Ⅳ Monte Carlo Methods
Dictum:
Nutrition books in the world. There is no book in life, there is no sunlight; wisdom without books, as if the birds do not have wings. -- Shakespeare
蒙特卡洛(Monte Carlo, MC)方法是一种不基于模型的方法。它不需要具有完备的环境知识,只要求具备经验,即来自于真实的或模拟的环境交互过程中的样本序列\(\{\mathcal{S},\mathcal{A},\mathcal{R}\}\)。
同时,MC方法是基于平均采样回报来解决强化学习问题,只针对幕式任务。
预备知识
MC预测
MC方法是根据经验进行估计,即对访问该状态后观测到的回报求均值,随着观测到的回报越来越多,均值会逐渐收敛于期望值。
MC方法又可以分为首次访问型MC方法(first-visit MC method)和每次访问型MC方法(every-visit MC method):
- 首次访问型MC方法用首次访问状态\(s\)得到的回报均值估计\(v_\pi(s)\)
- 每次访问型MC方法用所有访问状态\(s\)得到的回报均值估计\(v_\pi(s)\)
根据大数定律(law of large numbers),当对\(s\)的访问次数趋向无穷时,两种方法的估计值都会收敛于\(v_\pi(s)\)。
MC方法没有完备的环境模型,因此,将对状态的访问改为对“状态-动作”二元组的访,也就是说它估计的是\(q_\pi(s,a)\)而不是\(v_\pi(s)\)。
MC控制
MC方法也是用策略迭代算法进行控制,但更新的是\(q_\pi(a|s)\)。
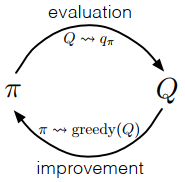
由上图,可以写出MC的策略迭代过程:
\]
和DP相同,选择贪心策略需要满足
\]
策略改进通过将\(q_{\pi_k}\)对应的贪心策略作为\(\pi_{k+1}\)进行,满足策略改进定理,即
q_{\pi_{k}}\left(s, \pi_{k+1}(s)\right) &=q_{\pi_{k}}\left(s, \underset{a}{\arg \max } q_{\pi_{k}}(s, a)\right) \\
&=\max _{a} q_{\pi_{k}}(s, a) \\
& \geq q_{\pi_{k}}\left(s, \pi_{k}(s)\right) \\
& \geq v_{\pi_{k}}(s)
\end{aligned} \tag{4.2}\]
MC方法
MC方法可以分成同步策略(on-policy)方法和异步策略(off-policy)方法,它们的区别:
- 同步策略方法用于生成决策轨迹的策略和进行评估或改进的策略是相同的;
- 异步策略方法用于生成决策轨迹的策略和进行评估或改进的策略是不同的。
同步策略方法
在同步策略方法中,策略是“软性(soft)”的,即对任意\(s \in \mathcal{S},a \in \mathcal{A}(s)\),都有\(\pi(a|s)>0\)。最典型的同步策略方法是\(\varepsilon\)-贪心策略(\(\varepsilon\)-greedy policy),即多数时候会选择具有最大估计动作价值的动作,但有\(\varepsilon\)的概率随机选择一个动作,该策略可以被表示为
1-\varepsilon+\varepsilon /|\mathcal{A}(s)| & \text { if } a=A^{*} \\
\varepsilon /|\mathcal{A}(s)| & \text { if } a \neq A^{*}
\end{array}\right. \tag{4.3}\]
根据策略改进定理,对于一个\(\varepsilon\)-软性策略\(\pi\),任何一个根据\(q_\pi\)生成的\(\varepsilon\)-贪心策略都是对它的一个改进。假设\(\pi^\prime\)是一个\(\varepsilon\)-贪心策略,即
q_{\pi}\left(s, \pi^{\prime}(s)\right) &=\sum_{a} \pi^{\prime}(a | s) q_{\pi}(s, a) \\
&=\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+(1-\varepsilon) \max _{a} q_{\pi}(s, a) \\
& \geq \frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+(1-\varepsilon) \sum_{a} \frac{\pi(a | s)-\frac{\epsilon}{|\mathcal{A}(s)|}}{1-\varepsilon} q_{\pi}(s, a) \\
