Python进阶内容(一)--- 高阶函数 High order function
0. 问题
# 本文将围绕这段代码进行Python中高阶函数相关内容的讲解
# 文中所有代码的兼容性要求为:Python 3.6,IPython 6.1.0 def addspam(fn):
def new(*args):
print("spam,spam,spam")
return fn(*args)
return new @addspam
def useful(a,b):
print(a**2+b**2) if __name__ == "__main__":
useful(1,2)
1. Python中一切皆对象
你已经学习了Python中的list, tuple, dict等内置数据结构,当你执行:alist = [1, 2, 3] 时,你就创建了一个List对象,并且用alist这个变量引用它:
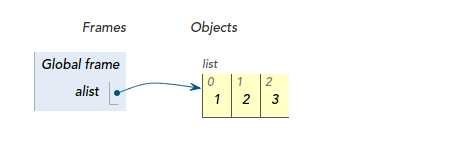
当然你也可以自己定义一个类:
class House(object):
def __init__(self, area, city):
self.area = area
self.city = city def sell(self, price):
[...] #other code
return price # 然后创建一个类的对象:
house = House(200, 'Shanghai')
OK,你立马就在上海有了一套200平米的房子,它有一些属性(area, city),和一些方法(__init__, self):
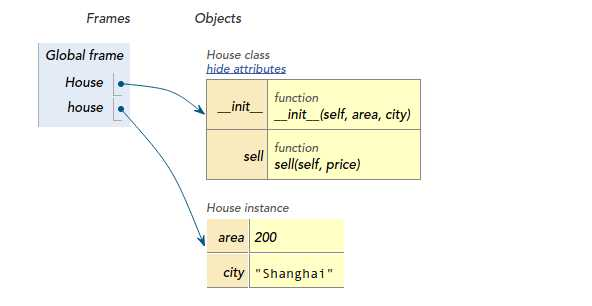
2. 函数是第一类对象
和list, tuple, dict以及House instance一样,当你定义一个函数时,函数也是对象:
def func(a, b):
return a + b
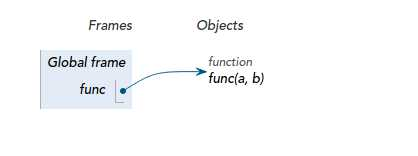
在全局域,函数对象func(a,b)被函数名func引用着,它接收两个参数a和b,计算这两个参数的和作为返回值。
所谓第一类对象,意思是可以用标识符给对象命名,并且对象可以被当作数据处理:例如赋值、作为参数传递给函数,或者作为返回值return 等
因此,你完全可以用其他变量名引用这个函数对象:
def func(a, b):
return a + b add = func
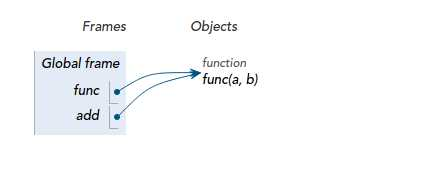
这样,你就可以像调用func(1, 2)一样,通过新的引用add调用函数了:
print(func(1, 2))
print(add(1, 2)) #the same as func(1, 2)

或者将函数对象作为参数,传递给另一个函数:
def func(a, b):
return a + b def caller_func(f):
return f(1, 2) if __name__ == "__main__":
print(caller_func(func))

可以看到,
- 函数对象func(a,b)作为参数传递给caller_func(f)函数,传参过程类似于一个赋值操作f=func;
- 于是函数对象func(a,b),被caller_func函数作用域中的局部变量f引用,f实际指向了函数func;
- 当执行return f(1, 2)的时候,相当于执行了return func(1, 2);
因此输出结果为3。
3. 函数对象 vs 函数调用
无论是把函数赋值给新的标识符,还是作为参数传递给新的函数,针对的都是函数对象本身,而不是函数的调用。
用一个更加简单,但从外观上看,更容易产生混淆的例子来说明这个问题。例如定义了下面这个函数:
def func():
return "hello,world" # 然后分别执行两次赋值:
ref1 = func #将函数对象赋值给ref1
