数据治理工具调研之DataHub
![]()
1.项目简介
Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
2.项目架构
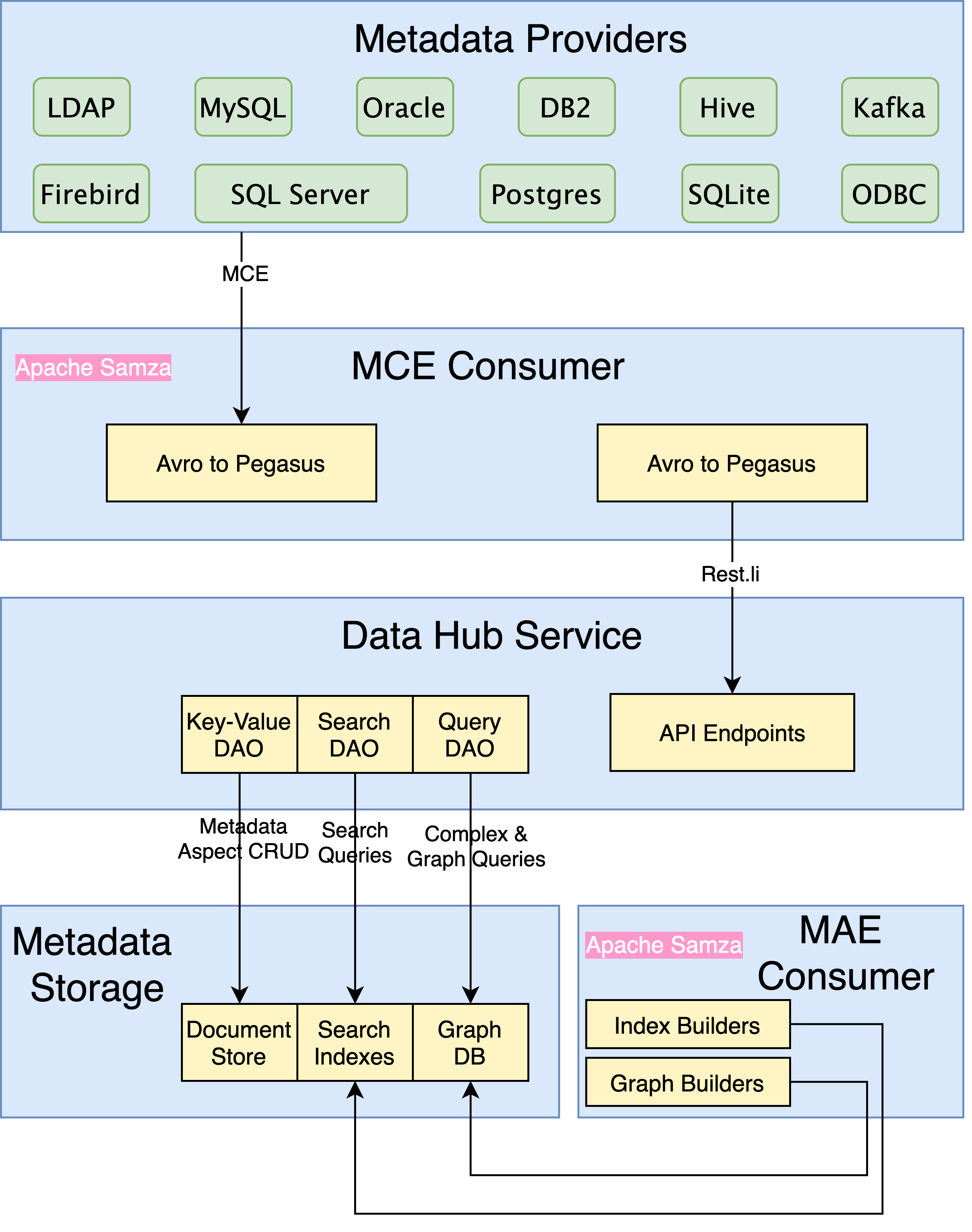
Data Hub使用的是Generalized metadata architecture(GMA),重点面对多种元数据可伸缩性的四项挑战。
- 建模:以对开发人员友好的方式对所有类型的元数据和关系进行建模。
- 摄取:通过API和流大规模摄取大量的元数据更改。
- 服务:大规模服务收集的原始元数据和派生的元数据,以及针对元数据的各种复杂查询。
- 索引:按比例索引元数据,并在元数据更改时自动更新索引。
元数据建模
元数据也是数据:
要对元数据建模,我们需要一种语言,其功能至少应与通用数据建模所使用的语言一样丰富。
元数据是分布式的:
期望所有元数据都来自单一来源是不现实的。例如,管理数据集的访问控制列表(ACL)的系统很可能不同于存储架构元数据的系统。一个好的建模框架应允许多个团队独立地发展其元数据模型,同时提供与数据实体关联的所有元数据的统一视图。
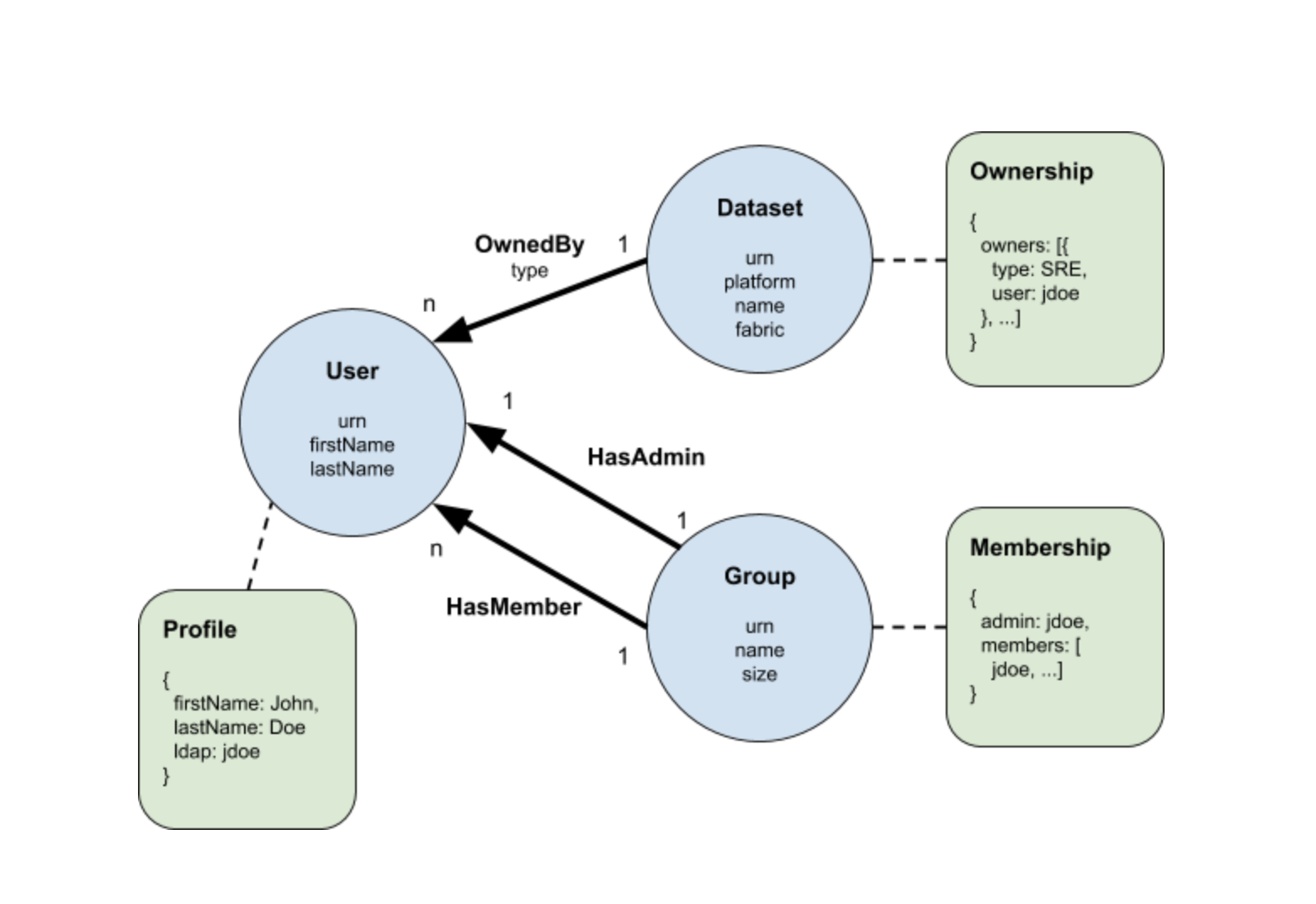
使用Pegasus(一种由LinkedIn创建的开源且完善的数据模式语言)进行元数据建模。
{
"type": "record",
"name": "User",
"fields": [
{
"name": "urn",
"type": "com.linkedin.common.UserUrn",
},
{
"name": "firstName",
"type": "string",
"optional": true
},
{
"name": "lastName",
"type": "string",
"optional": true
},
{
"name": "ldap",
"type": "com.linkedin.common.LDAP",
"optional": true
}
]
}
每个实体都必须具有URN形式的全局唯一ID ,可以将其视为类型化的GUID。User实体具有的属性包括名字,姓氏和LDAP,每个属性都映射到User记录中的可选字段。
{
"type": "record",
