Redisearch实现的全文检索功能服务
“检索”是很多产品中无法绕开的一个功能模块,当数据量小的时候可以使用模糊查询等操作凑合一下,但是当面临海量数据和高并发的时候,业界常用 elasticsearch 和 lucene 等方案,但是elasticsearch对运行时内存有着最低限额,其运行时大小推荐 2G 以上的内存空间,并且需要额外的磁盘空间做持久化存储。
其实mongoDB 内置的正则匹配搜索文本以及自带的 text 索引和 search 关键字也是一套靠谱的解决方案,但是这一次我们带来一种更加高效经济的文本检索方案:Redisearch
Redis Modules 是 redis 4.0 引入的一种扩展机制,用户可以通过实现 redis module 提供的 C api 接口为 redis 服务添加定制化功能。 redisLab 也希望籍此来规范 redis 社区的 ecosystem 实现。
redis module 本身的版本独立于redis,并且以编译成动态加载库 .so 文件的方式 release, 不同版本的 redis 可以 load 同一版本 module.so 文件。
redis 提供了两种加载方式。可以通过 在 conf 文件中 加入 loadmodule /path/to/mymodule.so ,也可以在 redis-cli中使用命令 MODULE LOAD /path/to/panda.so 动态加载,MODULE UNLOAD 卸载。
特性
基于文档的全文索引。
高性能增量索引。
支持文档评分,文档字段(field) 权重机制。
支持布尔复杂查询。
支持自动补全。
基于 snowball 的词干分析,多语言支持。使用 friso 支持中文分词。
utf-8 字符集支持。
redis 数据持久化支持。
自定义评分机制。
其原理是在 redis 的 hashmap 基础上就可以很容易实现倒排索引的结构。redisearch 倒排索引除了实现了基础功能外,还引入了内存管理等优化功能。如果有兴趣可以阅读源码中的 src/inverted_index.c 部分
首先,安装Rediseach,记住一点你本地的redis服务版本必须在4.0以上,网上一大堆编译安装的攻略,繁琐又浪费时间,所以又到了Docker登场时间了,hub上有编译好的免费镜像供我们下载
1,安装redis
#下载rpm源并安装
yum install -y http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
#安装redis
yum --enablerepo=remi install -y redis
#启动redis服务
service redis start
2,安装Rediseach
docker pull redislabs/redisearch
下载后,直接在后台启动服务
docker run -d -p 6666:6379 redislabs/redisearch:latest

此时已经有一个docker容器在后台启动了,redis服务映射到了宿主的6666端口,我们来连接一下
redis-cli -h localhost -p 6666

检查 modules 是否成功加载
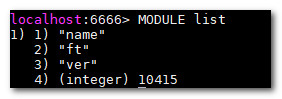
如果返回数组中存在 "ft" , 则表明 redisearch 已经成功加载。
Redisearch 的索引概念 与elasticsearch 的 index 类似,表示某一类文档资源单元。
这里我们定义了一个 SMARTX_VM 索引,其中存储的文档 包含 了 title 和 desc 两个 类型为 TEXT 的field。
FT.CREATE SMARTX_VM SCHEMA title TEXT WEIGHT 5.0 desc TEXT
然后向刚刚创建的这条索引加一个文档
FT.ADD SMARTX_VM vm-20190901 1.0 LANGUAGE "chinese" FIELDS title "中国" desc "我是中国人"
LANGUAGE "chinese" 参数 表示 使用 中文分词器 处理文本。默认为英文
此时我们进行文档检索
FT.SEARCH SMARTX_VM "中国" LANGUAGE "chinese"
注意检索的时候也要指定语言,这里我们用中文分词,默认的英文分词是无法检索中文的
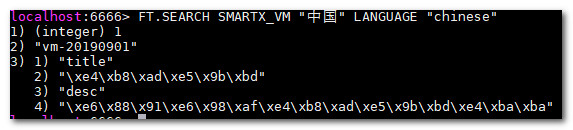
可以看到已经返回了我们想要的结果。
Redisearch 是一个高效,功能完备的内存存储的高性能全文检索组件, 十分适合应用在数据量适中, 内存和存储空间有限的环境。借助数据同步手段,我们可以很方便的将redisearch 结合到现有的数据存储中, 进而向产品提供 全文检索, 自动补全等服务优化功能。
Redisearch实现的全文检索功能服务的更多相关文章
- 使用Python3.7结合Redisearch代替ElasticSearch实现的全文检索功能服务
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_105 "检索"是很多产品中无法绕开的一个功能模块,当数据量小的时候可以使用模糊查询等操作凑合一下,但是当面临海 ...
