谈谈你对Java异常处理机制的理解
先谈谈我的理解:异常处理机制可以说是让我们编写的程序运行起来更加的健壮,无论是在程序调试、运行期间发生的异常情况的捕获,都提供的有效的补救动作,任何业务逻辑都会存在异常情况,这时只需要记录这些异常情况,抛出异常,绝不能生吞异常,不要再finally中处理返回值。
先丢个问题:请对比 Exception 和 Error,另外,运行时异常与一般异常有什么区别?
经典回答
Exception 和 Error 都是继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
Exception 和 Error 体现了 Java 平台设计者对不同异常情况的分类。
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
Exception 又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。前面我介绍的不可查的 Error,是 Throwable 不是 Exception。
不检查异常就是所谓的运行时异常,类似 NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
分析
分析 Exception 和 Error 的区别,是从概念角度考察了 Java 处理机制。总的来说,还处于理解的层面。
我们在日常编程中,如何处理好异常是比较考验功底的,我觉得需要掌握两个方面。
第一,理解 Throwable、Exception、Error 的设计和分类。比如,掌握那些应用最为广泛的子类,以及如何自定义异常等。
你了解Error、Exception或者RuntimeException?
画了一个简单的类图,并列出来典型例子,可以给你作为参考,至少做到基本心里有数。
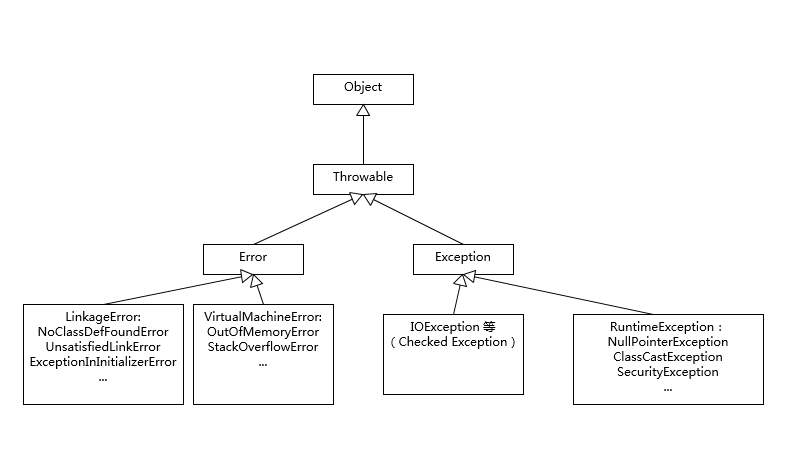
这里也可以思考下:NoClassDefFoundError 和 ClassNotFoundException 有什么区别?
第二,理解 Java 语言中操作 Throwable 的元素和实践。掌握最基本的语法是必须的,如 try-catch-finally 块,throw、throws 关键字等。与此同时,也要懂得如何处理典型场景。
异常处理代码比较繁琐,比如我们需要写很多千篇一律的捕获代码,或者在 finally 里面做一些资源回收工作。随着 Java 语言的发展,引入了一些更加便利的特性,比如 try-with-resources 和 multiple catch,具体可以参考下面的代码段。在编译时期,会自动生成相应的处理逻辑,比如,自动按照约定俗成 close 那些扩展了 AutoCloseable 或者 Closeable 的对象。
try (BufferedReader br = new BufferedReader(…);
BufferedWriter writer = new BufferedWriter(…)) {// Try-with-resources
// do something
catch ( IOException | XEception e) {// Multiple catch
// Handle it
}
知识扩展
前面谈的大多是概念性的东西,下面我来谈些实践中的选择,我会结合一些代码用例进行分析。
先开看第一个吧,下面的代码反映了异常处理中哪些不当之处?
try {
// 业务代码
// …
Thread.sleep(1000L);
} catch (Exception e) {
// Ignore it
}
这段代码作为一段实验代码,它是没有任何问题的,但是在产品代码中,通常都不允许这样处理。你先思考一下这是为什么呢?