ref2 = func() #调用函数,将函数的返回值("hello,world"字符串)赋值给ref2
# 很多初学者会混淆这两种赋值,通过Python内建的type函数,可以查看一下这两次赋值的结果: In [4]: type(ref1)
Out[4]: function In [5]: type(ref2)
Out[5]: str # 可以看到,ref1引用了函数对象本身,而ref2则引用了函数的返回值。
# 通过内建的callable函数,可以进一步验证ref1是可调用的,而ref2是不可调用的: In [9]: callable(ref1)
Out[9]: True In [10]: callable(ref2)
Out[10]: False
4. 闭包&LEGB法则
所谓闭包,就是将“组成函数的语句和这些语句的执行环境”打包在一起时得到的对象
听上去的确有些复杂,还是用一个栗子来帮助理解一下。假设我们在foo.py模块中做了如下定义:
# foo.py
filename = "foo.py"
def call_func(f):
return f() #如前面介绍的,f引用一个函数对象,然后调用它
在另一个func.py模块中,写下了这样的代码:
# func.py
import foo #导入foo.py
filename = "func.py" def show_filename():
return "filename: %s" % filename if __name__ == "__main__":
print(foo.call_func(show_filename)) # 注意:实际发生调用的位置,是在foo.call_func函数中
# 当我们用python func.py命令执行func.py时输出结果为: $ python func.py
filename:func.py
尽管foo.py模块中也定义了同名的filename变量,实际调用show_filename的位置也是在foo.py的call_func内部。但是很显然show_filename()函数使用的是相同环境(func.py模块)中定义的那个filename变量。
对于嵌套函数,这一机制则会表现的更加明显:闭包将会捕捉内层函数执行所需的整个环境
#enclosed.py
import foo
def wrapper():
filename = "enclosed.py"
def show_filename():
return "filename: %s" % filename
print(foo.call_func(show_filename)) if __name__ == "__main__":
wrapper() #输出:filename: enclosed.py
- Local - 本地函数(show_filename)内部,通过任何方式赋值的,而且没有被global关键字声明为全局变量的filename变量;
- Enclosing - 直接外围空间(上层函数wrapper)的本地作用域,查找filename变量(如果有多层嵌套,则由内而外逐层查找,直至最外层的函数);
- Global - 全局空间(模块enclosed.py),在模块顶层赋值的filename变量;
- Builtin - 内置模块(__builtin__)中预定义的变量名中查找filename变量;
总结:
- 闭包最重要的使用价值在于:封存函数执行的上下文环境;
- 闭包在其捕捉的执行环境(def语句块所在上下文)中,也遵循LEGB规则逐层查找,直至找到符合要求的变量,或者抛出异常。
5. 装饰器&语法糖(syntax sugar)
import functools # 我们定义了一个函数lazy_sum,作用是对alist中的所有元素求和后返回。
# 但是出于某种原因,我并不想马上返回计算结果,而是在之后的某个地方,通过显示的调用输出结果。
# 于是我用一个wrapper函数对其进行包装:
def wrapper():