"name": "OwnedBy",
"fields": [
{
"name": "source",
"type": "com.linkedin.common.Urn",
},
{
"name": "destination",
"type": "com.linkedin.common.Urn",
},
{
"name": "type",
"type": "com.linkedin.common.OwnershipType",
}
],
"pairings": [
{
"source": "com.linkedin.common.urn.DatasetUrn",
"destination": "com.linkedin.common.urn.UserUrn"
}
]
}
每个关系模型自然包含使用其URN指向特定实体实例的“源”和“目的地”字段。模型可以选择包含其他属性字段,在这种情况下,例如“类型”。在这里,我们还引入了一个称为“ pairings”的自定义属性,以将关系限制为特定的源和目标URN类型对。在这种情况下,OwnedBy关系只能用于将数据集连接到用户。
"type": "record",
"name": "Ownership",
"fields": [
{
"name": "owners",
"type": {
"type": "array",
"items": {
"name": "owner",
"type": "record",
"fields": [
{
"name": "type",
"type": "com.linkedin.common.OwnershipType"
},
{
"name": "ldap",
"type": "string"
}
]
}
}
}
]
}
上面是所有权元数据方面的模型。在这里,我们选择将所有权建模为包含type和ldap字段的记录数组。但是,在建模元数据方面时,只要它是有效的PDSC记录,实际上就没有限制。这样就可以满足前面提到的“元数据也是数据”的要求。
元数据摄取
DataHub提供两种形式的元数据摄取:通过直接API调用或Kafka流。前者用于需要写入后读取一致性的元数据更改,而后者更适合于面向事实的更新。
