数据源管理 | 搜索引擎框架,ElasticSearch集群模式
本文源码:GitHub·点这里 || GitEE·点这里
一、集群环境搭建
1、环境概览
ES版本6.3.2,集群名称esmaster,虚拟机centos7。
| 服务群 | 角色划分 | 说明 |
|---|---|---|
| en-master | master | 主节点:esnode1 |
| en-node01 | slave | 从节点:esnode2 |
| en-node02 | slave | 从节点:esnode3 |
ElasticSearch基础功能和用法:
在真正海量数据的业务场景中,ElasticSearch搜索引擎都是需要集群化管理的,实时搜素几十亿的数据十分常见。
2、集群配置
配置文件
vim /opt/elasticsearch-6.3.2/config/elasticsearch.yml
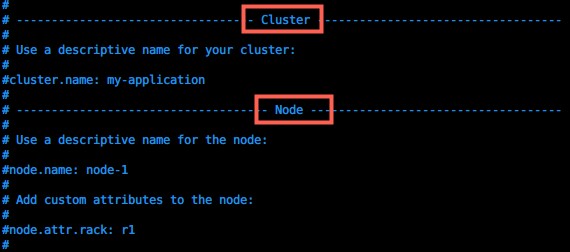
主节点配置
# 集群主节点配置
cluster.name: esmaster
node.master: true
# 节点名称
node.name: esnode1
# 开发访问
network.host: 0.0.0.0
从节点配置
注意这里两个从节点配置,node.name分别配置为esnode2和esnode3即可。
# 集群名称
cluster.name: esmaster
# 节点名称
node.name: esnode2
# 开发访问
network.host: 0.0.0.0
# 主节点IP
discovery.zen.ping.unicast.hosts: ["192.168.72.133"]
内存权限
vim /etc/sysctl.conf
# 添加内容
vm.max_map_count=262144
# 执行
sysctl -p
3、集群启动
添加esroot用户,并授权。
/opt/elasticsearch-6.3.2/bin/elasticsearch
单服务查看
ps -aux |grep elasticsearch
集群状态查看
http://localhost:9200/_cluster/health?pretty
{
"cluster_name" : "esmaster", # 集群名称
"status" : "green", # 绿:健康,黄:亚健康,红:病态
"timed_out" : false, # 是否超时
"number_of_nodes" : 3, # 节点个数
}
二、集群模式测试
1、环境配置
dev环境
配置单个节点,选择任意单节点,进行数据写入测试。
spring:
data:
elasticsearch:
# 集群名称
cluster-name: esmaster
# 单节点
# cluster-nodes: en-master:9300
# cluster-nodes: en-node01:9300
cluster-nodes: en-node02:9300
test环境
链接集群环境,进行数据读取测试。
spring:
data:
elasticsearch:
# 集群名称
cluster-name: esmaster
# 集群节点
cluster-nodes: en-master:9300,en-node01:9300,en-node02:9300
当然所有的操作都可以基于单节点或者集群环境测试。
2、实例对象
