边缘检测︱基于 HED网络TensorFlow 和 OpenCV 实现图片边缘检测
本文摘录自《手机端运行卷积神经网络的一次实践 – 基于 TensorFlow 和 OpenCV 实现文档检测功能》
只截取感兴趣 的片段。
.
一、边缘检测
1、传统边缘检测
Google 搜索 opencv scan document,是可以找到好几篇相关的教程的,这些教程里面的技术手段,也都大同小异,关键步骤就是调用 OpenCV 里面的两个函数,cv2.Canny() 和 cv2.findContours()。
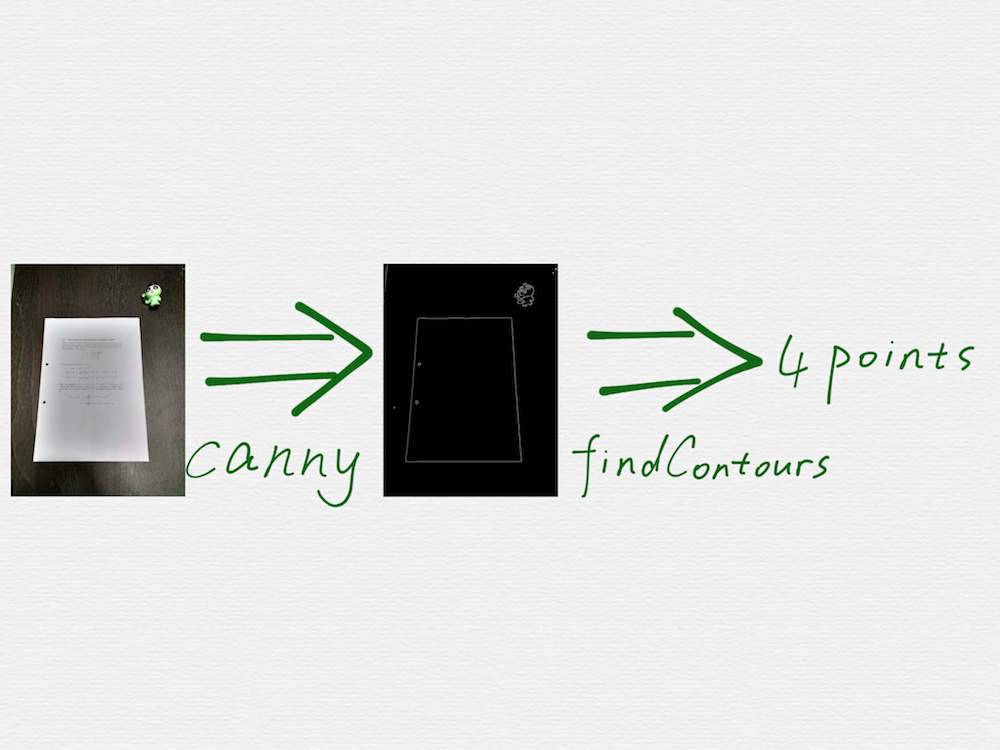
看上去很容易就能实现出来,但是真实情况是,这些教程,仅仅是个 demo 演示而已,用来演示的图片,都是最理想的简单情况,真实的场景图片会比这个复杂的多,会有各种干扰因素,调用 canny 函数得到的边缘检测结果,也会比 demo 中的情况凌乱的多,比如会检测出很多各种长短的线段,或者是文档的边缘线被截断成了好几条短的线段,线段之间还存在距离不等的空隙。另外,findContours 函数也只能检测闭合的多边形的顶点,但是并不能确保这个多边形就是一个合理的矩形。因此在我们的第一版技术方案中,对这两个关键步骤,进行了大量的改进和调优,概括起来就是:
改进 canny 算法的效果,增加额外的步骤,得到效果更好的边缘检测图
针对 canny 步骤得到的边缘图,建立一套数学算法,从边缘图中寻找出一个合理的矩形区域
.