DataHub的API基于Rest.li,这是一种可扩展的强类型RESTful服务架构,已在LinkedIn上广泛使用。由于Rest.li使用Pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从API到存储需要进行多层模型转换的日子已经一去不复返了-API和模型将始终保持同步。
对于基于Kafka的提取,预计元数据生产者会发出标准化的元数据更改事件(MCE),其中包含由相应实体URN键控的对特定元数据方面的建议更改列表。当MCE的模式位于Apache Avro中时,它是从Pegasus元数据模型自动生成的。
对API和Kafka事件模式使用相同的元数据模型,使我们能够轻松地开发模型,而无需精心维护相应的转换逻辑。但是,为了实现真正的无缝模式演变,我们需要限制所有模式更改以始终向后兼容。这是在构建时通过添加兼容性检查来强制实施的。
在领英,由于生产者和消费者之间的松散耦合,我们倾向于更加依赖Kafka流。每天,我们都会收到来自不同生产者的数百万个MCE,并且随着我们扩大元数据集合的范围,其数量只会呈指数增长。为了构建流元数据获取管道,我们利用Apache Samza作为流处理框架。摄取Samza作业的目的是快速,简单地实现高吞吐量。它只是将Avro数据转换回Pegasus,并调用相应的Rest.li API以完成提取。
元数据服务
一旦摄取并存储了元数据,有效地处理原始和派生的元数据就很重要。DataHub旨在支持对大量元数据的四种常见查询类型:
- 面向文档的查询
- 面向图的查询
- 涉及联接的复杂查询
- 全文搜索
为此,DataHub需要使用多种数据系统,每种数据系统专门用于扩展和服务有限类型的查询。例如,Espresso是LinkedIn的NoSQL数据库,特别适合大规模面向文档的CRUD。同样,Galene可以轻松索引并提供网络规模的全文搜索。当涉及到非平凡的图查询时,毫不奇怪的是,专用图数据库的性能要比基于RDBMS的实现好几个数量级。但是,事实证明,图结构也是表示外键关系的自然方法,从而可以有效地回答复杂的联接查询。
DataHub通过一组通用的数据访问对象(DAO)(例如键值DAO,查询DAO和搜索DAO )进一步抽象底层数据系统。然后,可以在不更改DataHub中任何业务逻辑的情况下轻松地换入和换出DAO的特定于数据系统的实现。这最终将使我们能够使用流行的开源系统的参考实现来开源DataHub,同时仍然充分利用LinkedIn的专有存储技术。
