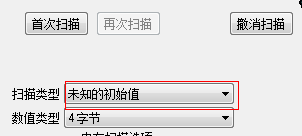
点击“首次扫描”,这个时候会出现非常多的扫描结果。这个时候去被怪物打一下减少血量后,由于此时数值是减小的,所以在扫描类型中选择“减少的数值”,然后点击再次扫描:
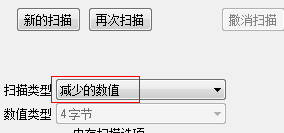
重复多次扫描后,即可找到存放的生命值的地址。
三.代码跟踪
代码跟踪比较常见的用途是找基址,游戏中任何数据都在内存中存在,比如角色的血,蓝,等级等数据,这些数值存放的方式一般是对象+偏移,在C++就是以指针的方式表示,如果需要知道对象在内存中的存放地址,就需要找到对象的基址。
需要知道对象的地址或数据的偏移,常见的方法就是找到访问或改变这个值的指令,可以使用Cheat Engine的反汇编及调试功能。
如上例的数据搜索找到的生命值存放的地址,将其放到CE最下方地址列表中,右键点击列表中的地址项,如下图所示,“找出是什么访问了这个地址”和“找出是什么改下了这个地址”分别可以跟踪生命值在代码的什么地方被读取和改写。
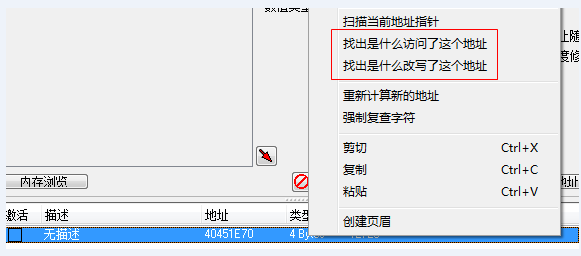
例如需要找到在血量被改写的地方,先在地址列表中右键点击“找出是什么改写了这个地址”,此时CE会附加到其内置的调试器,并自动列入对生命值进行写入的代码。
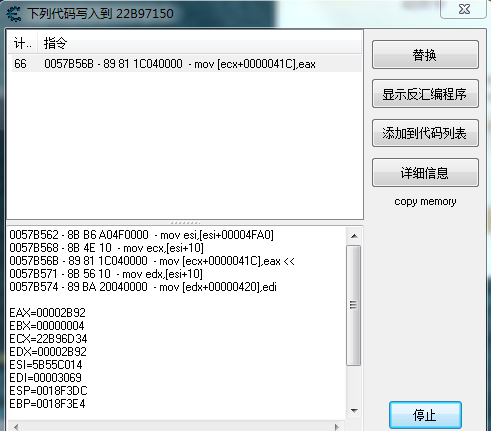
此时,ecx=0x22B96D34是对象的地址,血量通过eax赋值到+41Ch的地址漂移处。如上图所示,所以一级指针ecx的偏移+41Ch地址处。Ecx的赋值为上一条指令mov ecx, [esi+10],其二级指针是esi的偏移+10h地址处,再往上一条指令mov esi, [esi+4FA0],可以确定三级指针为esi,偏移为+4FA0h,以此类推,就可以找到血量存放的基址。
数据分析之CE找数据大法的更多相关文章
- 使用Python一步一步地来进行数据分析总结
原文链接:Step by step approach to perform data analysis using Python译文链接:使用Python一步一步地来进行数据分析--By Michae ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- 基于Python的数据分析(1):配置安装环境
数据分析是一个历史久远的东西,但是直到近代微型计算机的普及,数据分析的价值才得到大家的重视.到了今天,数据分析已经成为企业生产运维的一个核心组成部分. 据我自己做数据分析的经验来看,目前数据分析按照使 ...
- 数据分析之---Python可视化工具
1. 数据分析基本流程 作为非专业的数据分析人员,在平时的工作中也会遇到一些任务:需要对大量进行分析,然后得出结果,解决问题. 所以了解基本的数据分析流程,数据分析手段对于提高工作效率还是非常有帮助的 ...
- 使用docker搭建数据分析环境
注:早在学习<云计算>这门课之前就已经知道docker,学习这门课时老师还鼓励我们自己尝试一下:但是直到去年年底才有机会尝试,用过之后感觉确实很好用.最近需要部署几个shiny应用,又回顾 ...
- 数据分析侠A的成长故事
数据分析侠A的成长故事 面包君 同学A:22岁,男,大四准备实习,计算机专业,迷茫期 作为一个很普通的即将迈入职场的他来说,看到周边的同学都找了技术开发的岗位,顿觉自己很迷茫,因为自己不是那么喜欢钻 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- mysql 数据分析如何实现日报、周报、月报和年报?
以天为统计周期,是常见需求.周报.月报更是常见需求.长周期项目,甚至有年报需求.我已经掌握了mysql中按天统计,如何实现按年.按月.按周统计呢? 1.已掌握的技能:按天统计 实现以天为统计周期很简单 ...
- 小白学 Python 数据分析(7):Pandas (六)数据导入
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
随机推荐
- ACM 第十四天
字符串: 1.KMP算法(模式串达到1e6) 模式串达到1e4直接暴力即可. 字符串哈希 字符串Hash的种类还是有很多种的,不过在信息学竞赛中只会用到一种名为“BKDR Hash”的字符串Hash算 ...
- HTML页面垂直滚动条不见
<body style="overflow-y:scroll;"> </body>
- cacti 安装perl 和XML::Simple
一.安装perl #tar zxvf perl-5.20.1.tar.gz #cd perl-5.20.1 #./Configure -de #make #make test #make in ...
- vs中编译连接时的警告屏蔽
编译警告类型为warning C4996的形式 可以采用的#pragma warning(disable:4996)屏蔽掉这种编译警告 连接警告类型为warning LNK4049的形式 这是由于不同 ...
- 使用gdb查看栈帧的情况,有ebp
0x7fffffffdb30: 0x00000000 0x00000000 0xf7ffe700 0x0000001a0x7fffffffdb40: 0xffffdc98 ...
- 用css制作空心箭头(上下左右各个方向均有)
平常在网页中,经常会有空心箭头,除了用图片外,可以用css来实现.基本思路是,用css绘制两个三角形,通过绝对定位让两三角形不完全重叠,例如制作向右的空心箭头,位于前面的三角形border颜色是需要的 ...
- Android 数据库升级中数据保持和导入已有数据库
一.数据库升级: 在我们的程序中,或多或少都会涉及到数据库,使用数据库必定会涉及到数据库的升级,数据库升级带来的一些问题,如旧版本数据库的数据记录的保持,对新表的字段的添加等等一系列问题,还记得当我来 ...
- Android ListView 显示多种数据类型
ListView往往可能会有不同的数据类型,单类型的数据可能运用会比较少些,这也是最近项目中的一个需求{在发送消息的时候,需要选择联系人,而联系人列表由英文字母索引+联系人组成},上一篇文章只是一个基 ...
- POJ2406:Power Strings——题解
http://poj.org/problem?id=2406 就是给一个串,求其循环节的个数. 稍微想一下就知道,KMP中nxt数组记录了所有可与前面匹配的位置. 那么如果我们的循环节长度为k,有n个 ...
- BZOJ1036:[ZJOI2008]树的统计——题解
http://www.lydsy.com/JudgeOnline/problem.php?id=1036 题目描述 一棵树上有n个节点,编号分别为1到n,每个节点都有一个权值w. 我们将以下面的形式来 ...