linux及安全第六周总结——20135227黄晓妍
总结部分:
操作系统内核三大功能:
进程管理,内存管理,文件系统
最核心的是进程管理
为了管理,首先要对每一个进程进行描述。进程描述符提供了所有内核需要了解的信息。
进程控制模块:task_struct(抽象task_struct的简化图)

next_task,prev_task进程链表的管理
tty_struct控制台
fs_struct文件系统描述
file_struct打开的文件描述符
mm_struct内存管理的描述
signal_struct信号的描述
Linux-3.18.6/include/linux/sched.h里的代码

1235代码state进程运行状态
stack指定进程的内核堆栈
flags每个进程的标识符

1245CONFIG SMP条件编译,多处理器时使用到的。

1251on_rq运行队列

1295list_head tasks进程链表(双向链表)
linux进程的状态和操作系统原理的描述进程状态有所不同,比如就绪状态和运行状态都是TASK_RUNNING。(这个表示它是可运行的,但是实际上有没有在运行取决于它是否占有CPU)

1330进程标识符pid

1349进程的父子关系

1360pid_link pids[PIDTYPE_MAX]进程的哈希表
Linux-3.18.6/arch/x86/include/asm/processor.h
thread_struct(很重要)


进程的创建概括以及fork()一个进程
Cpu_idle启动两个线程:(0号进程是所有线程的祖先)
Kernel_init用户态的进程启动,所有用户态进程的祖先(1号进程是所有进程的祖先)
Kthreadd所有线程的祖先
在shell命令行创建进程的本质一样:先复制一份进程描述符,0号进程是手工写进代码的,1号进程复制0号的pcb,然后根据1号进程的需要把它的pid等等信息修改 掉,再加载一个init可执行程序。
进程是如何创建:
先看怎么在用户态创建一个子进程
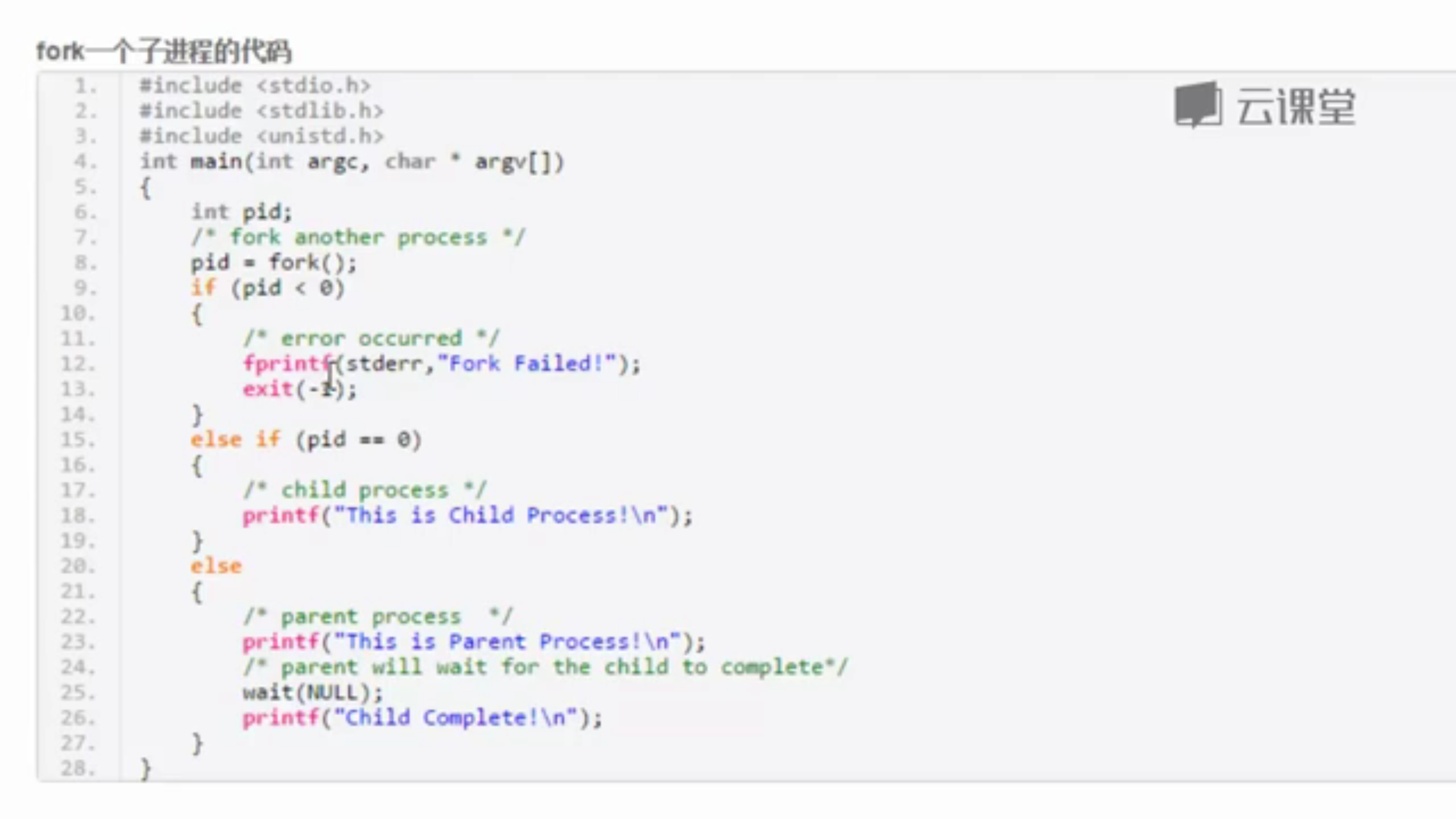
Pid==0是下面两个模块都会被执行,fork()系统调用在父进程子进程各返回一次,父进程中返回0,子进程中返回子进程的pid
理解进程创建过程复杂代码的方法:
系统调用:用户态int0x80(由于是陷入进入内核的,所以机器自动保存与转换堆栈;压入用户ss,压入用户esp,压入EFLAGS,压入cs,压入eip)
中断指令跳转到内和空间sysstem_call(压入eax,把传递参数的寄存器全部压栈)执行结束后RESTORE_ALL(弹栈传递参数的寄存器,弹栈eax,iret弹栈 int0x80压栈的东西)
Fork()的也是一个系统调用,它的过程图