DAO抽象的另一个主要好处是标准化的变更数据捕获(CDC)。无论基础数据存储系统的类型如何,通过键值DAO进行的任何更新操作都将自动发出元数据审核事件(MAE)。每个MAE都包含相应实体的URN,以及特定元数据方面的前后图像。这实现了lambda体系结构,在此体系结构中,MAE可以批量或流式处理。与MCE相似,MAE的架构也可以从元数据模型中自动生成。
元数据索引
最后一个难题是元数据索引管道。该系统将元数据模型连接在一起,并在图形数据库和搜索引擎中创建相应的索引,以促进高效的查询。这些业务逻辑以“索引构建器”和“图形构建器”的形式捕获,并作为处理MAE的Samza作业的一部分执行。每个构建者都在工作中注册了对特定元数据方面的兴趣,并将通过相应的MAE进行调用。然后,构建器返回要应用于搜索索引或图形数据库的幂等更新的列表。
元数据索引管道还具有高度可伸缩性,因为它可以基于每个MAE的实体URN轻松进行分区,以支持对每个实体的有序处理。
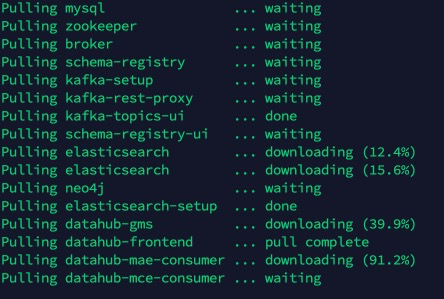
DataHub安装记录
clone git项目
安装quickstart
cd datahub/docker/quickstart
source ./quickstart.sh
此时会开始部署各种docker容器
数据治理工具调研之DataHub的更多相关文章
- 数据层交换和高性能并发处理(开源ETL大数据治理工具--KETTLE使用及二次开发 )
ETL是什么?为什么要使用ETL?KETTLE是什么?为什么要学KETTLE? ETL是数据的抽取清洗转换加载的过程,是数据进入数据仓库进行大数据分析的载入过程,目前流行的数据进入仓库的 ...
- 数据治理方案技术调研 Atlas VS Datahub VS Amundsen
数据治理意义重大,传统的数据治理采用文档的形式进行管理,已经无法满足大数据下的数据治理需要.而适合于Hadoop大数据生态体系的数据治理就非常的重要了. 大数据下的数据治理作为很多企业的一个巨大的 ...
- DataHub——实时数据治理平台
DataHub 首先,阿里云也有一款名为DataHub的产品,是一个流式处理平台,本文所述DataHub与其无关. 数据治理是大佬们最近谈的一个火热的话题.不管国家层面,还是企业层面现在对这个问题是越 ...
