spark内存管理分析
前言
下面的分析基于对spark2.1.0版本的分析,对于1.x的版本可以有区别。
内存配置
|
key |
默认 |
解释 |
|
spark.memory.fraction |
0.6 |
spark可以直接使用的内存大小系数 |
|
spark.memory.storageFraction |
0.5 |
spark存储可以直接使用的内存大小系数 |
|
spark.memory.offHeap.enabled |
false |
是否开启spark使用jvm内存之外的内存 |
|
spark.memory.offHeap.size |
0 |
jvm之外,spark可以用多少内存 |
内存划分策略
如图1,spark在内存上划分出4部分空间,分别为预留空间(默认300M),Spark执行空间(Execution),Spark存储空间(Storage)和用户使用空间。
下面用一个实际案例描述一下这4部分空间:
假设给executor分配1G,也就是1024MB,Spark会留出300MB,这300MB不能作为缓存或者rdd相关操作使用,可以理解成防止OOM的一种策略。当`spark.memory.fraction`为0.6时(默认),(1024 - 300) * 0.6 = 434MB,这434MB就是Spark用于rdd缓存或者rdd执行的内存大小,也就是Spark可以随意使用的max memory。剩下的资源是给用户留下的内存大小。而`spark.memory.storageFraction`则是声明了可以用于存储的大小,默认是0.5,也就是说Spark任务中,存储Storage和执行Execution各占50%内存空间也就是434*0.5=217MB。
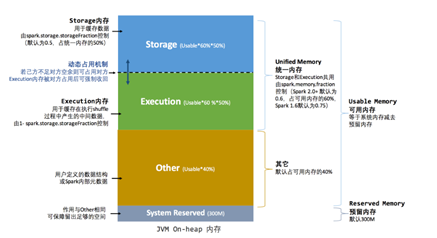
图1
在实际内存申请过程中,Spark为Storage和Execution各自维护了一个内存资源池,用于控制和协调内存资源的使用,在钨丝计划的路线下,Spark支持onHeap和offHeap两种内存分配机制,但是分配流程是一致的。参考图2,在Execution的内存池资源充足的情况下,直接获取需要的Execution资源,而在不足情况下,允许Execution借用Storage的内存资源,首先判断Storage资源池剩余的资源是否满足要去,如果剩余也不足,那么尝试将已经存在的block(block是rdd缓存或者shuflle的存储单元)剔除,直到获取到充足的内存,如果资源依然不够Execution,那么该Execution会阻塞,知道获取到全部资源。 而反过来需要获取Storage的内存资源,也是先检查Execution内存池是否有剩余,如果依旧不足,呢就去尝试将已经存在的block剔除,直到获取到充足的内存(和Execution调用的是一个函数evictBlocksToFreeSpace),最后获取不到足够的资源就直接返回失败。这相比Execution是有区别的,Storage不够可以spill,而Execution资源不够就必须阻塞等待。

图2
内存划分粒度
Spark对于内存的控制的最小粒度是Task,一个executor也就是一个JVM维护一个Execution内存池和Storage内存池,也就是说一个executor能同时执行多少个task除了收到cpu的影响,还受到竞争内存资源的影响,其实上面已经讲了很多了,下面再详细分析一下task如何竞争内存资源。
task获取Execution内存
task获取Execution的内存也是相对公平的控制,将内存控制在task平均使用内存和task平均使用内存一半之间。相关代码如下:
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
// How much we can grant this task; keep its share within 0 <= X <= 1 /
numActiveTasks
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
// Only give it as much memory as is free, which might be none if it reached 1
/ numTasks
val toGrant = math.min(maxToGrant, memoryFree)
当获取不到内存时,Spark会让请求的task等待,直到有其他task释放资源,然后该task再去抢占资源。
task获取Storage内存
storage内存的获取就相对复杂一点,因为这受到rdd的cache,persist相关操作的影响。因此和BlockManager和MemStore有关
如果申请的内存大于storage内存池剩余的内存,那么获取Execution内存池是否有剩余,如果有的话就释放Math.min(executionPool.memoryFree,
numBytes)。在申请内存之前,还做了一件事件,就是去blockManager尝试释放内存,如果缓存的所有内存实例中,某个blockId下的rdd的id是空,并且存储模式相同(都用jvm或者都不用jvm),那么就会将该blockId释放。如果空余资源小于申请的资源,那么就会申请失败。
代码相关类
MemoryManager
UnifiedMemoryManager
MemoryPool
StorageMemoryPool
ExecutionMemoryPool
MemoryStore
spark内存管理分析的更多相关文章
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
- Spark内存管理机制
Spark内存管理机制 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行 ...