alist = range(1, 101) # alist假设为1到100的整数列表:alist = range(1, 101) def lazy_sum():
return functools.reduce(lambda x, y: x + y, alist) return lazy_sum lazy_sum = wrapper() # wrapper() 返回的是lazy_sum函数对象 if __name__ == "__main__":
lazy_sum() #
这是一个典型的Lazy Evaluation的例子。我们知道,一般情况下,局部变量在函数返回时,就会被垃圾回收器回收,不能再被使用。但这里的alist却没有,它随着lazy_sum函数对象的返回被一并返回了(这个说法不准确,实际上是通过__globals__属性,包含在了lazy_sum的执行环境中),从而延长了生命周期。当在if语句块中调用lazy_sum()的时候,解析器会从上下文中(这里是Enclosing层的wrapper函数的局部作用域中)找到alist列表,计算结果,返回5050。
当你需要动态的给已定义的函数增加功能时,比如参数检查,类似的原理就变得很有用:
def add(a, b):
return a+b In [4]: add(5, 'hello')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-e88fbc1efa39> in <module>()
----> 1 add(5,"hello") <ipython-input-9-02b3d3d6caec> in add(a, b)
1 def add(a, b):
----> 2 return a+b TypeError: unsupported operand type(s) for +: 'int' and 'str'
动态类型:在运行期间确定变量的类型,Python确定一个变量的类型是在你第一次给他赋值的时候;强类型:有强制的类型定义,你有一个整数,除非显示的类型转换,否则绝不能将它当作一个字符串(例如直接尝试将一个整型和一个字符串做+运算);
因此,为了更加优雅的使用add函数,我们需要在执行求和运算前,对a和b进行参数检查。这时候装饰器就显得非常有用:
# func.py def add(a, b):
return a + b def checkParams(fn):
def wrapper(a, b):
if isinstance(a, (int, float)) and isinstance(b, (int, float)): # 检查参数a和b是否都为整型或浮点型
return fn(a, b) # 是,则调用fn(a, b)返回计算结果
logging.warning("variable 'a' and 'b' cannot be added") # 否,则通过logging记录错误信息,并友好退出
return
return wrapper # fn引用add,被封存在闭包的执行环境中返回 if __name__ == "__main__":
#将add函数对象传入,fn指向add
#等号左侧的add,指向checkParams的返回值wrapper
add = checkParams(add)
add(3, 'hello') #经过类型检查,不会计算结果,而是记录日志并退出
注意checkParams函数:
- 首先看参数fn,当我们调用checkParams(add)的时候,它将成为函数对象add的一个本地(Local)引用;
- 在checkParams内部,我们定义了一个wrapper函数,添加了参数类型检查的功能,然后调用了fn(a, b),根据LEGB法则,解释器将搜索几个作用域,并最终在(Enclosing层)checkParams函数的本地作用域中找到fn;
- 注意最后的return wrapper,这将创建一个闭包,fn变量(add函数对象的一个引用)将会封存在闭包的执行环境中,不会随着checkParams的返回而被回收;