- 企业级数据治理工作怎么开展?Datahub这样做
大数据发展到今天,扮演了越来越重要的作用.数据可以为各种组织和企业提供关键决策的支持,也可以通过数据分析帮助发现更多的有价值的东西,如商机.风险等等. 在数据治理工作开展的时候,往往会有一个专门负责数 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- Github 1.9K Star的数据治理框架-Amundsen
Amundsen的使命,整理有关数据的所有信息,并使其具有普遍适用性. 这是Amundsen官网的一句话,对于元数据的管理工作,复杂且繁琐.可用的工具很多各有千秋,数据血缘做的较好的应该是Apache ...
- 数据治理之元数据管理的利器——Atlas入门宝典
随着数字化转型的工作推进,数据治理的工作已经被越来越多的公司提上了日程.作为Hadoop生态最紧密的元数据管理与发现工具,Atlas在其中扮演着重要的位置.但是其官方文档不是很丰富,也不够详细.所以整 ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- 一文读懂 Spring Boot、微服务架构和大数据治理三者之间的故事
微服务架构 微服务的诞生并非偶然,它是在互联网高速发展,技术日新月异的变化以及传统架构无法适应快速变化等多重因素的推动下诞生的产物.互联网时代的产品通常有两类特点:需求变化快和用户群体庞大,在这种情况 ...
随机推荐
- Java WebService _CXF、Xfire、AXIS2、AXIS1_四种发布方式(使用整理)
目录 1. CXF方式2. Xfire方式3. AXIS2方式4. AXIS1方式5. AXIS1客户端调用6. AXIS2客户端调用7. CXF客户端调用8. Web Service Client客 ...
- 使用TimerTask创建定时任务
使用TimerTask创建定时任务,打包之后应用于linux系统 step1:创建java项目 step2:代码实现 定时任务实现类CreateTask.java是打印操作者的名字 配置准换类Conf ...
- PID各环节的意义和功能,自带PID的matlab编程实例
这是PID的标准形式包括比例/积分/微分三部分,e为偏差 下面我们分析三个环节的作用,设:当前系统状态A,目标状态B, e=B-A,初始状态e>0 (以下是个人的理解,欢迎读者评论) 1 比例环 ...
- VC单选按钮控件(Radio Button)用法(转)
先为对话框加上2个radio button,分别是Radio1和Radio2. 问题1:如何让Radio1或者Radio2默认选上?如何知道哪个被选上了? 关键是选上,“默认”只要放在OnInitDi ...
- MVC+EFCore 项目实战-数仓管理系统1
项目背景及需求说明 这是一个数据管理"工具类"的系统,计划有三个核心功能: 1.通过界面配置相关连接字符串,查询数据库的表数据. 2.配置相关模板,生成数据库表. 可以界面填报或通 ...
- Linux中快捷生成自签名ssl证书_113资讯网
一.生成CA私钥 mkdir ca cd ca #创建私钥 (建议设置密码) openssl genrsa -des3 -out myCA.key 2048 生成CA证书 # 20 年有效期 open ...
- Python3笔记018 - 4.3 元组
第4章 序列的应用 python的数据类型分为:空类型.布尔类型.数字类型.字节类型.字符串类型.元组类型.列表类型.字典类型.集合类型 在python中序列是一块用于存放多个值的连续内存空间. py ...
- HotSpot的启动过程
HotSpot通常会通过java.exe或javaw.exe来调用/jdk/src/share/bin/main.c文件中的main()函数来启动虚拟机,使用Eclipse进行调试时,也会调用到这个入 ...
- 洛谷 P2220 [HAOI2012]容易题 数论
洛谷 P2220 [HAOI2012]容易题 题目描述 为了使得大家高兴,小Q特意出个自认为的简单题(easy)来满足大家,这道简单题是描述如下: 有一个数列A已知对于所有的A[i]都是1~n的自然数 ...
- salesman,动态规划带一点点贪心。
题目直接链接 分析一下: 这题题意还是比较明白的(少见的一道中文题),他的意思就是:有这么一个无向图:保证联通且点与点直接有唯一的简单路径(说白了就是棵树,根节点是1),每个节点有一个权值(有正有负) ...