2、传统技术方案的难度和局限性
canny 算法的检测效果,依赖于几个阈值参数,这些阈值参数的选择,通常都是人为设置的经验值,在改进的过程中,引入额外的步骤后,通常又会引入一些新的阈值参数,同样,也是依赖于调试结果设置的经验值。整体来看,这些阈值参数的个数,不能特别的多,因为一旦太多了,就很难依赖经验值进行设置,另外,虽然有这些阈值参数,但是最终的参数只是一组或少数几组固定的组合,所以算法的鲁棒性又会打折扣,很容易遇到边缘检测效果不理想的场景
在边缘图上建立的数学模型很复杂,代码实现难度大,而且也会遇到算法无能为力的场景
下面这张图表,能够很好的说明上面列出的这两个问题:

这张图表的第一列是输入的 image,最后的三列(先不用看这张图表的第二列),是用三组不同阈值参数调用 canny 函数和额外的函数后得到的输出 image,可以看到,边缘检测的效果,并不总是很理想的,有些场景中,矩形的边,出现了很严重的断裂,有些边,甚至被完全擦除掉了,而另一些场景中,又会检测出很多干扰性质的长短边。可想而知,想用一个数学模型,适应这么不规则的边缘图,会是多么困难的一件事情。
.
3、尝试方案——YOLO&FCN
人脸对齐
首先想到的,就是仿照人脸对齐(face alignment)的思路,构建一个端到端(end-to-end)的网络,直接回归拟合,也就是让这个神经网络直接输出 4 个顶点的坐标,但是,经过尝试后发现,根本拟合不出来。后来仔细琢磨了一下,觉得不能直接拟合也是对的,因为:
除了分类(classification)问题之外,所有的需求看上去都像是一个回归(regression)问题,如果回归是万能的,学术界为啥还要去搞其他各种各样的网络模型
face alignment 之所以可以用回归网络得到很好的拟合效果,是因为在输入 image 上先做了 bounding box 检测,缩小了人脸图像范围后,才做的 regression
人脸上的关键特征点,具有特别明显的统计学特征,所以 regression 可以发挥作用
在需要更高检测精度的场景中,其实也是用到了更复杂的网络模型来解决 face alignment 问题的
YOLO && FCN