&=\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)-\frac{\epsilon}{|\mathcal{A}(s)|} \sum_{a} q_{\pi}(s, a)+\sum_{a} \pi(a | s) q_{\pi}(s, a)\\
&=v_{\pi}(s)
\end{aligned} \tag{4.4}\]
异步策略方法
所有的学习控制方法都面临一个困境:它们试图学习最优动作价值,但为了探索所有的动作,以此保证找到最优动作,它们需要尝试那些非最优的动作。
同步策略方法只是提出了一个妥协的办法——它并不是学习最优策略的动作价值,而是学习一个近似最优且仍能进行探索的策略的动作价值。
而异步策略方法则是使用两个不同的策略,一个用于学习并最终达到最优的目标策略(target policy),另一个更具探索性,并能生成决策序列的行为策略(behavior policy)。
异步策略方法使用了重要性采样(详见附录A),根据在目标策略和行为策略生成的轨迹的相对概率(即重要性采样比)对回报值加权。
假设目标策略为\(\pi\),行为策略为\(b(\pi \neq b)\)。然后,给定一个起始状态\(S_t\),后续的“状态-动作”轨迹\(A_t,S_{t+1},A_{t+1},...,S_T\)在任意策略\(\pi\)下的概率为
\operatorname{Pr}\left\{A_{t}, S_{t+1}, A_{t+1}, \ldots, S_{T} | S_{t}, A_{t: T-1} \sim \pi\right\} \\
\quad=\pi\left(A_{t} | S_{t}\right) p\left(S_{t+1} | S_{t}, A_{t}\right) \pi\left(A_{t+1} | S_{t+1}\right) \cdots p\left(S_{T} | S_{T-1}, A_{T-1}\right) \\
\quad=\displaystyle \prod_{k=t}^{T-1} \pi\left(A_{k} | S_{k}\right) p\left(S_{k+1} | S_{k}, A_{k}\right)
\end{array} \tag{4.5}\]
\(p\)为状态转移概率函数。可以得到重要性采样比为
\]
由此可以看出,\(\rho\)只与策略\(\pi\),\(b\)和样本序列有关,与MDP的动态特性无关。
下面通过一批观察得到的遵循策略\(b\)的episodes来估计\(v_\pi(s)\)。定义时间步长集合\(\mathcal{T}(s)\)在首次访问型方法下,包含所有访问过状态\(s\)的时间步长;在首次访问型方法,只包含在episode内首次访问状态\(s\)的时间步长。用\(T(t)\)表示时刻t后的首次终止时刻,\(G_t\)表示\(t\)到\(T(t)\)之间的回报值,\(\left\{\rho_{t: T(t)-1}\right\}_{t \in \mathcal{T}(s)}\)表示相应的重要性采样比。
那么可以得出,普通重要性采样为\(V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{|\mathcal{T}(s)|}\)
加权重要性采样为\(V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1} G_{t}}{\sum_{t \in \mathcal{T}(s)} \rho_{t: T(t)-1}}\)(若分母为\(0\),\(V(s)=0\))
关于价值函数的更新,可以通过增量式实现(详见附录B)。假设有一个回报序列\(G_1,G_2,...,G_{n-1}\),它们都是从相同的状态开始,且每一个回报都对应一个权重\(W_i\),则可以定义
\]
假设前\(n\)个回报对应的权重累加和为\(C_n\),则\(V_n\)的更新方式为
\]
\]
Append
重要性采样
重要性采样(importance sampling)主要作用是通过一个简单的可预测分布区估计一个服从另一个分布的随机变量的均值。
在重要性采样中,随机变量服从的分布不同但其元素的集合相同。因此,假设变量\(A_1 \sim P\),\(A_2 \sim Q\),其中\(P=\{p_1,p_2,...,p_n\}\),\(Q=\{q_1,q_2,...,q_n\}\)。离散随机变量\(A_1\)可以写成\(A=\{x_1,x_2,...,x_n\}\),其每个元素出现的概率都对应分布\(P\);同样,\(A_2\)可以写出\(A=\{x_1,x_2,...,x_n\}\),其每个元素出现的概率都对应分布\(Q\)。则\(\mathbb{E}[A_1]= \displaystyle \sum^n_{i=1}x_ip_i\),\(\mathbb{E}[A_2]= \displaystyle \sum^n_{i=1}x_iq_i\)。