子进程复制了父进程的所有信息,然后做适当修改,它也会调度执行。当它被CPU调度的时候从哪里开始执行呢?子进程在内核里执行,在内核处理程序从哪里开始 执行的?与mykernel类似。
fork,vfork,clone三个系统调用都是通过调用do_fork来创建创建一个新的进程。
先我们设想,它应该如何创建一个进程,我们画一个框架,然后再通过代码求证,再对我们的框架进行修正。
我们的框架:
1.创建新进程都是通过复制父进程的信息。
2.创建新进程的过程中需要做哪些事情:
复制pcb
还需要修改复制的父进程的pcb
还需要分配新的内核堆栈
子进程需要从fork返回到用户态,那么它内核堆栈也需要从父进程中拷贝一些过来,不然不能返回
还有thread.sp(调度到子进程时的内核栈顶)和thread.ip(调度到子进程的第一条指令地址)
浏览创建进程的相关关键代码

Linux-3.18.6/kernel/fork.c

1632copy_process创建一个进程的主要代码

1240dup_task_struct复制pcb(看具体怎么复制)


320arch_dup_task_struct(tsk,orig)执行复制当前进程

293*dst=*src数据结构的指针的值复制
316alloc_thread_info_node(tsk,node),分配内核空间堆栈的作用和thread_info合在一起的集合体
153实际上是创建了一个一定大小的页面。一部分存放alloc_thread_info,一部分存放堆栈

335setup_thread_stack


1240p=dup_task_struct(current);复制子进程的pcb

1396 copy_thread
Linux-3.18.6/arch/x86/kernel/process_32.c
135*childregs=task_pt_regs(p);
159*childregs=*current_pt_regs();将父进程的现在的状态信息赋值给子进程(拷贝内核堆栈诗句和指定新进程的第一条指令)
164p.thread.ip通过ret_from_fork得到。
创建的新进程是从哪里开始执行的?
Linux-3.18.6/arch/x86/include/asm/ptrace.h
Pt_regs:系统调用压栈的内容(SAVE_ALL的全部内容)

Linux-3.18.6/arch/x86/kernel/entry_32.s
290entry(ret_from_fork)新进程是从这里开始执行的

505syscall exit内核堆栈返回到系统调用以前的状态继续执行

实验部分:
使用gdb跟踪调试创建新进程的过程
cd LinuxKernel
rm menu –rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c//覆盖test_fork.c
make rootfs

看到增加了一个fork


使用gdb跟踪调试内核
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
# 关于-s和-S选项的说明:
# -S freeze CPU at startup (use ’c’ to start execution)
# -s shorthand for -gdb tcp::1234 若不想使用1234端口,则可以使用-gdb tcp:xxxx来取代-s选项
Gdb
(gdb)file linux-3.18.6/vmlinux # 在gdb界面中targe remote之前加载符号表
(gdb)target remote:1234 # 建立gdb和gdbserver之间的连接,按c 让qemu上的Linux继续运行


b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
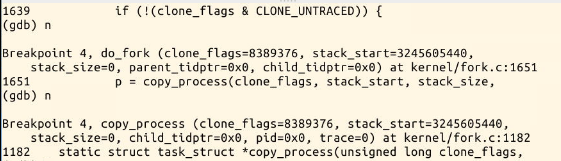
copy_process

dup_task_struct

将父进程的现在的状态信息赋值给子进程(拷贝内核堆栈诗句和指定新进程的第一条指令)

将子进程的栈顶保存

线程的pid保存

直到syscall_exit就跟踪不到了。
思考部分:
理解创建一个新进程如何创建和修改task_struct数据结构
一般通过系统调用来创建新的进程。fork(),vfork(),clone()都是通过调用do_fork来创建新进程的。要通过复制父进程的信息pcb(task_struct),然后给新 的子进程分配内核堆栈,再通过copy_process来修改子进程的task_struct.
特别关注新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?即执行起点与内核堆栈如何保证一致。