当调用add = checkParams(add)时,add指向了新的wrapper对象,它添加了参数检查和记录日志的功能,同时又能够通过封存的fn,继续调用原始的add进行求和运算。因此调用add(3, 'hello')将不会返回计算结果,而是打印出日志:
$ python func.py
WARNING:root:variable 'a' and 'b' cannot be added
有人觉得add = checkParams(add)这样的写法未免太过麻烦,于是Python提供了一种更优雅的写法,被称为语法糖:
import logging logging.basicConfig(level = logging.INFO) @checkParams
def add(a, b):
return a + b def checkParams(fn):
def wrapper(a, b):
if isinstance(a, (int, float)) and isinstance(b, (int, float)): # 检查参数a和b是否都为整型或浮点型
return fn(a, b) # 是,则调用fn(a, b)返回计算结果
logging.warning("variable 'a' and 'b' cannot be added") # 否,则通过logging记录错误信息,并友好退出
return
return wrapper # fn引用add,被封存在闭包的执行环境中返回 if __name__ == "__main__":
add(3, 'hello') #经过类型检查,不会计算结果,而是记录日志并退出
这只是一种写法上的优化,解释器仍然会将它转化为add = checkParams(add)来执行。
6. 回归问题
def addspam(fn):
def new(*args):
print("spam,spam,spam")
return fn(*args)
return new @addspam
def useful(a,b):
print(a**2+b**2) if __name__ == "__main__":
useful(1,2)
首先看第二段代码:
- @addspam装饰器,相当于执行了useful = addspam(useful)。这里 传递给addspam的参数是useful这个函数对象本身,而不是它的调用结果;
再回到addspam函数体:
- return new 返回一个闭包,fn被封存在闭包的执行环境中,不会随着addspam函数的返回被回收;
- 而fn此时是useful的一个引用,当执行return fn(*args)时,实际相当于执行了return useful(*args);
最后附上一张代码执行过程中的引用关系图,帮助你进行理解:
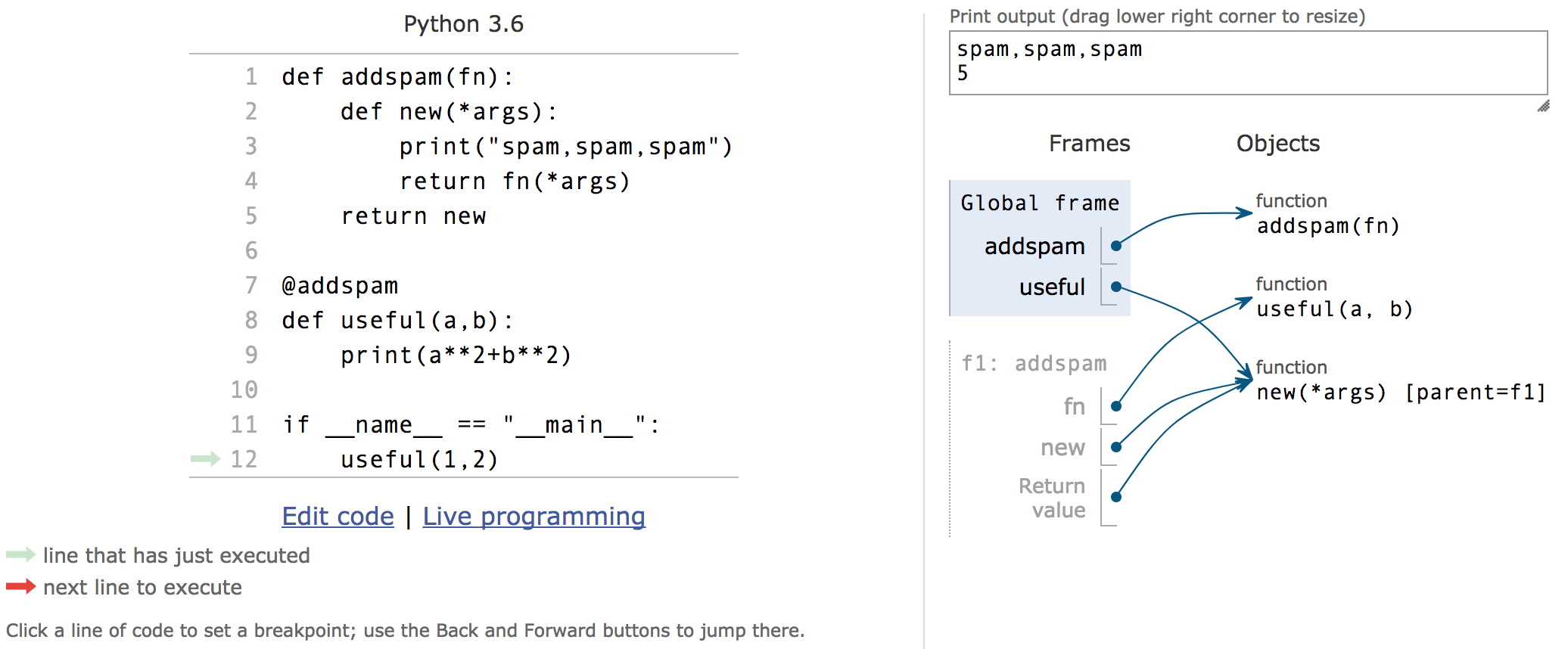
From:http://pythontutor.com/visualize.html#mode=edit
From:https://www.zhihu.com/question/25950466
Python进阶内容(一)--- 高阶函数 High order function的更多相关文章
- python进阶学习之高阶函数
高阶函数就是把函数当做参数传递的一种函数, 例如: 执行结果: 1.map()函数 map()接收一个函数 f 和一个list, 并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 l ...
- 高阶函数 - Higher Order Function
一个函数如果有 参数是函数 或 返回值是函数,就称为高阶函数. 这篇文章介绍高阶函数的一个子集:输入 fn,输出 fn'. 按 fn 与 fn' 功能是否一致,即相同输入是否始终对应相同输出,把这类高 ...