后来还尝试过用 YOLO 网络做 Object Detection,用 FCN 网络做像素级的 Semantic Segmentation,但是结果都很不理想,比如:
达不到文档检测功能想要的精确度
网络结构复杂,运算量大,在手机上无法做到实时检测
.
4、HED(Holistically-Nested Edge Detection) 网络
边缘检测这种需求,在图像处理领域里面,通常叫做 Edge Detection 或 Contour Detection,按照这个思路,找到了 Holistically-Nested Edge Detection 网络模型。
HED 网络模型是在 VGG16 网络结构的基础上设计出来的,所以有必要先看看 VGG16。
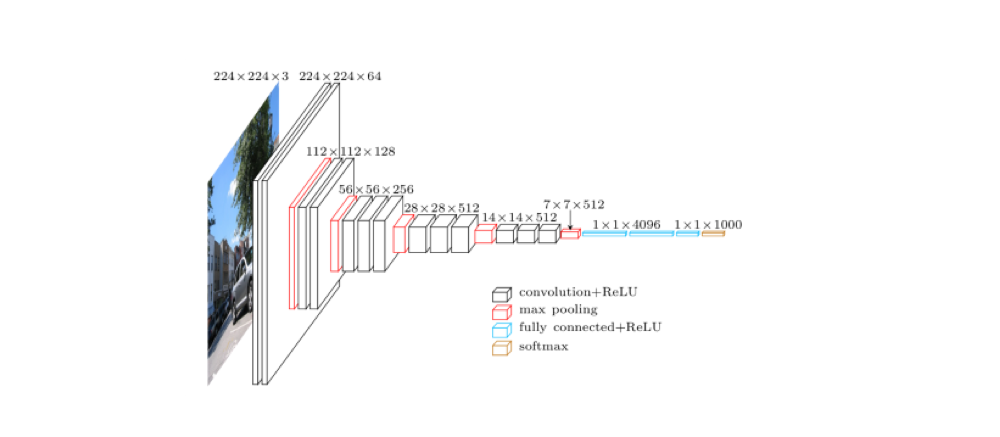
上图是 VGG16 的原理图,为了方便从 VGG16 过渡到 HED,我们先把 VGG16 变成下面这种示意图:
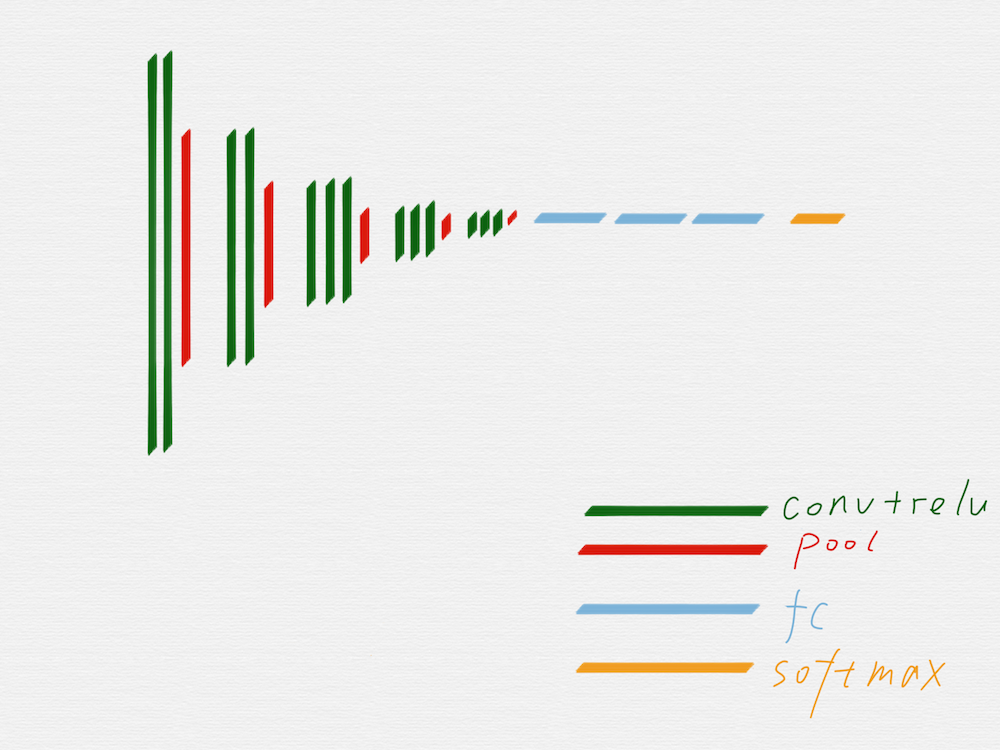
去掉不需要的部分后,就得到上图这样的网络结构,因为有池化层的作用,从第二组开始,每一组的输入 image 的长宽值,都是前一组的输入 image 的长宽值的一半。
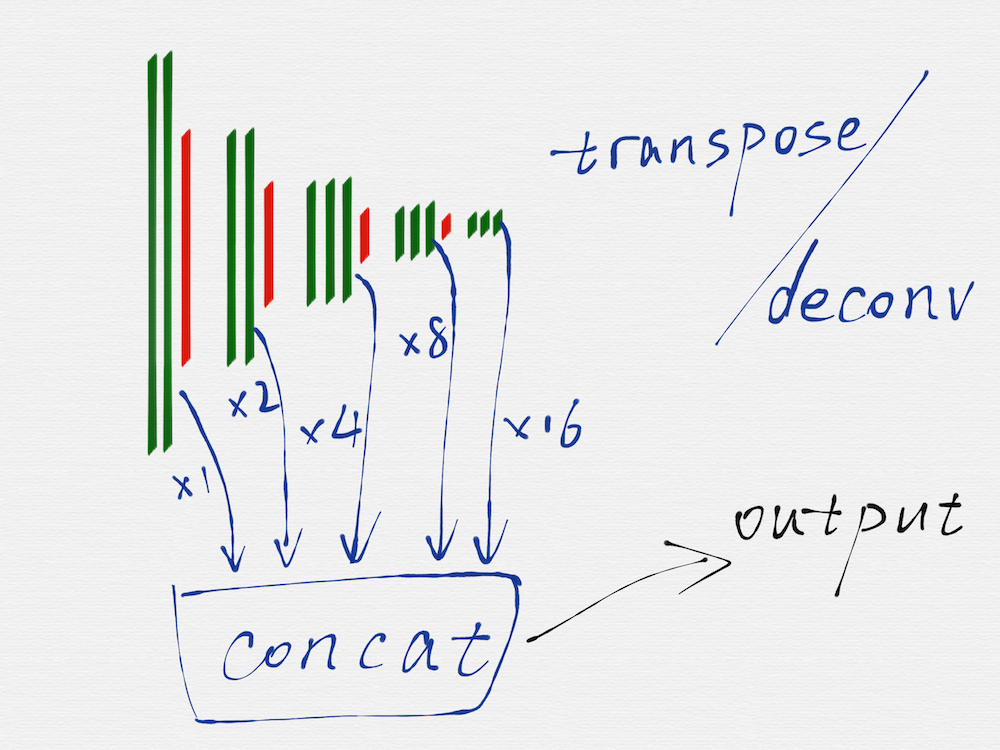
HED 网络是一种多尺度多融合(multi-scale and multi-level feature learning)的网络结构,所谓的多尺度,就是如上图所示,把 VGG16 的每一组的最后一个卷积层(绿色部分)的输出取出来,因为每一组得到的 image 的长宽尺寸是不一样的,所以这里还需要用转置卷积(transposed convolution)/反卷积(deconv)对每一组得到的 image 再做一遍运算,从效果上看,相当于把第二至五组得到的 image 的长宽尺寸分别扩大 2 至 16 倍,这样在每个尺度(VGG16 的每一组就是一个尺度)上得到的 image,都是相同的大小了。
其中还有:基于 TensorFlow 编写的 HED 网络结构代码
.