基于注解管理数据对象实例。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Document(indexName = "usersearchindex",type = "usersearch")
public class UserSearch {
//Id注解Elasticsearch里相应于该列就是主键,查询时可以使用主键查询
@Id
private Long id;
private String userId;
private String userName;
private String sex;
}
3、操作案例
提供一个数据查询操作和数据写入操作。
import com.esearch.cluster.entity.UserSearch;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class UserSearchServiceImpl implements UserSearchService {
@Resource
private UserSearchRepository userSearchRepository ;
@Override
public String esInsert(Integer num) {
for (int i = 0 ; i < num ; i++){
UserSearch userSearch = new UserSearch() ;
userSearch.setId(System.currentTimeMillis());
userSearch.setUserId("Name"+i);
userSearch.setUserName("ZSan"+i);
userSearch.setSex("Male"+i);
userSearchRepository.save(userSearch) ;
}
return "success" ;
}
@Override
public Iterable<UserSearch> esFindAll (){
return userSearchRepository.findAll() ;
}
}
三、集群控制台
这里是基于Kibana组件做的集群控制台。
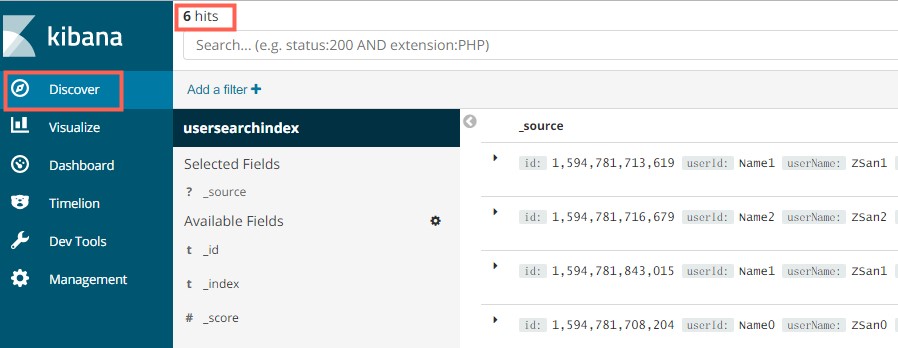
1、数据列表
在discover面板中可以查看列表数据,也可以继续搜索。
列表查询
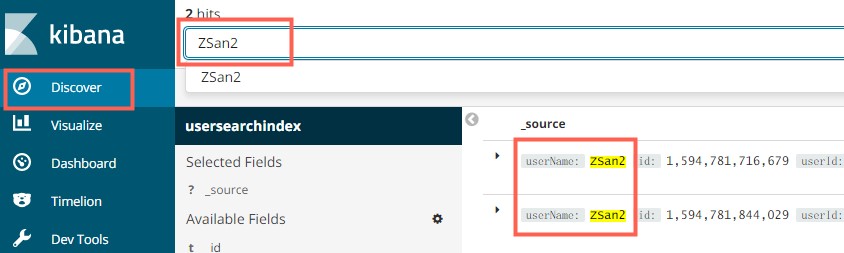
列表搜索
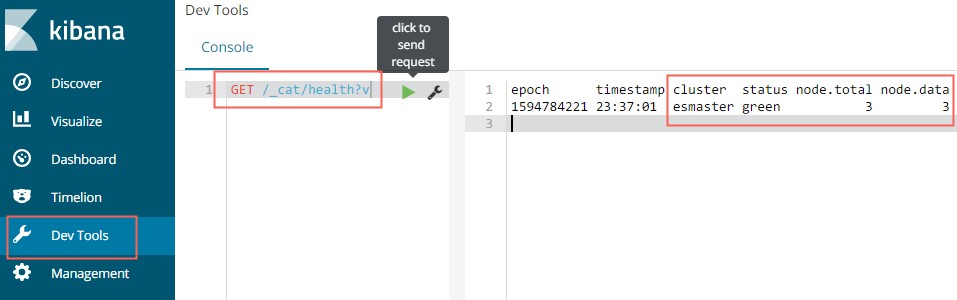
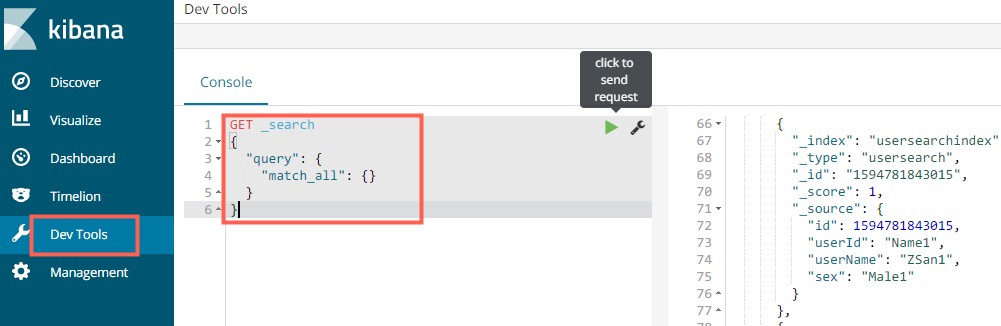
2、开发工具
在dev_tools面板中可以执行ElasticSearch相关命令。
查看集群健康状态
GET /_cat/health?v
查询全部数据
GET _search
{
"query": {
"match_all": {}
}
}
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐阅读:数据源管理系列
数据源管理 | 搜索引擎框架,ElasticSearch集群模式的更多相关文章
- Hadoop框架:集群模式下分布式环境搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境配置 1.三台服务 准备三台Centos7服务,基础环境从伪分布式环境克隆过来. 133 hop01,134 hop02,136 ...
