Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里
一、基础环境
1、环境版本
环境:centos7
hadoop版本:2.7.2
jdk版本:1.8
2、Hadoop目录结构
- bin目录:存放对Hadoop的HDFS,YARN服务进行操作的脚本
- etc目录:Hadoop的相关配置文件目录
- lib目录:存放Hadoop的本地库,提供数据压缩解压缩能力
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和相关案例
3、配置加载
vim /etc/profile
# 添加环境
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 退出刷新配置
source /etc/profile
二、伪集群配置
以下配置文件所在路径:/opt/hadoop2.7/etc/hadoop,这里是Linux环境,脚本配置sh格式。
1、配置hadoop-env
root# vim hadoop-env.sh
# 修改前
export JAVA_HOME=
# 修改后
export JAVA_HOME=/opt/jdk1.8
2、配置core-site
文件结构概览
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
</configuration>
NameNode的地址
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
数据存放目录:Hadoop运行时产生文件的存储目录。
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop2.7/data/tmp</value>
</property>
3、配置hdfs-site
文件结构和上述一样,配置hdfs副本个数,这里伪环境,配置1个即可。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4、配置yarn-env
export JAVA_HOME=/opt/jdk1.8
5、配置yarn-site
指定YARN的ResourceManager的地址
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.72.132</value>
</property>
指定map产生的中间结果传递给reduce采用的机制是shuffle
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6、配置mapred-env
export JAVA_HOME=/opt/jdk1.8
7、配置mapred-site
将mapred-site.xml.template重新命名为mapred-site.xml。
指定MapReduce程序资源调在度集群上运行。如果不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
三、环境启动测试
1、测试文件系统
Hdfs相关
格式化NameNode
第一次启动时执行该操作。
[hadoop2.7]# bin/hdfs namenode -format
格式化NameNode,会产生新的clusterID,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要停止相关进程,删除data数据和log日志,然后再格式化NameNode。clusterID在如下目录中的VERSION文件里,可自行查看对比。
/opt/hadoop2.7/data/tmp/dfs/name/current
/opt/hadoop2.7/data/tmp/dfs/data/current
启动NameNode
[hadoop2.7]# sbin/hadoop-daemon.sh start namenode
启动DataNode
[hadoop2.7]# sbin/hadoop-daemon.sh start datanode
