使用scrapy写好爬虫进行工作的时候,遇到错误及解决方法
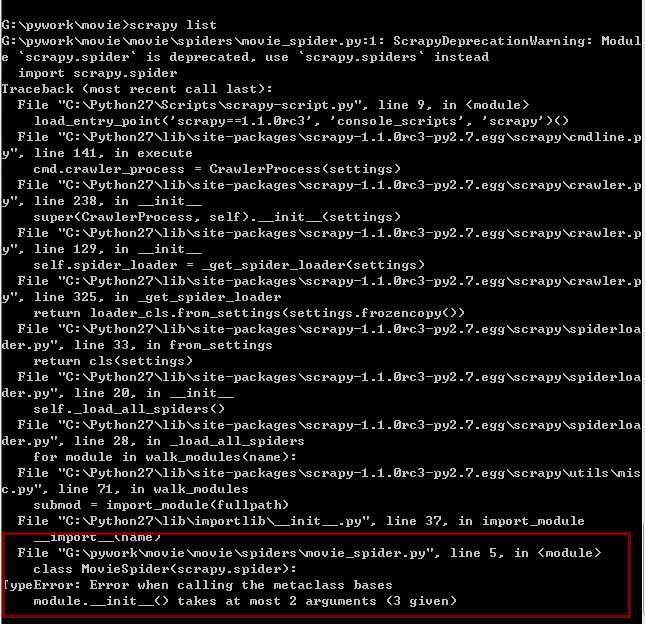
如图中所标出的,提示参数的问题
解决办法:
spider目录下的 爬虫文件内容做些更改:
出现报错的文件内容:
from scrapy.spider
from scrapy.selector import HtmlXPathSelector
class MovieSpider(scrapy.spider):
name="movie"
# allowed_domains=["loldytt.com"]
start_urls=[
"http://www.loldytt.com/"
"http://www.loldytt.com/Xijudianying/"
]
def parse(self,response):
html=HtmlXpathSelector(response)
page=html.select('//ul/li')
for cc in page:
filename=cc.select('a/text()').extract
link=cc.select('a/@href').extract
print filename,link
修改后的文件内容:
from scrapy.spiders import Spider
from scrapy.selector import HtmlXPathSelector
class MovieSpider(Spider):
name="movie"
# allowed_domains=["loldytt.com"]
start_urls=[
"http://www.loldytt.com/"
"http://www.loldytt.com/Xijudianying/"
]
def parse(self,response):
html=HtmlXpathSelector(response)
page=html.select('//ul/li')
for cc in page:
filename=cc.select('a/text()').extract
link=cc.select('a/@href').extract
print filename,link
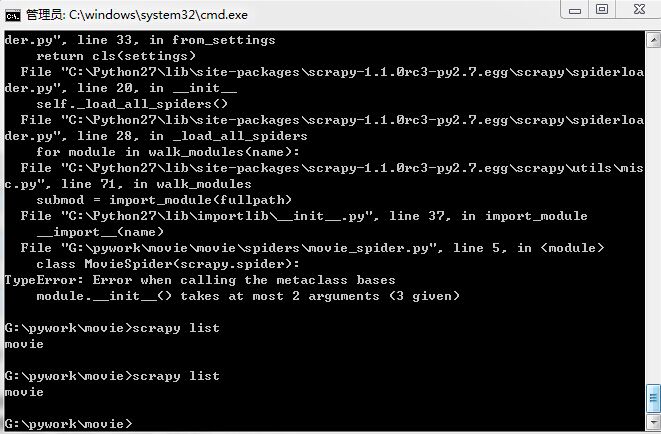
之后运行 就OK了:
使用scrapy写好爬虫进行工作的时候,遇到错误及解决方法的更多相关文章
- SVN工作副本已经锁定错误的解决方法
SVN工作副本锁定错误的解决方法 我们在使用svn版本控制软件时,时常会遇到想要更新本地项目的版本,却突然提示:工作副本已锁定.截图如下: 这种错误让人感觉很不舒服,实际上自己也没做过什么操作就这样了 ...