- 使用Elasticsearch Operator快速部署Elasticsearch集群
转载自:https://www.qikqiak.com/post/elastic-cloud-on-k8s/ 随着 kubernetes 的快速发展,很多应用都在往 kubernetes 上面迁移,现 ...
- 升级 Elasticsearch 集群数量实战记录
搜索引擎 升级 Elasticsearch 集群数量实战记录 现在线上有一个elasticsearch集群搜索服务有三台elasticsearch实例(es1.es2.es3),打算将其升级为5台(增 ...
- 日志分析平台ELK之搜索引擎Elasticsearch集群
一.简介 什么是ELK?ELK是Elasticsearch.Logstash.Kibana这三个软件的首字母缩写:其中elasticsearch是用来做数据的存储和搜索的搜索引擎:logstash是数 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Elasticsearch集群 管理
第7章 深入Elasticsearch集群 启动一个Elasticsearch节点时,该节点会开始寻找具有相同集群名字并且可见的主节点.如 果找到主节点,该节点加入一个已经组成了的集群:如果没有找到, ...
- 微服务管理平台nacos虚拟ip负载均衡集群模式搭建
一.Nacos简介 Nacos是用于微服务管理的平台,其核心功能是服务注册与发现.服务配置管理. Nacos作为服务注册发现组件,可以替换Spring Cloud应用中传统的服务注册于发现组件,如:E ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- Spark集群模式概述
作者:foreyou出处:http://www.foreyou.net/2015/06/22/spark-cluster-mode-overview/声明:本文采用以下协议进行授权: 署名-非商用|C ...
随机推荐
- git安装和第一次提交过程
1,新建文件夹test,运行命令 git init 2,找到test的.git文件夹,打开之后找到config文件,在最后边加上一句话 [user] email=your email name=you ...
- SpringMVC框架搭建流程(完整详细版)
SpringMVC框架搭建流程 开发过程 1)配置DispatcherServlet前端控制器 2)开发处理具体业务逻辑的Handler(@Controller. @RequestMapping) 3 ...
- 单数据盘或者很多数据盘mount挂载到某个目录
单数据盘挂载背景 /dev/sda盘挂载到/opt/data2,此目录有数据,且postgres进程在写入该目录 单数据盘挂载操作方法 1)查看/opt/data2 目录下有哪些文件 #ls /opt ...
- Loadrunner12将fiddler跟踪文件转为脚本的后续处理事项
之前一篇文章说过,Loadrunner12是支持将fiddler的跟踪文件.SAZ直接转成LR的脚本的,好多小伙伴都用了这个方法,但是生成脚本后用LR11运行的时候就出问题了,会发现runtime-s ...
- Laravel:No application encryption key has been specified.
其实吧,这个就是你没有生成密钥 你首先去看看,如果是刚刚下载的lavavel应该会有一个.env.example文件在根目录下,然后修改这个文件名,改成.env 然后用命令行去执行php artisa ...
- c++. Run-Time Check Failure #2 - Stack around the variable 'cc' was corrupted.
Run-Time Check Failure #2 - Stack around the variable 'cc' was corrupted. char cc[1024]; //此处如果索引值 ...
- spring框架中JDK和CGLIB动态代理区别
转载:https://blog.csdn.net/yhl_jxy/article/details/80635012 前言JDK动态代理实现原理(jdk8):https://blog.csdn.net/ ...
- TestNG配合ant脚本进行单元测试
上面就是一个简单的SSM框架的整合,数据库来自宜立方商城的e3-mall采用一个简单的spring-mvc和spring以及mybatis的整合 单元测试代码为 TestUserByTestNG.ja ...
- SqlServer2016 startengine错误的解决方式整理
因为某些需要,最近在安装SqlServer2016,但总是安装失败,按照网上各路大佬的解决方案都没有成功.报错提示为两个:无法获取数据库引擎句柄,无法恢复数据库引擎服务.按照网上做法,使用admini ...
- Pytest 单元测试框架标记用例
1.Pytest 中标记用例 接参数 -k 来挑选要执行的测试项 pytest -k test_szdcs -s test_szdcs 为函数名称 -k 后面接的名称可以为函数名称.类名称.文件名称. ...