jps查看状态
[root@localhost hadoop2.7]# jps
2450 Jps
2276 NameNode
2379 DataNode
Web界面查看
需要Linux关闭防火墙和相关安全增强控制(这里很重要)。
IP地址:50070

Yarn相关
启动ResourceManager
[hadoop2.7]# sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
[hadoop2.7]# sbin/yarn-daemon.sh start nodemanager
Web界面查看
IP地址:8088/cluster
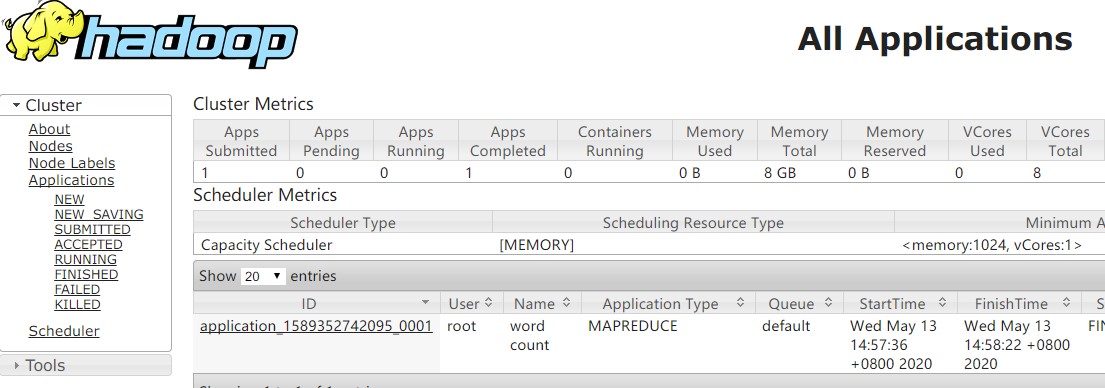
MapReduce相关
文件操作测试
创建一个测试文件目录
[root@localhost inputfile]# pwd
/opt/inputfile
[root@localhost inputfile]# echo "hello word hadoop" > word.txt
HDFS文件系统上创建文件夹
[hadoop2.7] bin/hdfs dfs -mkdir -p /opt/upfile/input
上传文件
[hadoop2.7]# bin/hdfs dfs -put /opt/inputfile/word.txt /opt/upfile/input
查看文件
[hadoop2.7]# bin/hdfs dfs -ls /opt/upfile/input
2、Web端查看文件
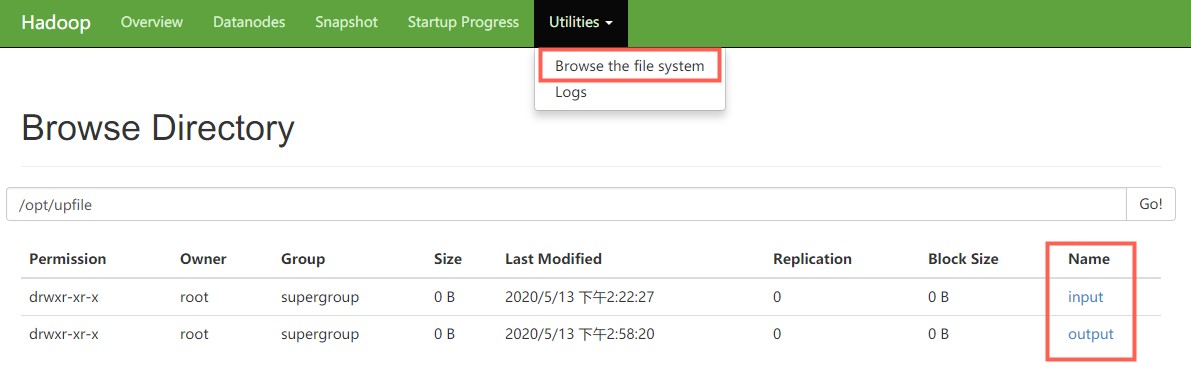
执行文件分析
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /opt/upfile/input /opt/upfile/output
查看分析结果
bin/hdfs dfs -cat /opt/upfile/output/*
结果:每个单词各自出现一次。
删除分析结果
bin/hdfs dfs -rm -r /opt/upfile/output
四、历史服务器
MapReduce的JobHistoryServer,这是一个独立的服务,可通过 web UI 展示历史作业日志。
1、修改mapred-site
<!-- 服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.72.132:10020</value>
</property>
<!-- 服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.72.132:19888</value>
</property>
2、启动服务
[hadoop2.7]# sbin/mr-jobhistory-daemon.sh start historyserver
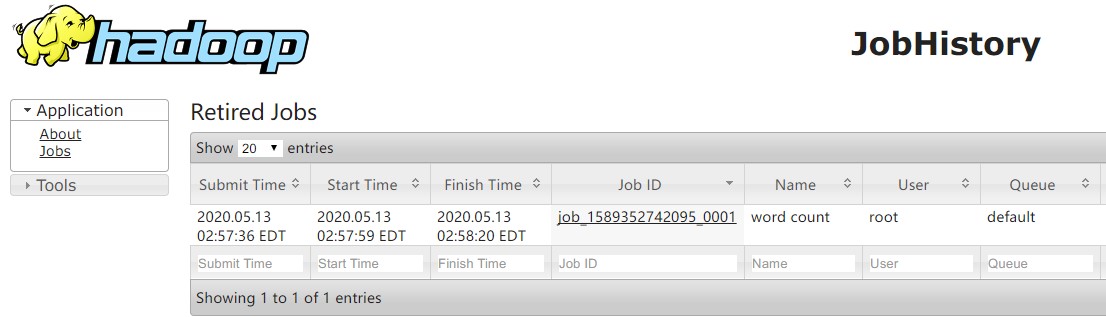
3、Web端查看
IP地址:19888
4、配置日志的聚集
日志聚集概念:应用服务运行完成以后,将运行日志信息上传到HDFS系统上。方便的查看到程序运行详情,方便开发调试。
开启日志聚集功能之后,需要重新启动NodeManager 、ResourceManager和HistoryManager。
关闭上述服务
[hadoop2.7]# sbin/yarn-daemon.sh stop resourcemanager
[hadoop2.7]# sbin/yarn-daemon.sh stop nodemanager
[hadoop2.7]# sbin/mr-jobhistory-daemon.sh stop historyserver
修改yarn-site
<!-- 日志聚集功开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
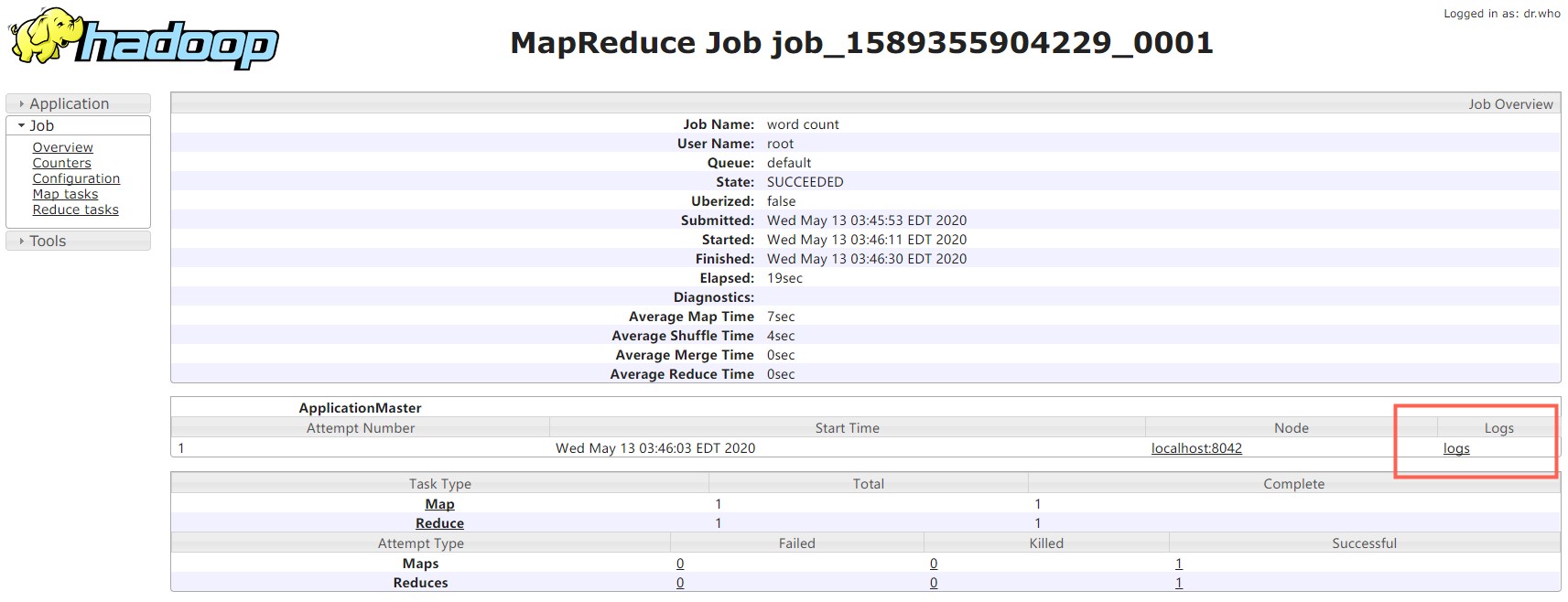
修改完之后再次启动上述服务器。再次执行文件分析任务。
查看Web端