- 用Scrapy写一个爬虫
昨天用python谢了一个简单爬虫,抓取页面图片: 但实际用到的爬虫需要处理很多复杂的环境,也需要更加的智能,重复发明轮子的事情不能干, 再说python向来以爬虫作为其擅长的一个领域,想必有许多成熟 ...
- 安装Scrapy报错 error: Microsoft Visual C++ 14.0 is required解决方法
[问题背景]:在Windows 10系统,pip install Scrapy,报错error: Microsoft Visual C++ 14.0 is required,还有提示Twisted需要 ...
- windows下安装phpcms html/ 文件夹不可写的一种错误以及解决方法
朋友安装phpcms时遇到奇葩问题,环境搭建在windows7中,竟然出现 html/ 和 phpsso_server/caches/文件夹不可写问题(如图) 在windows下出现这种权限的问题真不 ...
- java写文件时,输出不完整的原因以及解决方法
在java的IO体系中,写文件通常会用到下面语句 BufferedWriter bo=new BufferedWriter(new FileWriter("sql语句.txt")) ...
- java写文件时,输出不完整的原因以及解决方法close()或flush()
在java的IO体系中,写文件通常会用到下面语句 BufferedWriter bw=new BufferedWriter(new FileWriter("sql语句.txt")) ...
- 在js文件中写el表达式取不到值的原因及解决方法
1.javascript是客户端执行,EL是在服务端执行,而服务端比客户端先执行,所以取不到值 2.要想获取"${jcDropClass.jcClass.id}"的值,可以在jsp ...
- [原创]手把手教你写网络爬虫(4):Scrapy入门
手把手教你写网络爬虫(4) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花! 咦?怎么有人扔西红柿 ...
- Python:Scrapy(二) 实例分析与总结、写一个爬虫的一般步骤
学习自:Scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 - 知乎 Python Scrapy 爬虫框架实例(一) - Blue·Sky - 博客园 1.声明Item 爬虫爬取的目标是从非 ...
随机推荐
- Matplotlib不显示图形
安装好了Matplotlib,使用官方一个例子测试运行时,发现使用画图功能时,运行脚本老是显示不出图像,Google了一下,后来发现是matplotlibrc文件没配置好. 参考了官方文档,修改步骤如 ...
- Eclipse代码风格设置
在编写代码的过程中,代码的呈现形式是通过eclipse的Formatter配置文件所控制的.我们可以按照自己的习惯生成属于自己的代码风格配置文件,方便规范以后的代码编写形式.具体的操作步骤如下所示:( ...
- Thinking in Java——集合(Collection)
一.ArrayList的使用(略) 二.容器的基本概念 (一).Collection是集合类的基本接口 主要方法: public interface Collection<E>{ bool ...
- Kali Linux 新手折腾笔记
http://defcon.cn/1618.html 2014年09月29日 渗透测试 暂无评论 阅读 55,052 次 最近在折腾Kali Linux 顺便做一简单整理,至于安装就不再多扯了,估 ...
- 手动升级Delphi控件时,修改inc文件的办法
以MustangPeakCommonLib.exe控件为例,想让它支持Delphi2010,就需要在D:\Program Files\Common Library\Mustangpeak\Common ...
- inet address example(socket)
package com.opensource.socket; import java.net.Inet4Address; import java.net.Inet6Address; import ja ...
- zookeeper数据弱一致性
zookeeper本身支持单机部署和集群部署,生产环境建议使用集群部署,因为集群部署不存在单点故障问题,并且zookeeper建议部署的节点个数为奇数个,只有超过一半的机器不可用整个zk集群才不可用. ...
- javascript第十五课:DOM
dom就是文档,就是整个网页的简称,dom里面的标签就是对象 使用javascript进行DHMTL网页开发(Dynamic Html 动态网页) dom就是把html页面模拟成一个对象,顶级对象wi ...
- Fast RCNN 学习
因为项目需要,之前没有接触过深度学习的东西,现在需要学习Fast RCNN这个方法. 一步步来,先跟着做,然后再学习理论 Fast RCNN 训练自己数据集 (1编译配置) Fast RCNN 训练自 ...
- Android_Layout_xml布局
本博文为子墨原创,转载请注明出处! http://blog.csdn.net/zimo2013/article/details/11840079 1.构建xml布局文件 使用android提供的xml ...