5、OpenCV 算法实现
虽然用神经网络技术,已经得到了一个比 canny 算法更好的边缘检测效果,但是,神经网络也并不是万能的,干扰是仍然存在的,所以,第二个步骤中的数学模型算法,仍然是需要的,只不过因为第一个步骤中的边缘检测有了大幅度改善,所以第二个步骤中的算法,得到了适当的简化,而且算法整体的适应性也更强了。
这部分的算法如下图所示:
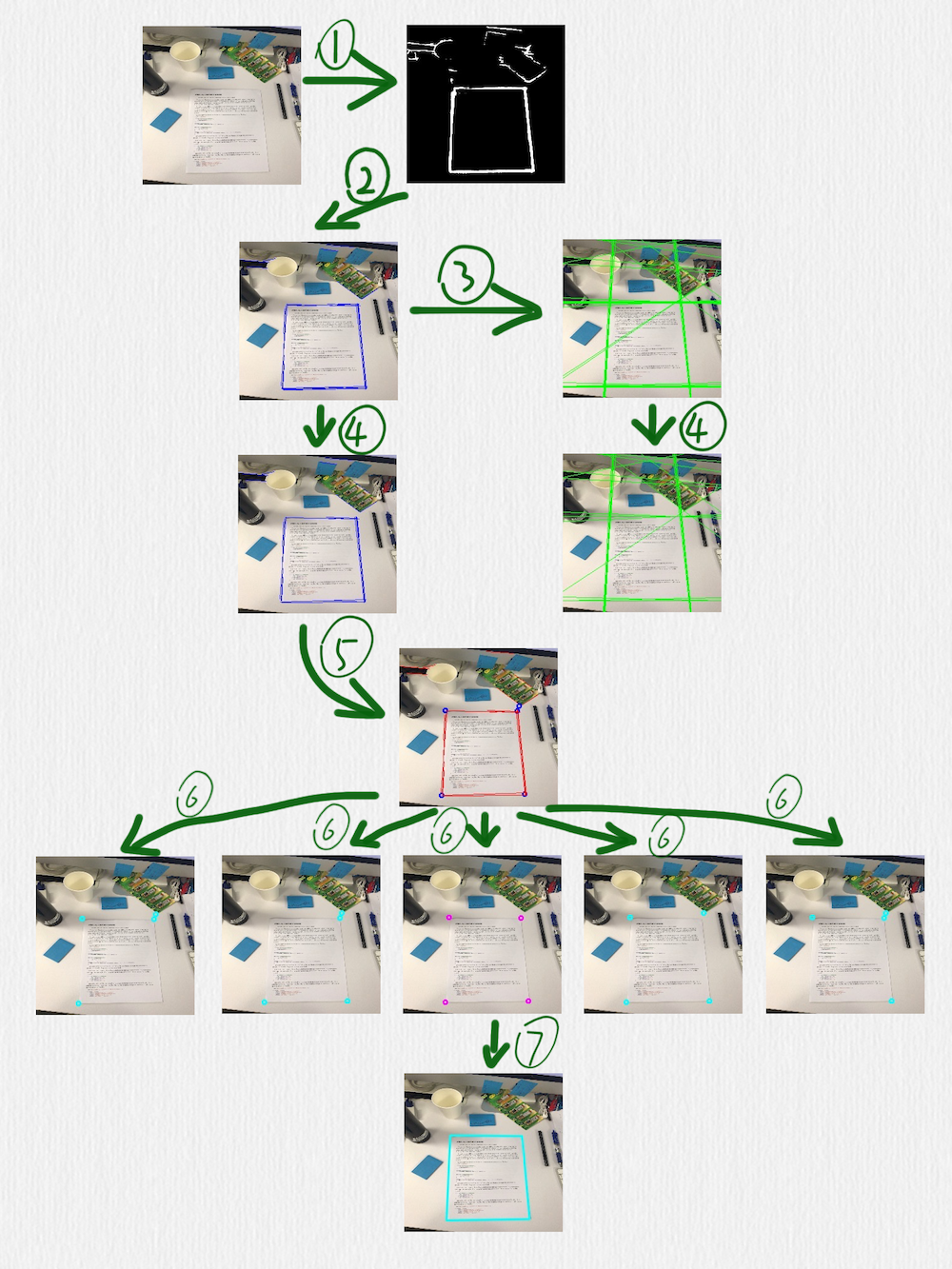
按照编号顺序,几个关键步骤做了下面这些事情:
用 HED 网络检测边缘,可以看到,这里得到的边缘线还是存在一些干扰的
在前一步得到的图像上,使用 HoughLinesP 函数检测线段(蓝色线段)
把前一步得到的线段延长成直线(绿色直线)
在第二步中检测到的线段,有一些是很接近的,或者有些短线段是可以连接成一条更长的线段的,所以可以采用一些策略把它们合并到一起,这个时候,就要借助第三步中得到的直线。定义一种策略判断两条直线是否相等,当遇到相等的两条直线时,把这两条直线各自对应的线段再合并或连接成一条线段。这一步完成后,后面的步骤就只需要蓝色的线段而不需要绿色的直线了
根据第四步得到的线段,计算它们之间的交叉点,临近的交叉点也可以合并,同时,把每一个交叉点和产生这个交叉点的线段也要关联在一起(每一个蓝色的点,都有一组红色的线段和它关联)
对于第五步得到的所有交叉点,每次取出其中的 4 个,判断这 4 个点组成的四边形是否是一个合理的矩形(有透视变换效果的矩形),除了常规的判断策略,比如角度、边长的比值之外,还有一个判断条件就是每条边是否可以和第五步中得到的对应的点的关联线段重合,如果不能重合,则这个四边形就不太可能是我们期望检测出来的矩形
经过第六步的过滤后,如果得到了多个四边形,可以再使用一个简单的过滤策略,比如排序找出周长或面积最大的矩形
.
二、训练集获取(大量合成数据 + 少量真实数据)
HED 论文里使用的训练数据集,是针对通用的边缘检测目的的,什么形状的边缘都有,比如下面这种:

用这份数据训练出来的模型,在做文档扫描的时候,检测出来的边缘效果并不理想,而且这份训练数据集的样本数量也很小,只有一百多张图片(因为这种图片的人工标注成本太高了),这也会影响模型的质量。
现在的需求里,要检测的是具有一定透视和旋转变换效果的矩形区域,所以可以大胆的猜测,如果准备一批针对性更强的训练样本,应该是可以得到更好的边缘检测效果的。
借助第一版技术方案收集回来的真实场景图片,我们开发了一套简单的标注工具,人工标注了 1200 张图片(标注这 1200 张图片的时间成本也很高),但是这 1200 多张图片仍然有很多问题,比如对于神经网络来说,1200 个训练样本其实还是不够的,另外,这些图片覆盖的场景其实也比较少,有些图片的相似度比较高,这样的数据放到神经网络里训练,泛化的效果并不好。
所以,还采用技术手段,合成了80000多张训练样本图片。

如上图所示,一张背景图和一张前景图,可以合成出一对训练样本数据。在合成图片的过程中,用到了下面这些技术和技巧:
在前景图上添加旋转、平移、透视变换
对背景图进行了随机的裁剪
通过试验对比,生成合适宽度的边缘线
OpenCV 不支持透明图层之间的旋转和透视变换操作,只能使用最低精度的插值算法,为了改善这一点,后续改成了使用 iOS 模拟器,通过 CALayer 上的操作来合成图片
在不断改进训练样本的过程中,还根据真实样本图片的统计情况和各种途径的反馈信息,刻意模拟了一些更复杂的样本场景,比如凌乱的背景环境、直线边缘干扰等等
经过不断的调整和优化,最终才训练出一个满意的模型,可以再次通过下面这张图表中的第二列看一下神经网络模型的边缘检测效果:
边缘检测︱基于 HED网络TensorFlow 和 OpenCV 实现图片边缘检测的更多相关文章
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- 基于LeNet网络的中文验证码识别
基于LeNet网络的中文验证码识别 由于公司需要进行了中文验证码的图片识别开发,最近一段时间刚忙完上线,好不容易闲下来就继上篇<基于Windows10 x64+visual Studio2013 ...