五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent

Hadoop框架:单服务下伪分布式集群搭建的更多相关文章
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- zookeeper伪分布式集群搭建
zookeeper集群搭建注意点: 配置数据文件myid1/2/3对应server.1/2/3 通过zkCli.sh -server [ip]:[port]检测集群是否 ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- ZooKeeper的伪分布式集群搭建
ZooKeeper集群的一些基本概念 zookeeper集群搭建: zk集群,主从节点,心跳机制(选举模式) 配置数据文件 myid 1/2/3 对应 server.1/2/3 通过 zkCli.sh ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
随机推荐
- 2.MongoDB 4.2副本集环境基于时间点的恢复
(一)MongoDB恢复概述 对于任何数据库,如果要将数据库恢复到过去的任意时间点,否需要有过去某个时间点的全备+全备之后的重做日志. 接下来根据瑞丽航空的情况进行概述: 全备:每天晚上都会进行备份: ...
- oracle创建用户操作
打开命令提示框输入以下内容 1.输入:sqlplus /nolog //进入oralce控制台2.输入:conn /as sysdba //以管理员权限登录3.输入:create user abc i ...
- 数据结构-二叉树(6)哈夫曼树(Huffman树)/最优二叉树
树的路径长度是从树根到每一个结点的路径长度(经过的边数)之和. n个结点的一般二叉树,为完全二叉树时取最小路径长度PL=0+1+1+2+2+2+2+… 带权路径长度=根结点到任意结点的路径长度*该结点 ...
- 如何运用excel或spss等软件统计大量纸质问卷?
在用纸质问卷进行数据收集时,总是避不开一个问题,就是如何把数据快速准确的进行统计分析.这里提供一个方法,包括以下几个步骤: 一.录入数据 二.上传数据 三.分析数据 一.录入数据 首先把纸质问卷 ...
- Tensorflow2(二)tf.data输入模块
代码和其他资料在 github 一.tf.data模块 数据分割 import tensorflow as tf dataset = tf.data.Dataset.from_tensor_slice ...
- PowerJob 在线日志饱受好评的秘诀:小但实用的分布式日志系统
本文适合有 Java 基础知识的人群 作者:HelloGitHub-Salieri HelloGitHub 推出的<讲解开源项目>系列. 项目地址: https://github.com/ ...
- jQuery源码分析系列(二)Sizzle选择器引擎-上
前言 我们继续从init()方法中的find()方法往下看, jQuery.find = Sizzle; ... find: function (selector) { /** ... */ ret ...
- 洛谷P1080 国王游戏 python解法 - 高精 贪心 排序
洛谷的题目实在是裹脚布 还编的像童话 这题要 "使得获得奖赏最多的大臣,所获奖赏尽可能的少." 看了半天都觉得不像人话 总算理解后 简单说题目的意思就是 根据既定的运算规则 如何排 ...
- go语言开发入门
go语言开发入门 每个Go程序包含一个名为main的包以及其main函数,在初始化后,程序从main开始执行,避免引入不使用的包(编译不通过) 基础语法 基本数据类型 bool, byte int,i ...
- A Walk Through the Forest (最短路+记忆化搜索)
Jimmy experiences a lot of stress at work these days, especially since his accident made working dif ...