- 【python】python函数式编程、高阶函数
1.map() : python内置的高阶函数,接收一个函数f和一个list,并通过把函数f依次作用在list的每个元素上,得到一个新的list并 返回. def f(x): r ...
- 《前端之路》之 JavaScript 进阶技巧之高阶函数(下)
目录 第二章 - 03: 前端 进阶技巧之高阶函数 一.防篡改对象 1-1:Configurable 和 Writable 1-2:Enumerable 1-3:get .set 2-1:不可扩展对象 ...
- python 函数式编程:高阶函数,map/reduce
python 函数式编程:高阶函数,map/reduce #函数式编程 #函数式编程一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数 #(一)高阶函数 f=abs f print ...
- python入门16 递归函数 高阶函数
递归函数:函数内部调用自身.(要注意跳出条件,否则会死循环) 高阶函数:函数的参数包含函数 递归函数 #coding:utf-8 #/usr/bin/python """ ...
- python内置常用高阶函数(列出了5个常用的)
原文使用的是python2,现修改为python3,全部都实际输出过,可以运行. 引用自:http://www.cnblogs.com/duyaya/p/8562898.html https://bl ...
- python函数式编程之高阶函数学习
基本概念 函数式编程,是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量.因此,任意一个函数,只要输入确定,输出就确定的这种函数我们称之为纯函数,我们称这种函数没有副作用.而允许使用 ...
- python高级 之(三) --- 高阶函数
高阶函数 map函数 简介 """ map(func,*iterables) 参数:一个是函数.一个是序列 作用:将序列中的元素依此作用于函数,将函数运行结果返回 存放于 ...
随机推荐
- Java 语言结构【转】
Java 语言结构 基础:包(Package).类(Class)和对象(Object) 了解 Java 的包(Package).类(Class)和对象(Object)这些基础术语是非常重要的,这部分内 ...
- Mac 10.12安装7zip/rar解压/压缩工具7zip-Keka
说明:Keka支持解压和压缩,基本这个软件全部格式都搞定. 下载: (链接: https://pan.baidu.com/s/1kVmsj8z 密码: pydh)
- anyncTask的3个参数(从源码可以发现其中使用了ThreadPoolExcuter线程池)
AnyncTask异步处理数据并将数据应用到视图的操作场合 一 其中包含这几个方法 1 onPreExcute() 初始化控件,例如进度条2 doInBackground() 具体的执行动作请求数据 ...
- 【软件】chrome设置默认字体
安装stylish插件 新建样式,加入代码 * { font-family: "Microsoft YaHei", "微软雅黑" !important; }
- Git克隆与更新代码
一.克隆项目 除了可以向GitHub上提交项目外,更多的时候是我们到上面克隆(下载)优秀的开源项目来用,当然也可以将使用过程中发现的bug,通过建立分支的方式提交给项目的原作者. 现在的场景是在家将项 ...
- 2-6 js基础-ajax
1.var oAjax=new XmlHttpRequest()//创建一个ajax对象,兼容非ie6 var oAjax=new ActiveXObject('Microsoft.XMLHTTP') ...
- tar.gz和bin,以及rpm,deb等linux后缀的文件的区别
先说tar.gz源码类的吧.这种要你手动安装,编译,首先你还要安装了相关的编译软件如gcc g++ 等.一般操作 configure , make && make install. 其 ...
- 请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧---转
http://www.iteye.com/topic/774673 羞愧呀,不知道多少人干过,我也干过,面壁去! 这帖是用来回复高级语言虚拟机圈子里的一个问题,一道Java笔试题的. 本来因为见得太多 ...
- JavaScript函数——闭包
闭包 概念 只有函数内部的子函数才能读取局部变量,所以闭包可以理解成"定义在一个函数内部的函数".在本质上,闭包是将函数内部和函数外部连接起来的桥梁 例子 function out ...
- 使用FileSystemWatcher监视指定目录
使用 FileSystemWatcher 监视指定目录中的更改.可监视指定目录中的文件或子目录的更改. 以下是一个简单的实例,用来监控指定目录下文件的新增.删除.重命名等情况(文件内容更改会触发多次, ...