- Apache Spark 内存管理详解(转载)
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- spark内存管理器--MemoryManager源码解析
MemoryManager内存管理器 内存管理器可以说是spark内核中最重要的基础模块之一,shuffle时的排序,rdd缓存,展开内存,广播变量,Task运行结果的存储等等,凡是需要使用内存的地方 ...
- spark内存管理详解
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- 【Spark-core学习之八】 SparkShuffle & Spark内存管理
[Spark-core学习之八] SparkShuffle & Spark内存管理环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 ...
- Spark内存管理之钨丝计划
Spark内存管理之钨丝计划 1. 钨丝计划的产生的原因 2. 钨丝计划内幕详解 一:“钨丝计划”产生的本质原因 1, Spark作为一个一体化多元化的(大)数据处理通用平台,性能一直是其根本性的追 ...
- Spark(四十六):Spark 内存管理之—OFF_HEAP
存储级别简介 Spark中RDD提供了多种存储级别,除去使用内存,磁盘等,还有一种是OFF_HEAP,称之为 使用JVM堆外内存 https://github.com/apache/spark/blo ...
- Spark 内存管理
Spark 内存管理 Spark 执行应用程序时, 会启动 Driver 和 Executor 两种 JVM 进程 Driver 负责创建 SparkContext 上下文, 提交任务, task的分 ...
随机推荐
- Android Fingerprint系列之google原生界面
ENV: Anroid M 6.0 1. 录入指纹引导界面 2.指纹要求先设置密码或验证密码界面(已经添加安全密码) 3.引导用户寻找指纹传感器 4.录入指纹界面 5.指纹录入结束界面
- 学习POC框架pocsuite--编写hellowordPOC
在这里,首先向安全圈最大的娱乐公司,某404致敬. 参考博文 https://www.seebug.org/help/dev 向seebug平台及该文原作者致敬,虽然并不知道是谁 长话短说其实,可自由 ...
- maven项目使用SOLR时报 previously initiated loading for a different type with name "javax/servlet/http/HttpServletRequest" 错的解决方法
环境:Apache solr4.8,maven3,IntellijIDEA 想在项目中使用solr 在pom.xml文件中添加了solr的依赖 solr-core,solrj 和solr-dataim ...
- JS拖拽事件
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- nginx跟tp5无法加载控制器
二. 另外502 bad gateway错误,可能是有PHP中的php-fpm.conf里 “ listen fastcgi_pass /tmp/php-cgi.sock ”跟nginx的conf文 ...
- 170615、spring不同数据库数据源动态切换
spring mvc+mybatis+多数据源切换 选取Oracle,MySQL作为例子切换数据源.mysql为默认数据源,在测试的action中,进行mysql和oracle的动态切换. 1.web ...
- RPN网络
Region Proposal Network RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的sliding window(论文中n=3)生成一个长度为256(ZF网络 ...
- 【python】BeautifulSoup的应用
from bs4 import BeautifulSoup#下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档): html_doc = ...
- java-mybaits-009-mybatis-spring-使用,SqlSessionFactoryBean、事务
一.版本限制 参看地址:http://www.mybatis.org/spring/ 二.使用入门 2.1.pom <dependency> <groupId>org.myba ...
- 《TP5.0学习笔记---模型篇》
https://blog.csdn.net/self_realian/article/details/78596261 一.什么是模型 为什么我们要在项目中使用模型,其实我们知道,我们可以直接在控制器 ...