从ret_from_thread开始执行。子进程被创建以后是在内核运行的,因为从这里开始复制父进程的task_struct,分配内核堆栈,创建进程也是一种系统调用,在内核堆栈中,执行int0x80,保存现场,来保证执行起点和内核堆栈的一致性。
linux及安全第六周总结——20135227黄晓妍的更多相关文章
- linux及安全第八周总结——20135227黄晓妍
实验部分 实验环境搭建 -rm menu -rf git clone https://github.com/megnning/menu.git cd menu make rootfs qemu -ke ...
- linux及安全第七周总结——20135227黄晓妍
实验部分 首先clone最新的menu 我们可以看到,test.c里多了一个exec的功能,它的代码和fork基本一致,多了一项加载hello rootfs也有一些变化 执行一下exec 让我们启动一 ...
- linux及安全第五周总结——20135227黄晓妍
(注意:本文总结备份中有较多我手写笔记的图片,其中重要的部分打出来了.本文对分析system_call对应的汇编代码的工作过程,系统调用处理过程”的理解,以及流程图都写在实验部分.) 实验部分 使用g ...
- linux及安全第三周总结——20135227黄晓妍
总结部分: Linux内核源代码: Arch 支持不同cpu的源代码:主要关注x86 Init 内核启动的相关代码:主要关注main.c,整个Linux内核启动代码start_kernel函数 K ...
- linux安全第一周总结——20135227黄晓妍
实验部分: 我将源代码做了修改,将其中一个数字修改为我学号27 2.在实验楼环境下将其保存为text.c并将其编译,得到text.s 3.将.开头的多余的语句删去了之后,我得到了32位环境的汇编代码 ...
- linux及安全第二周总结——20135227黄晓妍
实验部分: 首先运行结果截图 代码分析: Mypcb.h /* * linux/mykernel/mypcb.h * * Kernel internal PCB types * * Copyri ...
- linux及安全期中总结——20135227黄晓妍
Linux及安全期中总结 黄晓妍 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ...
- Linux基础入门学习笔记20135227黄晓妍
学习计时:共24小时 读书:1小时 代码:8小时 作业:3小时 博客:12小时 一.学习目标 1. 能够独立安装Linux操作系统 2. 能够熟练使用Linux系统的基本命令 3. 熟练使用L ...
- linux及安全《Linux内核设计与实现》第四章——20135227黄晓妍
第四章 进程调度 进程调度程序是一个内核子系统 分配有限的处理器时间和资源 最大限度利用时间的原则(只要有可执行的进程,那么总会有进程执行) 基本工作:从一组处于等待(阻塞)状态的可执行进程中选择一个 ...
随机推荐
- 报错 ERROR in static/js/vendor.b3f56e9e0cd56988d890.js from UglifyJs
开发vux项目在引入 // 表单验证组件-start import zh_CN from 'vee-validate/dist/locale/zh_CN' import Validator from ...
- 高中生的IT之路-1.5西餐厅服务生
之所以说漫长的求职,是因为培训结束后半年左右没有找到工作. 每次面试结束后,得到的都是“回去等消息”,然后就杳无音信了.一次次的面试,一次次的失败,一次次查找失败的原因.总结来看主要有两点:一是没有工 ...
- oracle数据库实例状态
1.已启动/不装载(NOMOUNT).启动实例,但不装载数据库. 该模式用于重新创建控制文件,对控制文件进行恢复或重新创建数据库.2.已装载(MOUNT).装载数据库,但不打开数据库. 该模式用于更改 ...
- Oracle数据类型char与varchar的对比
使用scott用户连接数据库 新建一个表 create table stu01(name char(32)); 插入一条数据 insert into stu01 values('liuyueming' ...
- php中 const 与define()的区别 ,选择
来自: http://stackoverflow.com/questions/2447791/define-vs-const 相同点: 两者都可以定义常量 const FOO = 'BAR'; def ...
- 知乎live 我的读书经验 总结
https://www.zhihu.com/lives/757587093366009856/messages 碎片化阅读没有意义, 捡硬币捡成富翁 kindle不能全文检索 短篇文章的阅读是否有 ...
- os模块os.walk() 方法和os.path.join()的简单使用
os.walk: http://www.runoob.com/python/os-walk.html os.path.join: https://blog.csdn.net/zmdzbzbhs ...
- UVA 624 ---CD 01背包路径输出
DescriptionCD You have a long drive by car ahead. You have a tape recorder, but unfortunately your b ...
- (2.12)Mysql之SQL基础——存储过程条件定义与错误处理
转自:博客园桦仔 5.存储过程条件定义与错误处理 -- (1)定义 [1]条件定义:declare condition_name condition for condition_value;[2]错误 ...
- mysql 约束条件 auto_increment 自动增长起始值 布长 起始偏移量
我们指定一个字段为自动增长,他默认从1开始自动增长,默认值为1,每次增长为1,步长为1 模糊查询 like % 代表任意个数字符 任意字符长度 查看mysql正在使用变量 show variables ...