我们先来看看[printStackTrace()][1]尤其是对于分布式系统,如果发生异常,但是无法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。所以,最好使用产品日志,详细地输出到日志系统里。的文档,开头就是“Prints this throwable and its backtrace to the standard error stream”。问题就在这里,在稍微复杂一点的生产系统中,标准出错(STERR)不是个合适的输出选项,因为你很难判断出到底输出到哪里去了。
尤其是对于分布式系统,如果发生异常,但是无法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。所以,最好使用产品日志,详细地输出到日志系统里。
我们接下来看下面的代码段,体会一下Throw early, catch late 原则。
public void readPreferences(String fileName){
//...perform operations...
InputStream in = new FileInputStream(fileName);
//...read the preferences file...
}
如果 fileName 是 null,那么程序就会抛出 NullPointerException,但是由于没有第一时间暴露出问题,堆栈信息可能非常令人费解,往往需要相对复杂的定位。这个 NPE 只是作为例子,实际产品代码中,可能是各种情况,比如获取配置失败之类的。在发现问题的时候,第一时间抛出,能够更加清晰地反映问题。
我们可以修改一下,让问题“throw early”,对应的异常信息就非常直观了。
public void readPreferences(String filename) {
Objects. requireNonNull(filename);
//...perform other operations...
InputStream in = new FileInputStream(filename);
//...read the preferences file...
}
至于“catch late”,其实是我们经常苦恼的问题,捕获异常后,需要怎么处理呢?最差的处理方式,就是我前面提到的“生吞异常”,本质上其实是掩盖问题。如果实在不知道如何处理,可以选择保留原有异常的 cause 信息,直接再抛出或者构建新的异常抛出去。在更高层面,因为有了清晰的(业务)逻辑,往往会更清楚合适的处理方式是什么。
有的时候,我们会根据需要自定义异常,这个时候除了保证提供足够的信息,还有两点需要考虑:
是否需要定义成 Checked Exception,因为这种类型设计的初衷更是为了从异常情况恢复,作为异常设计者,我们往往有充足信息进行分类。
在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问题。如果我们看 Java 的标准类库,你可能注意到类似 java.net.ConnectException,出错信息是类似“ Connection refused (Connection refused)”,而不包含具体的机器名、IP、端口等,一个重要考量就是信息安全。类似的情况在日志中也有,比如,用户数据一般是不可以输出到日志里面的。
业界有一种争论(甚至可以算是某种程度的共识),Java 语言的 Checked Exception 也许是个设计错误,反对者列举了几点:
Checked Exception 的假设是我们捕获了异常,然后恢复程序。但是,其实我们大多数情况下,根本就不可能恢复。Checked Exception 的使用,已经大大偏离了最初的设计目的。
Checked Exception 不兼容 functional 编程,如果你写过 Lambda/Stream 代码,相信深有体会。
从性能角度来审视一下 Java 的异常处理机制,这里有两个可能会相对昂贵的地方:
- try-catch 代码段会产生额外的性能开销,或者换个角度说,它往往会影响 JVM 对代码进行优化,所以建议仅捕获有必要的代码段,尽量不要一个大的 try 包住整段的代码;与此同时,利用异常控制代码流程,也不是一个好主意,远比我们通常意义上的条件语句(if/else、switch)要低效。
- Java 每实例化一个 Exception,都会对当时的栈进行快照,这是一个相对比较重的操作。如果发生的非常频繁,这个开销可就不能被忽略了。
所以,对于部分追求极致性能的底层类库,有种方式是尝试创建不进行栈快照的 Exception。这本身也存在争议,因为这样做的假设在于,我创建异常时知道未来是否需要堆栈。问题是,实际上可能吗?小范围或许可能,但是在大规模项目中,这么做可能不是个理智的选择。如果需要堆栈,但又没有收集这些信息,在复杂情况下,尤其是类似微服务这种分布式系统,这会大大增加诊断的难度。
当我们的服务出现反应变慢、吞吐量下降的时候,检查发生最频繁的 Exception 也是一种思路。关于诊断后台变慢的问题,我会在后面的 Java 性能基础模块中系统探讨。
今天,我从一个常见的异常处理概念问题,简单总结了 Java 异常处理的机制。并结合代码,分析了一些普遍认可的最佳实践,以及业界最新的一些异常使用共识。最后,我分析了异常性能开销,希望对你有所帮助。
谈谈你对Java异常处理机制的理解的更多相关文章
- Java异常处理机制 —— 深入理解与开发应用
本文为原创博文,严禁转载,侵权必究! Java异常处理机制在日常开发中应用频繁,其最主要的不外乎几个关键字:try.catch.finally.throw.throws,以及各种各样的Exceptio ...