- 使用Lucene对doc、docx、pdf、txt文档进行全文检索功能的实现
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/76273859 本文出自[我是干勾鱼的博客] 这里讲一下使用Lucene对doc. ...
- Bing Maps进阶系列四:路由功能服务(RouteService)
Bing Maps进阶系列四:路由功能服务(RouteService) Bing Maps提供的路由功能服务(RouteService)可以实现多方位的计算地图上的路线指示,路径行程等功能,比如说实现 ...
- 在ef core中使用postgres数据库的全文检索功能实战
起源 之前做的很多项目都使用solr/elasticsearch作为全文检索引擎,它们功能全面而强大,但是对于较小的项目而言,构建和维护成本显然过高,尤其是从关系数据库/文档数据库到全文检索引擎的数据 ...
- sphinx全文检索功能 | windows下测试 (一)
前一阵子尝试使用了一下Sphinx,一个能够被各种语言(PHP/Python/Ruby/etc)方便调用的全文检索系统.网上的资料大多是在linux环境下的安装使用,当然,作为生产环境很有必要部署在* ...
- 服务链(Service Chaining,or Service Function Chaining,SFC,功能服务链)
Software-configured service chaining provides the capability to dynamically include best-of-b ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- 【搜索引擎】Solr Suggester 实现全文检索功能-分词和和自动提示
功能需求 全文检索搜索引擎都会有这样一个功能:输入一个字符便自动提示出可选的短语: 要实现这种功能,可以利用solr的SuggestComponent,SuggestComponent这种方法利用Lu ...
- 全文检索ES 服务启动和关闭
nohup ./elasticsearch & 可以后台开启elasticsearch服务 ps-ef列出所有进程 ps-ef | grep elastic...查找elastic..的进程 ...
随机推荐
- JSX中写 switch case 进行判断
场景:根据后端返回的数据进行多条件渲染,三元表达式已不能满足条件. 代码: <span> {(() => { switch (record.generalRuleInfos[0]?. ...
- Linux 学习笔记04丨Linux的用户和用户组管理
Chapter 3. 用户和用户组管理 由于Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以该账号身份进入系统. 3.0 用户与 ...
- 深入浅出之mysql索引--上
当着小萌新之际,最近工作中遇到了mysql优化的相关问题,然后既然提到了优化,很多像我这样的小萌新不容置喙,肯定张口就是 建立索引 之类的. 那么说到底,索引到底是什么,它是怎么工作的?接下来就让我和 ...
- 【不尽如人意的redisTemplete封装】
线下项目里对spring redisTemplete进行了简单的封装,但是项目里关于其序列化的配置真的有点一言难尽: 可以看到这里用了JdkSerializationRedisSerializer去对 ...
- MindSpore手写数字识别初体验,深度学习也没那么神秘嘛
摘要:想了解深度学习却又无从下手,不如从手写数字识别模型训练开始吧! 深度学习作为机器学习分支之一,应用日益广泛.语音识别.自动机器翻译.即时视觉翻译.刷脸支付.人脸考勤--不知不觉,深度学习已经渗入 ...
- VS Code C++ 项目快速配置模板
两个月前我写过一篇博客 Windows VS Code 配置 C/C++ 开发环境 ,主要介绍了在 VS Code 里跑简单 C 程序的一些方法.不过那篇文章里介绍的方法仅适用于单文件程序,所以稍微大 ...
- 「刷题笔记」DP优化-状压-EX
棋盘 需要注意的几点: 题面编号都是从0开始的,所以第1行实际指的是中间那行 对\(2^{32}\)取模,其实就是\(unsigned\ int\),直接自然溢出啥事没有 棋子攻击范围不会旋转 首先, ...
- Nebula Flink Connector 的原理和实践
摘要:本文所介绍 Nebula Graph 连接器 Nebula Flink Connector,采用类似 Flink 提供的 Flink Connector 形式,支持 Flink 读写分布式图数据 ...
- 小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复'CRR-FMM',即可获得电子资源. 1 Introduction In this short communication, we prese ...
- 第11.18节 Python 中re模块的匹配对象
匹配对象是Python中re模块正则表达式匹配处理的返回结果,用于存放匹配的情况.老猿认为匹配对象更多的应该是与组匹配模式的功能对应的,只是没有使用组匹配模式的正则表达式整体作为组0. 为了说明下面的 ...