经过N次试验后,用MC估计得到它们的均值\(\overline{A}_1=\frac{1}{N} \displaystyle \sum_{i=1}^{N} x_{i} K_{i}\),\(\overline{A}_2=\frac{1}{N} \displaystyle \sum_{i=1}^{N} x_{i} M_{i}\)(\(K_i\)和\(M_i\)分别表示\(x_i\)在两次试验中出现的次数,所以\(\displaystyle \sum_i K_i=\sum_i M_i=N\)),根据大数定律,当试验次数\(N \rightarrow \infty\)时,统计均值是期望的无偏估计。
了解基本原理后,现在考虑如何运用。假设现在只能做关于\(A_2\)的试验,但又想估计\(A_1\)的均值,那么只需要将\(K_i\)替换为\(M_i\)。当试验次数\(N \rightarrow \infty\)时,\(K_i \approx Np_i\),\(K_i \approx Np_i\),可以推出\(K_i \approx M_i \frac{p_i}{q_i}\)。因此,\(A_1\)的均值估计可以写为\(\overline{A}_1=\frac{1}{N} \displaystyle \sum_{i=1}^{N} (x_{i}\frac{p_i}{q_i}) M_{i}\)。
上述内容为普通重要性采样(ordinary importance sampling),但这只对\(K_i\)做了近似处理,\(\displaystyle \sum_i \frac{p_i}{q_i} M_{i}\)并非严格等于\(N\),会导致无界的方差,即无论\(N\)多大,普通重要性采样的估计值方差始终不会趋向于\(0\)。为了解决这个问题,进行了加权处理,就有了加权重要性采样(weighted importance sampling),只需将试验次数\(N\)替换成估计的试验次数\(\displaystyle \sum_i \frac{p_i}{q_i} M_{i}\),则可得
\]
\(\frac{p_i}{q_i}\)为重要性采样比(importance-sampling ratio)。普通重要性采样的估计是无偏的,而加权重要性采样的估计是有偏的且偏差逐渐收敛为\(0\);普通重要性采样方差无界,而加权重要性采样估计的方差仍能收敛于\(0\)。
增量式实现
Q_{n+1} &=\frac{1}{n} \sum_{i=1}^{n} R_{i} \\
&=\frac{1}{n}\left(R_{n}+\sum_{i=1}^{n-1} R_{i}\right) \\
&=\frac{1}{n}\left(R_{n}+(n-1) \frac{1}{n-1} \sum_{i=1}^{n-1} R_{i}\right) \\
&=\frac{1}{n}\left(R_{n}+(n-1) Q_{n}\right) \\
&=\frac{1}{n}\left(R_{n}+n Q_{n}-Q_{n}\right) \\
&=Q_{n}+\frac{1}{n}\left[R_{n}-Q_{n}\right]
\end{aligned}\]
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). 2018.
Csaba Szepesvári. Algorithms for Reinforcement Learning. 2009.
Course: UCL Reinforcement Learning Course (by David Silver)
Ⅳ Monte Carlo Methods的更多相关文章
- Introduction To Monte Carlo Methods
Introduction To Monte Carlo Methods I’m going to keep this tutorial light on math, because the goal ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- History of Monte Carlo Methods - Part 1
History of Monte Carlo Methods - Part 1 Some time ago in June 2013 I gave a lab tutorial on Monte Ca ...