- 基于ffmpeg网络播放器的教程与总结
基于ffmpeg网络播放器的教程与总结 一. 概述 为了解决在线无广告播放youku网上的视频.(youku把每个视频切换成若干个小视频). 视频资源解析可以从www.flvcd. ...
- TensorFlow与OpenCV,读取图片,进行简单操作并显示
TensorFlow与OpenCV,读取图片,进行简单操作并显示 1 OpenCV读入图片,使用tf.Variable初始化为tensor,加载到tensorflow对图片进行转置操作,然后openc ...
- Ubuntu中搭建强化学习平台(使用anaconda管理Python并安装tensorflow、opencv)
首先介绍一下anaconda,annoconda是一个开源的Python发行版本,里面集成了python.conda等多个科学包及其依赖项.安装完成之后,就可以使用conda版本管理器进行管理,可以让 ...
- 基于UML网络教学管理平台模型的搭建
一.基本信息 标题:基于UML网络教学管理平台模型的搭建 时间:2013 出版源:网络安全技术与应用 领域分类:UML:网络教学管理平台:模型 二.研究背景 问题定义:网络教学管理平台模型的搭建 难点 ...
- 基于Docker的TensorFlow机器学习框架搭建和实例源码解读
概述:基于Docker的TensorFlow机器学习框架搭建和实例源码解读,TensorFlow作为最火热的机器学习框架之一,Docker是的容器,可以很好的结合起来,为机器学习或者科研人员提供便捷的 ...
- 基于Socket网络编程
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/a2011480169/article/details/73602708 博客核心内容: 1.Sock ...
- Ubuntu 基于Docker的TensorFlow 环境搭建
基于Docker的TensorFlow 环境搭建 基于(ubuntu 16.04LTS/ubuntu 14.04LTS) 一.docker环境安装 1)更新.安装依赖包 sudo apt-get up ...
随机推荐
- Soap 教程
SOAP 构建模块 一条 SOAP 消息就是一个普通的 XML 文档,包含下列元素: · 必需的 Envelope 元素,可把此 XML 文档标识为一条 SOAP 消息 · 可选的 Header 元素 ...
- python网络编程——SocketServer/Twisted/paramiko模块
在之前博客C/S架构的网络编程中,IO多路复用是将多个IO操作复用到1个服务端进程中进行处理,即无论有多少个客户端进行连接请求,服务端始终只有1个进程对客户端进行响应,这样的好处是节省了系统开销(se ...
- linux比较两个文件的不同(6/21)
cmp 命令:比较任意两个类型的文件,且吧结果输出到标准输出,默认文件相同不输出,不同的文件输出差异 必要参数 -c 显示不同的信息-l 列出所有的不同信息-s 错误信息不提示 选择参数 -i< ...
- CString和char互转,十六进制的BYTE转CString
CString转char: CString m_Readcard; char ReaderName[22]; strcpy((char*)&ReaderName,(LPCTSTR)m_Read ...
- Android平台利用OpenCL框架实现并行开发初试
http://www.cnblogs.com/lifan3a/articles/4607659.html 在我们熟知的桌面平台,GPU得到了极为广泛的应用,小到各种电子游戏,大到高性能计算,多核心.高 ...
- Spring 之定义切面尝试(基于注解)
[Spring 之定义切面尝试] 1.标记为深红色的依赖包是必须的 <dependency> <groupId>org.springframework</groupId& ...
- this()必须放在构造方法的第一条
public class A { String name; int age; public A() { this("Jack",23); } public A(String nam ...
- tomcat常用配置详解和优化方法
tomcat常用配置详解和优化方法 参考: http://blog.csdn.net/zj52hm/article/details/51980194 http://blog.csdn.net/wuli ...
- Registering Components-->Autofac registration(include constructor injection)
https://autofaccn.readthedocs.io/en/latest/register/registration.html Registration Concepts (有4种方式来 ...
- Extracting info from VCF files
R, Bioconductor filterVcf: Extract Variants of Interest from a Large VCF File (Paul Shannon) We demo ...