- 【转】深入理解java异常处理机制
深入理解java异常处理机制 ; int c; for (int i = 2; i >= -2; i--) { c = b / i; System.out.println("i=&qu ...
- JAVA 异常处理机制
主要讲述几点: 一.异常的简介 二.异常处理流程 三.运行时异常和非运行时异常 四.throws和throw关键字 一.异常简介 异常处理是在程序运行之中出现的情况,例如除数为零.异常类(Except ...
- Java 异常处理机制和集合框架
一.实验目的 掌握面向对象程序设计技术 二.实验环境 1.微型计算机一台 2.WINDOWS操作系统,Java SDK,Eclipse开发环境 三.实验内容 1.Java异常处理机制涉及5个关键字:t ...
- java异常处理机制 (转载)
java异常处理机制 本文来自:曹胜欢博客专栏.转载请注明出处:http://blog.csdn.net/csh624366188 异常处理是程序设计中一个非常重要的方面,也是程序设计的一大难点,从C ...
- 如何正确使用Java异常处理机制
文章来源:leaforbook - 如何正确使用Java异常处理机制作者:士别三日 第一节 异常处理概述 第二节 Java异常处理类 2.1 Throwable 2.1.1 Throwable有五种构 ...
- Java异常处理机制及两种异常的区别
java异常处理机制主要依赖于try,catch,finally,throw,throws五个关键字. try 关键字后紧跟一个花括号括起来的代码块,简称try块.同理:下面的也被称为相应的块. ...
- 谈谈我对Java中CallBack的理解
谈谈我对Java中CallBack的理解 http://www.cnblogs.com/codingmyworld/archive/2011/07/22/2113514.html CallBack是回 ...
- Java类加载机制的理解
算上大学,尽管接触Java已经有4年时间并对基本的API算得上熟练应用,但是依旧觉得自己对于Java的特性依然是一知半解.要成为优秀的Java开发人员,需要深入了解Java平台的工作方式,其中类加载机 ...
随机推荐
- font-failmly字体对应
- JavaScript前端将时间戳转换为日期格式
function (data) { var date = new Date(data) var Y = date.getFullYear() + '-' var M = (date.getMonth( ...
- Linux -- 目录基本操作(1)
cd 切换目录 1.切换到指定目录下 #cd 相对/绝对目录 [root@localhost ~]# cd /home/tom/demo [root@localhost demo]# 2.切换到某个用 ...
- js 时间转换毫秒的四种方法(转)
将时间转换为毫秒数的方法有四个: Date.parse()Date.UTCvalueOf()getTime() 1. Date.parse():该方法接受一个表示日期的字符串参数,然后尝试根据这个日期 ...
- C++练习 | 模板与泛式编程练习
#include <iostream> #include <cmath> #include <cstring> #include <string> #i ...
- c# Reverse()的两点用法
Rervese的基本用途是:反转数组中元素的顺序,常见的两种用法如下: 1.void Array.Reverse(Array array) static void Main(string[] args ...
- Node.js——fs模块(文件系统),创建、删除目录(文件),读取写入文件流
/* 1. fs.stat 检测是文件还是目录(目录 文件是否存在) 2. fs.mkdir 创建目录 (创建之前先判断是否存在) 3. fs.writeFile 写入文件(文件不存在就创建,但不能创 ...
- Docker部署大型互联网电商平台
1.Docker简介 1.1虚拟化 1.1.1什么是虚拟化 在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种实体资源,如服务器.网络.内存及存储等,予以抽象 ...
- 类似register uint32_t __regPriMask __ASM("primask");的代码分析
代码: #define __ASM __asm /*!< asm keyword for ARM Compiler */ #define __INLINE __inline /*!< in ...
- S2-057远程代码执行漏洞复现过程
0x01 搭建环境docker https://github.com/vulhub/vulhub/tree/master/struts2/s2-048 docker-compose up -d 0x0 ...