- Monte Carlo methods
Monte Carlo methods https://zh.wikipedia.org/wiki/蒙地卡羅方法 通常蒙地卡羅方法可以粗略地分成两类:一类是所求解的问题本身具有内在的随机性,借助计算机 ...
- 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)
1. 蒙特卡罗方法的基本思想 蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法.该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基 ...
- PRML读书会第十一章 Sampling Methods(MCMC, Markov Chain Monte Carlo,细致平稳条件,Metropolis-Hastings,Gibbs Sampling,Slice Sampling,Hamiltonian MCMC)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:05:00 今天的主要内容:Markov Chain Monte Carlo,M ...
- (转)Markov Chain Monte Carlo
Nice R Code Punning code better since 2013 RSS Blog Archives Guides Modules About Markov Chain Monte ...
- 马尔科夫链蒙特卡洛(Markov chain Monte Carlo)
(学习这部分内容大约需要1.3小时) 摘要 马尔科夫链蒙特卡洛(Markov chain Monte Carlo, MCMC) 是一类近似采样算法. 它通过一条拥有稳态分布 \(p\) 的马尔科夫链对 ...
- 蒙特卡罗(Monte Carlo)方法简介
蒙特卡罗(Monte Carlo)方法,也称为计算机随机模拟方法,是一种基于"随机数"的计算方法. 二 解决问题的基本思路 Monte Carlo方法的基本思想很早以前就被人们所发 ...
随机推荐
- 基于DDD+微服务的开发实战(1)
1 DDD是什么? DDD是领域驱动设计,是Eric Evans于2003年提出的,离现在有17年. 2 为什么需要DDD 当软件越来越复杂,实际开发中,大量的业务逻辑堆积在一个巨型类中的例子屡见不鲜 ...
- 微信小程序入门到精通
微信小程序账号与工具 在线文档:https://mp.weixin.qq.com/debug/wxadoc/dev/ 小程序开发者账号注册 微信公众平台:https://mp.weixin.qq.co ...
- hystrix源码小贴士之之hystrix-metrics-event-stream
hystrix-metrics-event-stream主要提供了一些servlet,可以让用户通过http请求获取metrics信息. HystrixSampleSseServlet 继承了Http ...
- CVE-2018-8045
Joomla!Core SQL注入漏洞 CVE-2018-8045 受影响版本:joomla!3.5.0-3.8.5 漏洞描述: joomla!3.5.0-3.8.5版本对sql语句内的变量缺少类型转 ...
- 提效工具-python解析xmind文件及xmind用例统计
现状 每个公司都有一个维护测试case的系统,有自研的也有买的,比如QC, 禅道等等,QA往往习惯使用xmind等思维导图工具来编写测试用例,因为思路清晰,编写方便,那么这就有一个问题,大多公司要求所 ...
- 生命周期(初始化、销毁方法、BeanPostProcessor后处理Bean)
1.初始化和销毁 在目标方法执行前后进行初始化或销毁 (1)在Service方法的实现类里面创建初始化方法和销毁方法: public class StudentServiceImpl implemen ...
- CentOS7 【linux系统】配置 JDK 教程
1. 下载 [linux版本] JDK 1.8 的包. 2. 导入linux系统里面. 如何导入,下载一个winSCP 软件 破解安装,然后再linux 系统里面 查询IP,连接即可. 在linux解 ...
- Spring AOP系列(五)—反射
前言 前面我们进行了代理模式.静态代理.动态代理的学习.而动态代理就是利用Java的反射技术(Java Reflection),在运行时创建一个实现某些给定接口的新类(也称"动态代理类&qu ...
- 摄像头Sensor 图像格式
以0V7725为例: 顺便介绍一下0V7725的主要管脚,管脚定义能体现功能,体现使用方法.
- 文档生成工具——Doxygen
参考: 1.https://blog.csdn.net/liao20081228/article/details/77322584 2.https://blog.csdn.net/wang150619 ...