深度学习 | 训练网络trick——mixup
1.mixup原理介绍
mixup 论文地址
mixup是一种非常规的数据增强方法,一个和数据无关的简单数据增强原则,其以线性插值的方式来构建新的训练样本和标签。最终对标签的处理如下公式所示,这很简单但对于增强策略来说又很不一般。
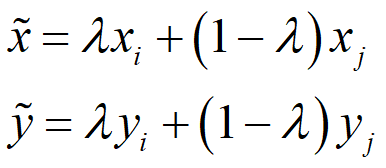

,两个数据对是原始数据集中的训练样本对(训练样本和其对应的标签)。其中是一个服从B分布的参数,
。Beta分布的概率密度函数如下图所示,其中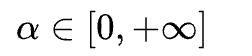
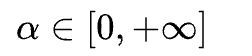
因此,α 是一个超参数,随着α的增大,网络的训练误差就会增加,而其泛化能力会随之增强。而当 α→∞ 时,模型就会退化成最原始的训练策略。
2.mixup的代码实现
如下代码所示,实现mixup数据增强很简单,其实我个人认为这就是一种抑制过拟合的策略,增加了一些扰动,从而提升了模型的泛化能力。
def get_batch(x, y, step, batch_size, alpha=0.2):
"""
get batch data
:param x: training data
:param y: one-hot label
:param step: step
:param batch_size: batch size
:param alpha: hyper-parameter α, default as 0.2
:return:
"""
candidates_data, candidates_label = x, y
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
# get batch data
train_features_batch = candidates_data[offset:(offset + batch_size)]
train_labels_batch = candidates_label[offset:(offset + batch_size)]
# 最原始的训练方式
if alpha == 0:
return train_features_batch, train_labels_batch
# mixup增强后的训练方式
if alpha > 0:
weight = np.random.beta(alpha, alpha, batch_size)
x_weight = weight.reshape(batch_size, 1, 1, 1)
y_weight = weight.reshape(batch_size, 1)
index = np.random.permutation(batch_size)
x1, x2 = train_features_batch, train_features_batch[index]
x = x1 * x_weight + x2 * (1 - x_weight)
y1, y2 = train_labels_batch, train_labels_batch[index]
y = y1 * y_weight + y2 * (1 - y_weight)
return x, y
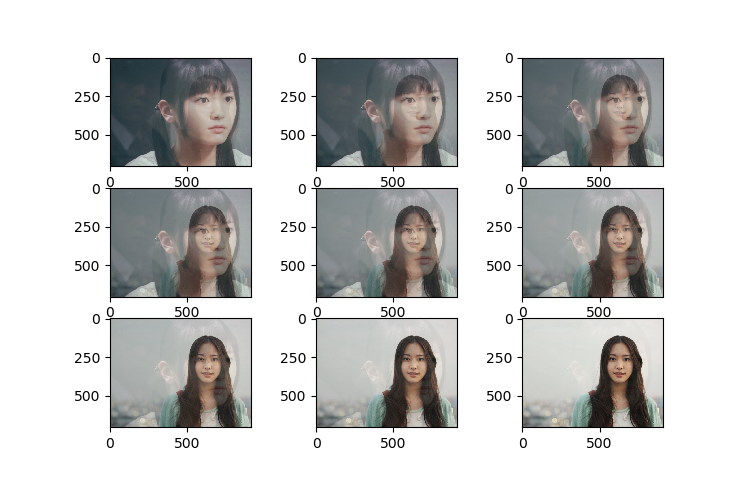
3.mixup增强效果展示
import matplotlib.pyplot as plt
import matplotlib.image as Image
import numpy as np
im1 = Image.imread(r"C:\Users\Daisy\Desktop\1\xyjy.png")
im2 = Image.imread(r"C:\Users\Daisy\Desktop\1\xyjy2.png")
for i in range(1,10):
lam= i*0.1
im_mixup = (im1*lam+im2*(1-lam))
plt.subplot(3,3,i)
plt.imshow(im_mixup)
plt.show()
————————————————————
后来又发现一篇好文:https://www.zhihu.com/question/308572298?sort=created
深度学习 | 训练网络trick——mixup的更多相关文章
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- TensorRT深度学习训练和部署图示
TensorRT深度学习训练和部署 NVIDIA TensorRT是用于生产环境的高性能深度学习推理库.功率效率和响应速度是部署的深度学习应用程序的两个关键指标,因为它们直接影响用户体验和所提供服务的 ...
- 基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化 New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs 不同行业采用 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强 可有效助力深度学习训练 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. 目前根据英特尔 至强 可扩展处理器的MLPerf结果显 ...
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 【Deeplearning】(转)深度学习知识网络
转自深度学习知识框架,小象牛逼! 图片来自小象学院公开课,下面直接解释几条线 神经网络 线性回归 (+ 非线性激励) → 神经网络 有线性映射关系的数据,找到映射关系,非常简单,只能描述简单的映射关系 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
- 深度学习卷积网络中反卷积/转置卷积的理解 transposed conv/deconv
搞明白了卷积网络中所谓deconv到底是个什么东西后,不写下来怕又忘记,根据参考资料,加上我自己的理解,记录在这篇博客里. 先来规范表达 为了方便理解,本文出现的举例情况都是2D矩阵卷积,卷积输入和核 ...
随机推荐
- 你闺女也能看懂的插画版 Kubernetes 指南
Matt Butcher是Deis的平台架构师,热爱哲学,咖啡和精雕细琢的代码.有一天女儿走进书房问他什么是Kubernetes,于是就有了这本插画版的Kubernetes指南,讲述了勇敢的Phipp ...
- P.SDA1.DEV - 一个没有服务器的图床
图床特色 P.SDA1.DEV的愿景是为大家提供一个免费.长期稳定外链分享图片的选择. P.SDA1.DEV的主要特点有: 完全建构在Serverless云服务上,致力于提供(墙外)可用性99.9%的 ...
- eclipse导入项目出现红叉
转载:原博客 导入web项目有红叉时可能是path环境不支持需要配置自己电脑的path,所以需要build path 出现java代码错误或者…jsp文件出错(https://img-blog.csd ...
- C++语法小记---一个有趣的现象
下面的代码会飞吗? #include <iostream> #include <string> using namespace std; class Test { public ...
- 解决android studio Gradle无法同步问题
打开根目录build.gradle buildscript { repositories { // 添加阿里云 maven 地址 maven { url 'http://maven.aliyun.co ...
- 前端学习(五):body标签(三)
进击のpython ***** 前端学习--body标签 接下来的内容就比较多了,各位看官且听我慢慢道来... ... 使用a标签,链接到另一个页面 网页中<a>标签,全称:anchor. ...
- 2018年5月15日的sqlite安装和数据库记录
sqlite数据库安装在d:\sqlite_files运行sqlite3查看数据表,命令,.tables 数据库文件 d:\sqlite_files\device.db create table de ...
- Jupyter Notebook 导出PDF与Latex中文支持
Jupyter Notebook 最近搞机器学习用到了Jupyter Notebook. 作为一个实时记事本,有时需要将内容导出为PDF. 但是,Jupyter Notebook自带的File -&g ...
- springmvc的原理与流程
springMVC中的几个组件: 前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU. 处理器映射器(HandlerMapping):根据URL去查找处理器 处理 ...
- __new__方法理解
class Foo(object): def __init__(self, *args, **kwargs): pass def __new__(cls, *args, **kwargs): retu ...